Enhancing Search Engine Efficiency With Elasticsearch Aliases
In this article, the reader will learn more about optimizing search performance and scalability with alias-based index management.
Join the DZone community and get the full member experience.
Join For FreeElasticsearch is renowned for its robust search capabilities, making it a popular choice for building high-performance search engines. One of the key features that contribute to its efficiency is the use of aliases. Elasticsearch aliases provide a powerful mechanism for optimizing search operations, improving query performance, and enabling dynamic index management. In today's digital world, a vast amount of data is being generated in various formats and types. As global customers spend more time searching for relevant items, comparing features, and seeking ways to narrow down their search options, the need for highly intelligent search engines becomes crucial. This article will discuss the topic of building a powerful search engine using Elasticsearch. It focuses on investigating the advanced searching techniques employed by Elasticsearch, providing a comprehensive overview of its architecture and fundamental concepts. The article explores a range of searching techniques, including query DSL, relevance scoring, filtering, and aggregations. Furthermore will explore more advanced features such as multi-field querying and geospatial search. To optimize the search performance of Elasticsearch, the article also discusses optimization strategies and best practices. By the end, readers will gain valuable insights into building efficient and high-performing search engines using Elasticsearch.
Introduction
In today's digital era, the generation of diverse data in various formats has become ubiquitous. As a result, global customers are spending more time searching for relevant items, comparing features, and seeking ways to narrow down their search options. Meeting these evolving customer requirements necessitates the development of highly intelligent search engines that can efficiently fulfill their needs. One such powerful search engine is Elasticsearch. Elasticsearch is a distributed, scalable, and fault-tolerant search and analytics engine that provides robust search capabilities for a wide range of applications. With its versatile architecture and indexing techniques, Elasticsearch enables efficient storage, indexing, and retrieval of large volumes of data across multiple nodes. Its advanced search capabilities, such as full-text search, relevance scoring, and filtering techniques, ensure accurate and comprehensive search results.
However, in today's competitive digital landscape, simply retrieving search results based on text matching may not suffice. Customers expect highly relevant recommendations that go beyond recency and take into account their specific preferences and behaviors. To address this demand, integrating machine learning techniques into Elasticsearch's search mechanisms can significantly enhance the relevance of search results. This research project focuses on developing a scalable Elasticsearch searching system that seamlessly integrates data from different sources. The system aims to utilize machine learning techniques to fetch highly relevant items, taking into consideration customer preferences, historical data, and other relevant factors. By combining the strengths of Elasticsearch's efficient search capabilities and machine learning algorithms, the search engine can provide customers with personalized and accurate recommendations, thereby enhancing their overall search experience. With the integration of machine learning, the search engine becomes more intelligent, adapting to users' preferences and dynamically improving the relevance of search results over time. By analyzing user behavior, patterns, and historical data, the system can learn and understand individual preferences, making personalized recommendations that align with each user's specific needs.
Elasticsearch Architecture
Elasticsearch is designed as a distributed, scalable, and fault-tolerant search and analytics engine. Its architecture enables efficient storage, indexing, and retrieval of large volumes of data across multiple nodes. Understanding the key components and concepts of Elasticsearch's architecture is crucial for effectively utilizing its capabilities. The following provides an overview of Elasticsearch's architecture:
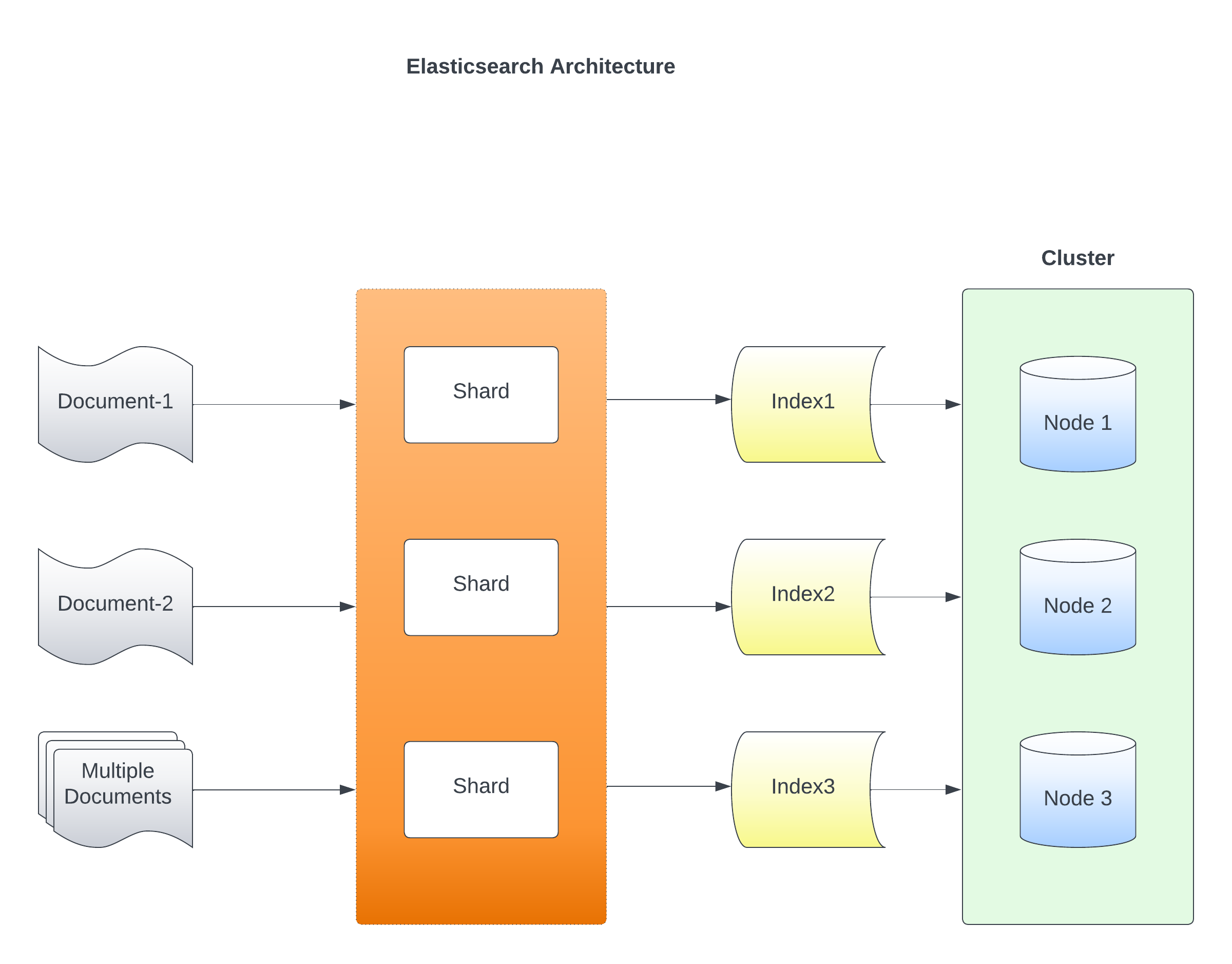
Cluster: At the highest level, Elasticsearch operates within a cluster. A cluster is a collection of one or more nodes that work together to store and process data. Each cluster has a unique name that identifies it.
Node: A node is an individual server or a virtual machine that participates in the cluster. Nodes are responsible for storing data, performing indexing and searching operations, and serving client requests. Each node in the cluster is assigned a unique name for identification.
Index: An index is a logical namespace that represents a collection of documents with similar characteristics. It is analogous to a database in traditional relational databases. For example, an index could represent customer data, product information, or log entries. Elasticsearch allows the creation of multiple indexes within a cluster.
Shard: An index can be divided into multiple shards, which are smaller units of data storage and processing. Sharding allows data to be distributed across multiple nodes, enabling parallel processing and improving performance. Each shard is considered a separate and independent index with its own set of documents.
Replica: Replicas are copies of shards within an index. Elasticsearch automatically creates replicas to ensure high availability and fault tolerance. Replicas provide redundancy, allowing for data retrieval and processing even if a primary shard or node fails. Replicas can also improve search performance by distributing the search load across multiple nodes.
Document: A document is the basic unit of information in Elasticsearch. It is represented as a JSON object and contains fields with corresponding values. Documents are stored and indexed within an index, and Elasticsearch provides powerful search capabilities to retrieve and analyze documents based on their fields.
Mapping: A mapping defines the structure and characteristics of fields within a document. It specifies the data type of each field, including text, numeric, date, and more. Mapping allows Elasticsearch to understand and index the data appropriately, facilitating efficient search and retrieval operations.
Inverted Index: Elasticsearch uses an inverted index structure to enable fast full-text search. An inverted index is a data structure that maps terms to the documents in which they appear. It allows for efficient retrieval of documents containing specific terms, making Elasticsearch highly performant for text-based searches.
Distributed and Scalable Architecture: Elasticsearch's architecture is designed to scale horizontally. Data is distributed across multiple nodes, and each node can handle indexing, searching, and serving requests independently. This distributed nature allows Elasticsearch to handle large amounts of data and high query loads while providing fault tolerance and resilience.
Communication and Coordination: Nodes within an Elasticsearch cluster communicate and coordinate with each other using the Java-based Transport protocol. This allows for efficient data transfer, cluster coordination, and node discovery. Elasticsearch also provides RESTful APIs that allow clients to interact with the cluster for indexing, searching, and administration tasks.
What Are Aliases?
Aliases in Elasticsearch are secondary names or labels associated with one or more indexes. They act as a pointer or reference to the actual index, allowing you to interact with the index using multiple names. An alias abstracts the underlying index name, providing flexibility and decoupling between applications and indexes.
Benefits of Using Aliases in Elasticsearch
Aliases in Elasticsearch provide a range of benefits that enhance index management, deployment strategies, search efficiency, and data organization. Let's explore the advantages of using aliases in more detail:
- Index Abstraction: Aliases allow the abstract of the underlying index names by using user-defined names. This abstraction shields the application from changes in index names, making it easier to switch or update indexes without modifying the application code. By using aliases, the application can refer to indexes using consistent, meaningful names that remain unchanged even when the underlying index changes.
- Index Management: Aliases simplify index management tasks. When creating a new index or replacing an existing one, it can update the alias to point to the new index. This approach enables seamless transitions and reduces the impact on application configurations. Instead of updating the application code with new index names, it only needs to modify the alias, making index updates more manageable and less error-prone.
- Blue-Green Deployments: Aliases are particularly useful in blue-green deployment strategies. In such strategies, it maintains two sets of indexes: the "blue" set represents the current production version, while the "green" set represents the new version being deployed. By assigning aliases to different versions of indexes, it can seamlessly switch traffic from the old version to the new version by updating the alias. This process ensures zero downtime during deployments and enables easy rollback if necessary.
- Index Rollover: Elasticsearch's index rollover feature allows it to automatically create new indexes based on defined criteria, such as size or time. Aliases can be used to consistently reference the latest active index, simplifying queries and eliminating the need to update index names in the application. With aliases, it can query the alias instead of referencing specific index names, ensuring that the application always works with the latest data without requiring manual intervention.
- Data Partitioning: Aliases enable efficient data partitioning across multiple indexes based on specific criteria by associating aliases with subsets of indexes that share common characteristics, such as time ranges or categories, which can narrow down the search space and improve search performance. For example, it can create aliases that include only documents from a specific time range, allowing it to search or aggregate data within that partition more efficiently.
- Filtering and Routing: Aliases can be associated with filters or routing values, providing additional flexibility in search operations. By defining filters within aliases, it can perform searches or aggregations on subsets of documents that match specific criteria. This enables to focus search operations on relevant subsets of data, improving search efficiency and reducing unnecessary data processing. Similarly, routing values associated with aliases allow direct search queries to specific indexes based on predefined rules, further optimizing search performance.
Scenario
To better understand aliases in action, let's consider a practical example of an e-commerce platform that handles product data and uses a search microservice for searching product information. The platform maintains an index named "index1" to store product information, as shown in Figure 1. Now, let's assume we want to introduce versioning, which involves indexing new product information to make it available for customer searches. The goal is to seamlessly transition to the new version without any disruptions to the application.
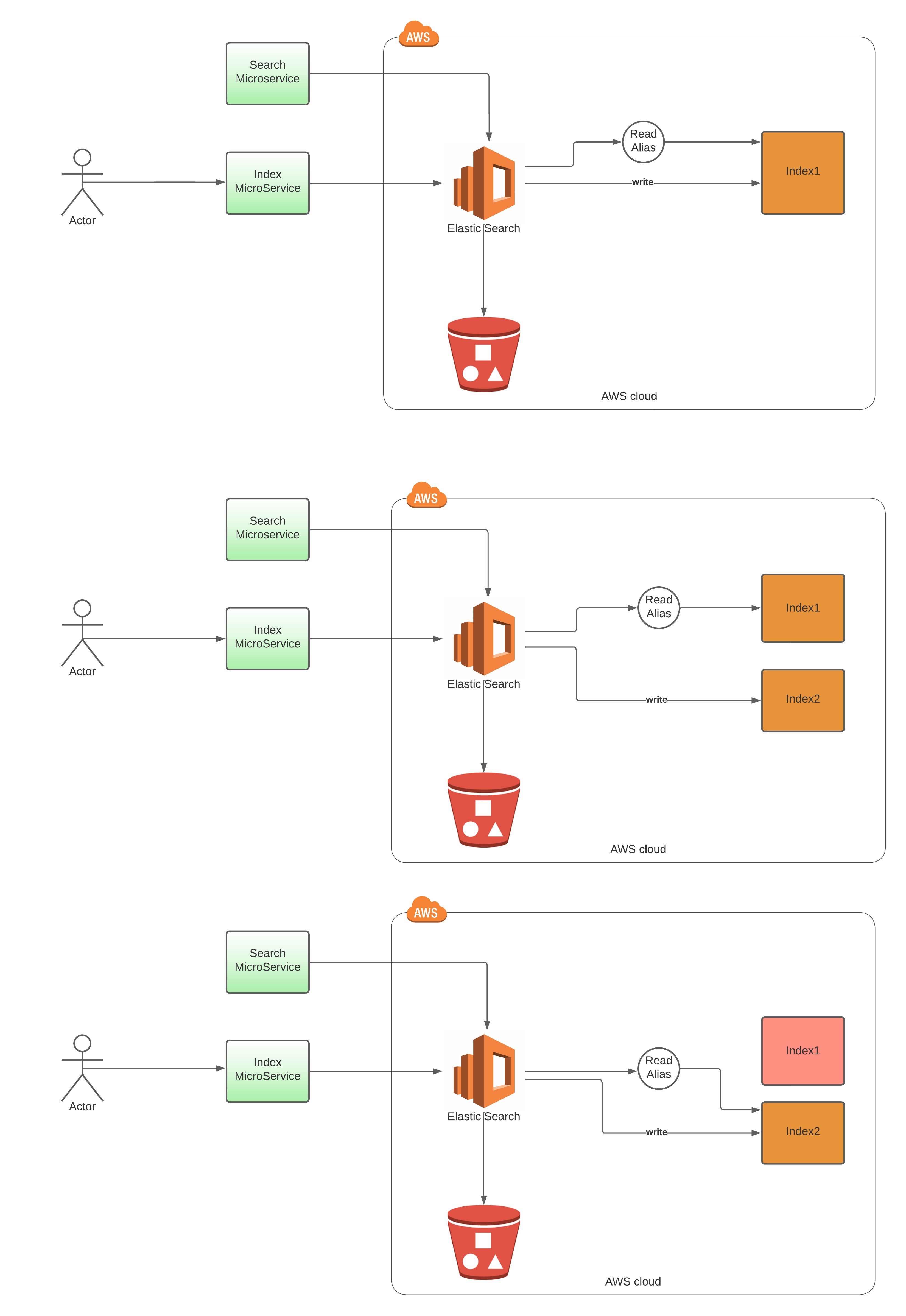
Figure 1: Swapping of Alias between the indexes
Step 1: Initial Index Setup
The e-commerce platform begins with an index named "index1," which holds the existing product data.
Step 2: Creating an Alias
To ensure a smooth transition, the platform creates an alias called "readAlias" and associates it with the "index1" index. This alias acts as the primary reference point for the application, abstracting the underlying index name.
Step 3: Introducing a New Index Version
To accommodate updates and modifications, a new version of the index, "index2," is created. This new version will store the updated product information. While the search application, upon running and reads the data from Index1 through readAlias.
Step 4: Updating the Alias
To seamlessly switch to the new index version, the platform updates the alias "readAlias" to point to the "index2" index. This change ensures that the application can interact with the new index without requiring any modifications to the existing codebase.
Step 5: Dropping the Older Index
Once the alias is successfully updated, the platform can safely drop the older index, "index1," as it is no longer actively used.
By updating the alias, the application can seamlessly interact with the new index without any code modifications. Additionally, it can employ filtering or routing techniques through aliases to perform specific operations on subsets of products based on categories, availability, or other criteria.
Create an Alias in Elasticsearch Using the Elasticsearch Rest API
PUT /_aliases
{
"actions": [
{
"add": {
"index": "index1",
"alias": "readAlias"
}
}
]
}Updating the Alias and Dropping the Older Index
To switch the alias to the new index version and drop the older index, we can perform multiple actions within a single _aliases operation. The following command removes "index1" from the "readAlias" alias and adds "index2" to it:
POST _aliases
{
"actions": [
{
"remove": {
"index": "index1",
"alias": "readAlias"
}
},
{
"add": {
"index": "index2",
"alias": " readAlias"
}
}
]
}With these operations, the alias "readAlias" now points to the "index2" version, effectively transitioning to the new product data.
Elasticsearch Aliases in a Spring Boot Application
To use Elasticsearch aliases in a Spring Boot application, first, configure the Elasticsearch connection properties. Then, create an Elasticsearch entity class and annotate it with mapping annotations. Next, define a repository interface that extends the appropriate Spring Data Elasticsearch interface. Programmatically create aliases using the ElasticsearchOperations bean and AliasActions. Finally, perform search and CRUD operations using the alias by invoking methods from the repository interface. With these steps, you can seamlessly utilize Elasticsearch aliases in the Spring Boot application, improving index management and search functionality.
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, String> {
@Autowired
private ElasticsearchOperations elasticsearchOperations;
@PostConstruct
public void createAliases() {
String indexV1 = "index1";
String indexV2 = "index2";
IndexCoordinates indexCoordinatesV1 = IndexCoordinates.of(indexV1);
IndexCoordinates indexCoordinatesV2 = IndexCoordinates.of(indexV2);
AliasActions aliasActions = new AliasActions();
// Creating an alias for indexV1
aliasActions.add(
AliasAction.add()
.alias("readAlias")
.index(indexCoordinatesV1.getIndexName())
);
// Creating an alias for indexV2
aliasActions.add(
AliasAction.add()
.alias("readAlias")
.index(indexCoordinatesV2.getIndexName())
);
// Applying the alias actions
elasticsearchOperations.indexOps(Product.class).aliases(aliasActions);
}
}
In this example, the createAliases() method is annotated with @PostConstruct, ensuring that the aliases are created when the application starts up. It uses the AliasActions class to define the alias actions, including adding the alias "readAlias" for both "index1" and "index2" indexes.
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public List<Product> searchProducts(String query) {
return productRepository.findByName(query);
}
// Other service methods for CRUD operations
}
In the ProductService class, we can invoke methods from the ProductRepository to perform search operations based on the "readAlias" alias. The Spring Data Elasticsearch repository will route the queries to the appropriate index based on the alias configuration.
Basic Searching Techniques in Elasticsearch
Searching is a fundamental aspect of Elasticsearch, a powerful distributed search and analytics engine. Elasticsearch provides a wide range of features and capabilities to perform efficient and flexible searches. Let's explore the fundamentals of searching in Elasticsearch:
1. Indexing Documents: Before searching, data needs to be indexed in Elasticsearch. Documents are grouped into indexes, which are logical containers for data. Each document has a unique ID and is represented in JSON format. Indexing involves storing documents in Elasticsearch, making them searchable.
2. Query DSL (Domain-Specific Language): Elasticsearch offers a comprehensive Query DSL, which is a JSON-based language used to construct search queries. The Query DSL provides various query types to match documents based on different criteria, including full-text search, exact match, range queries, and more. You can combine multiple query types using logical operators to build complex search queries.
Example:
- Match Query: The
matchquery is used for full-text search. It analyzes the query string, tokenizes it, and matches documents that contain any of the terms. Example:
{
"match": {
"title": "Software Architecture"
}
}
ii. Term Query: The term query matches documents that have an exact term in a specific field. It doesn't analyze the search term. Example:
{
"term": {
"category.keyword": "books"
}
} iii. Bool Query: The bool query allows combining multiple queries using logical operators such as must, must_not, should, and filter. It provides powerful options for complex search scenarios. Example:
"bool": {
"must": [
{ "match": { "title": "Software Architecture" } },
{ "range": { "price": { "gte": 10 } } }
],
"must_not": {
"term": { "category.keyword": "electronics" }
}
}
}
3. Full-Text Search: Full-text search is a common use case in Elasticsearch. The match query is often used to perform full-text searches. It analyzes the query string, tokenizes it into individual terms, and matches documents that contain any of the terms. Elasticsearch applies scoring to calculate the relevance of each document based on factors like term frequency and inverse document frequency.
Full-text search and relevance scoring in Elasticsearch are heavily influenced by the TF-IDF (Term Frequency-Inverse Document Frequency) algorithm. TF-IDF is a statistical measure used to evaluate the importance of a term within a document and across a collection of documents. Let's explore how TF-IDF is used for relevance scoring in Elasticsearch:
- Term Frequency (TF):
- Term Frequency measures the frequency of a term within a document.
- In Elasticsearch, during indexing, the analyzer processes the text and breaks it into individual terms.
- Each term's frequency within a document is calculated and stored in the inverted index.
- Higher term frequency indicates the term's importance within the document.
- Inverse Document Frequency (IDF):
- Inverse Document Frequency measures the significance of a term across the entire collection of documents.
- It helps identify terms that are rare and potentially more informative.
- IDF is calculated using the total number of documents in the index and the number of documents containing the term.
- Terms that appear in fewer documents receive a higher IDF value.
- Relevance Scoring:
Elasticsearch uses TF-IDF scores to calculate the relevance of a document to a given search query.
When a search query is performed, Elasticsearch retrieves matching documents and calculates the relevance scores for each document based on the TF-IDF algorithm.
Documents containing more instances of the search terms and rare terms receive higher scores.
The scores are used to sort the search results in descending order, with the most relevant documents appearing first.
By incorporating the TF-IDF algorithm, Elasticsearch provides accurate and relevant search results. It considers both the term frequency within a document and the rarity of terms across the document collection. This relevance scoring mechanism ensures that the most relevant documents are ranked higher in search results, improving the overall search experience for users.
4. Filtering: In addition to searching for documents based on their relevance, Elasticsearch allows filtering to narrow down search results based on specific criteria. Filtering is useful for exact matches or querying specific fields. Common filter types include term, terms, range, exists, and more. Elasticsearch provides various filter types that can be used in conjunction with queries or on their own:
- Terms Filter: The
termsfilter matches documents that have any of the specified terms in a specific field. It is useful for performing OR operations. Example:
{
"query": {
"bool": {
"filter": {
"terms": { "category": ["books", "Software Architecture"] }
}
}
}
}
Here's an example that demonstrates the use of multiple filters in Elasticsearch:
Suppose we have an index of products with fields like "name," "category," "price," and "availability." We want to search for products in the "electronics" category with a price range between $100 and $500 that are currently available. We also want to exclude products with the brand "Apple."
{
"query": {
"bool": {
"filter": [
{ "term": { "category": "electronics" } },
{ "range": { "price": { "gte": 100, "lte": 500 } } },
{ "term": { "availability": "available" } },
{ "bool": { "must_not": { "term": { "brand": "Apple" } } } }
]
}
}
}In this example, we use the bool query to combine multiple filters:
- The
termfilter ensures that only products in the "electronics" category are considered. - The
rangefilter narrows down the products based on the price range of $100 to $500. - The
termfilter filters for products that are currently available. - The nested
boolfilter withmust_notensures that products with the brand "Apple" are excluded from the results.
By applying these filters, Elasticsearch will retrieve products that match all the specified conditions, effectively filtering out irrelevant products. The search results will consist of electronics products within the specified price range, currently available, and not associated with the brand "Apple."
5. Aggregations: Aggregations in Elasticsearch provide a powerful way to extract insights from data during the search process. Aggregations enable you to group and analyze data, similar to SQL's GROUP BY clause. You can calculate metrics like count, sum, and average or perform complex analytics such as histograms, date ranges, and nested aggregations.
Let's say we have an e-commerce platform with a product index containing information about various products. We want to retrieve statistical information about the average price, maximum price, and minimum price of products in different categories. We can achieve this using aggregations.
GET /products/_search
{
"size": 0,
"aggs": {
"category_stats": {
"terms": {
"field": "category.keyword",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
}
}
}
}
}
In the above example:
- We use the
aggsparameter to define our aggregations. - The top-level aggregation is named
category_statsand is of typeterms, which allows us to group products by their category. - The
fieldparameter specifies that we want to group by thecategoryfield. - The
sizeparameter limits the number of category terms returned to 10. - Inside the
category_statsaggregation, we define three sub-aggregations:avg_price,max_price, andmin_price. - Each sub-aggregation calculates a specific statistical value based on the
pricefield within each category.
The response from Elasticsearch will include the aggregated statistical information for each category, including the average price, maximum price, and minimum price.
6. Sorting: Elasticsearch allows sorting search results based on specific fields in ascending or descending order. Sorting can be done on numeric, date, or keyword fields. You can also perform multi-level sorting based on multiple fields.
Example: We have an index of books with fields like title, author, and publication year. We want to retrieve the books sorted by their publication year in descending order.
GET /books/_search
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{
"publication_year": {
"order": "desc"
}
}
]
}
7. Highlighting: Highlighting is a useful feature that allows Elasticsearch to highlight matching terms in the search results. It provides context to users by displaying snippets of the document where the matching terms were found. Highlighting is especially helpful in full-text search scenarios.
8. Boosting and Relevance Scoring: Elasticsearch calculates a relevance score for each document based on the search query. Relevance scoring determines the order in which results are returned. You can influence the scoring using boosting techniques, which assign higher importance to certain fields or documents — boosting helps fine-tune search results to meet specific requirements.
Let's say we have an index of products with fields like name, description and brand. We want to search for products matching the query "smartphone" and give higher relevance to products with brand equal to Apple.
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "smartphone"
}
}
],
"should": [
{
"match": {
"brand": "Apple"
}
}
]
}
}
}
In the above example:
- We use the
boolquery to combine multiple clauses for more complex search logic. - The
mustclause specifies that thenamefield must match the termsmartphonefor a document to be considered a match. - The
shouldclause specifies that the "brand" field should match the termApple, giving it a higher relevance. - By using the
shouldclause, we are boosting the relevance of documents that have the "brand" field equal toApplewhile still retrieving documents that match the "smartphone" query in thenamefield.
Elasticsearch calculates relevance scores for each document based on various factors, such as term frequency, inverse document frequency, and field length. By incorporating boosting techniques, like giving higher relevance to specific fields or terms, you can influence the ordering and ranking of search results to align with the desired priorities.
9. Pagination: When dealing with large result sets, pagination becomes essential. Elasticsearch supports pagination through the from and size parameters, allowing you to retrieve specific subsets of search results.
10. Analyzers and Tokenizers: Elasticsearch provides analyzers and tokenizers to process and index text data effectively. Analyzers are composed of tokenizers and token filters, which split text into individual terms and apply transformations such as stemming, lowercase conversion, and removal of stop words. By configuring the appropriate analyzer, you can achieve accurate and relevant search results.
Advanced Searching Techniques
Advanced searching techniques in Elasticsearch can help you refine and enhance the search experience. Here are a few techniques you can leverage:
- Fuzzy Search: Fuzzy search enables you to find results even when there are slight variations or typos in the search terms. Elasticsearch provides the
fuzzinessparameter that can be used with queries likematchormulti_match. It allows for approximate matching based on edit distance. For example:
{
"query": {
"match": {
"title": {
"query": "Software Architecture",
"fuzziness": "2"
}
}
}
}
Here's an example that combines multiple advanced searching techniques in Elasticsearch:
Suppose we have an index of articles with fields like title, content, and tags. We want to search for articles that meet the following criteria:
- The title must contain the term
Software Architect. - The content must include either
data analysisorinformation retrieval. - The tags should match a wildcard pattern of
tech_*(e.g.,tech_data,tech_analysis, etc.).
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Software Architecture"
}
},
{
"bool": {
"should": [
{
"match_phrase": {
"content": "data analysis"
}
},
{
"match_phrase": {
"content": "information retrieval"
}
}
]
}
},
{
"wildcard": {
"tags.keyword": "tech_*"
}
}
]
}
}
}
In this example, we use the following advanced searching techniques:
- The
matchquery ensures that the title contains the termElasticsearch. - Within the
boolquery, theshouldclause uses thematch_phrasequery to find articles with either "data analysis" or "information retrieval" in the content. - The
wildcardquery filters articles based on the tags field, matching tags that start with "tech_" using the wildcard pattern.
By combining these advanced searching techniques, Elasticsearch will retrieve articles that satisfy all the specified criteria, ensuring that the title contains Elasticsearch, the content includes either data analysis or information retrieval, and the tags follow the specified wildcard pattern.
Boosting To Assign Higher Relevance To Specific Fields or Terms
Boosting is a technique in Elasticsearch that allows you to assign higher relevance or importance to specific fields or terms in the search queries. By applying boosting, you can influence the relevance scoring of search results and ensure that certain fields or terms carry more weight in determining the ranking of documents.
Here are a few examples of how you can use boosting in Elasticsearch:
- Field-level Boosting: You can assign a boost value to individual fields to indicate their relative importance. Fields with higher boosts will contribute more to the overall relevance score. For example:
{
"query": {
"bool": {
"should": [
{ "match": { "title": { "query": "Software Architecture", "boost": 2 } } },
{ "match": { "content": "search" } }
]
}
}
}
In this example, the title field is assigned a boost of 2, making it twice as important as the content field. Matches in the title field will have a greater impact on the relevance score.
ii. Term-level Boosting: You can assign a boost value to specific terms within a query to give them higher relevance. This is useful when certain terms are more significant than others in the search context. For example:
{
"query": {
"match": {
"content": {
"query": "search engine",
"boost": 3
}
}
}
}
In this example, the term search engine is given a boost of 3, indicating its higher relevance. Matches containing this exact phrase will have a higher impact on the relevance score.
iii. Boosting Query: You can use the boosting query to explicitly define a positive and negative query, assigning different boost values to each. The positive query contributes positively to the relevance score, while the negative query contributes negatively. For example:
{
"query": {
"boosting": {
"positive": {
"match": { "content": "Software Architecture" }
},
"negative": {
"match": { "content": "Lucene" },
"boost": 0.5
},
"negative_boost": 0.2
}
}
}
In this example, matches in the content field with the term Software Architecture have a positive impact on the relevance score, while matches with the term Lucene have a negative impact but with a lower boost value. The negative_boost parameter adjusts the overall influence of the negative query.
Boosting is a powerful technique that allows you to fine-tune the relevance scoring in Elasticsearch. By assigning boosts to specific fields or terms, you can control the importance of different elements in the search queries and ensure that the most relevant documents receive higher scores.
Geospatial Search and Filtering
Geospatial search and filtering is a significant application of Elasticsearch that enables the storage, indexing, and retrieval of geospatial data for location-based queries. It allows businesses to perform spatial searches and analyze data based on geographic coordinates, shapes, distances, and relationships. Here are a few examples of geospatial search and filtering in real-world applications:
Location-based Services: Geospatial search is widely used in location-based services such as ride-sharing platforms, food delivery apps, and travel websites. Elasticsearch can store and index the geographical coordinates of drivers, restaurants, or points of interest, enabling efficient searches for nearby options based on a user's current location. Geospatial filtering can be applied to find places within a certain radius or within specific boundaries, enhancing the accuracy and relevance of search results.
Real Estate and Property Search: Real estate websites utilize Elasticsearch's geospatial capabilities to enable users to search for properties based on location criteria. Users can filter properties by distance from a specific point, search within a defined boundary (e.g., a city or neighborhood), or find nearby amenities such as schools, hospitals, or parks. Geospatial search empowers users to find properties that meet their location preferences and narrow down their search efficiently.
Logistics and Supply Chain: Geospatial search is valuable in logistics and supply chain management to optimize route planning, fleet management, and asset tracking. Elasticsearch can store and index geospatial data such as delivery addresses, warehouse locations, or vehicle positions. By performing geospatial queries, businesses can identify the most efficient routes, track the real-time location of assets, and monitor the movement of goods throughout the supply chain.
Environmental Analysis: Geospatial search and filtering are vital in environmental studies and analysis. Researchers can leverage Elasticsearch to store and analyze geospatial data related to climate, natural resources, wildlife habitats, or pollution levels. Geospatial queries can be used to identify areas affected by specific environmental conditions, monitor changes over time, or analyze the impact of human activities on ecosystems.
Emergency Services and Disaster Management: Geospatial search is crucial for emergency services and disaster management applications. Elasticsearch can store and index data related to emergency incidents, response resources, and affected areas. Geospatial queries can help emergency responders identify the nearest available resources, analyze the impact area of a disaster, or perform geospatial aggregations to gather insights for effective response planning.
Example of Geospatial search using geo-point and geo-shape data types in Elasticsearch for location-based search.
Suppose we have a real estate platform where users can search for properties based on their location preferences. Each property document in Elasticsearch has a location field of type geo-point to store the latitude and longitude coordinates of the property. Additionally, the platform allows users to define custom search areas by drawing polygons on a map interface.
Indexing Documents: Let's say we have a property with the following details:
- Property ID: 123
- Location: Latitude 40.7128, Longitude -74.0060 (New York City)
- To index this property in Elasticsearch, we would store the
locationfield as ageo-pointdata type with the provided coordinates.
Searching Within a Distance: Now, a user wants to find properties within a 5-mile radius of their current location (Latitude: 40.730610, Longitude: -73.935242). We can use the Geo Distance Query to achieve this:
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "5mi",
"location": {
"lat": 40.730610,
"lon": -73.935242
}
}
}
}
}
}
Elasticsearch will search for documents that fall within the specified distance from the user's location.
3. Searching Within a Custom Polygon: In addition to distance-based searches, the platform allows users to draw a custom polygon on the map to search for properties within that area. The user draws a polygon on the map interface, which generates a set of coordinates defining the polygon's boundary.
We can use the Geo Polygon Query to find properties within the defined polygon:
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_polygon": {
"location": {
"points": [
{"lat": 40.7128, "lon": -74.0060},
{"lat": 40.7115, "lon": -73.9862},
{"lat": 40.7206, "lon": -73.9865},
{"lat": 40.7214, "lon": -74.0083},
{"lat": 40.7128, "lon": -74.0060}
]
}
}
}
}
}
}
Elasticsearch will search for documents whose location falls within the specified polygon.
By combining the geo-point and geo-shape data types in Elasticsearch, we can provide users with powerful location-based search capabilities. Users can search for properties within a certain distance from their location or define custom search areas using polygons. This enables a highly flexible and intuitive search experience, allowing users to find properties based on their specific location criteria.
Note: The provided example coordinates and queries are for illustrative purposes. In a real-world scenario, you would use actual coordinates and implement the queries in the application code.
Geospatial Aggregations and Heatmap Visualizations
Geospatial aggregations and heatmap visualizations are powerful tools in Elasticsearch for analyzing and visualizing data based on geographic information. They allow you to gain insights into spatial patterns, distributions, and densities within the dataset. Let's explore an example that demonstrates the usage of geospatial aggregations and heatmap visualizations:
Suppose we have a dataset of customer locations for a food delivery service stored in Elasticsearch. Each document represents a customer order with a location field of type geo-point containing the latitude and longitude coordinates of the delivery address.
1. Geospatial Aggregations: We can use geospatial aggregations to analyze the density of customer orders in different regions. For example, let's perform a geohash grid aggregation to divide the area into smaller grid cells and count the number of customer orders within each cell:
{
"aggs": {
"order_density": {
"geohash_grid": {
"field": "location",
"precision": 5
}
}
}
}
This aggregation divides the geographic area into cells with a precision of 5. It returns the count of customer orders within each cell, providing insights into areas with high order density.
2. Heatmap Visualization: To visualize the order density on a heatmap, we can use tools like Kibana, which integrates seamlessly with Elasticsearch. In Kibana, we can create a visualization using the geohash grid aggregation results. The heatmap visualization assigns different colors to cells based on the order density, allowing us to identify regions with higher concentrations of customer orders.
By adjusting the precision parameter in the geohash grid aggregation, we can control the level of granularity in the heatmap visualization. A higher precision value creates smaller cells and provides more detailed insights into local patterns, while a lower precision value creates larger cells and highlights broader density trends. Additionally, Kibana provides interactive features to explore the heatmap, such as zooming, panning, and tooltips displaying the exact count of orders in each cell.
By leveraging geospatial aggregations and heatmap visualizations, businesses can gain valuable insights into the spatial distribution of their data. This information can be used to optimize resource allocation, identify areas with high demand, or make data-driven decisions based on geographic patterns. Whether it's analyzing customer locations, monitoring service coverage, or studying population densities, geospatial aggregations, and heatmap visualizations in Elasticsearch provide powerful tools for spatial analysis and visualization.
Performance Optimization
Performance optimization is a crucial aspect when working with Elasticsearch to ensure efficient and fast search operations. By following best practices and implementing optimization techniques, we can enhance the overall performance of the Elasticsearch cluster. Let's explore some key areas of performance optimization:
Hardware and Resource Allocation: Ensure that the Elasticsearch cluster is running on hardware that meets the recommended specifications for the workload. Allocate sufficient resources such as CPU, memory, and disk space to handle the indexing and search operations effectively.
Indexing and Bulk Operations: When indexing large amounts of data, utilize bulk operations instead of individual document indexing to reduce overhead. Bulk indexing allows to send multiple documents in a single API call, improving indexing efficiency. Additionally, consider optimizing the mappings and disabling unnecessary features like dynamic mapping to reduce indexing overhead.
Cluster Configuration: Configure the Elasticsearch cluster properly by adjusting settings such as shard allocation, replica settings, and thread pools. Tune these configurations based on the workload and cluster size to optimize resource utilization and improve search performance.
Query Optimization: Craft efficient queries using the Elasticsearch Query DSL. Avoid using costly operations like wildcard searches and prefer more efficient options like prefix queries or term queries. Utilize features like query caching and filter clauses to improve query execution time.
Indexing and Search Filters: Use indexing filters to exclude unnecessary fields from being indexed, reducing the storage and memory requirements. Similarly, leverage search filters to perform pre-filtering on search queries, narrowing down the result set before executing complex queries.
Monitoring and Profiling: Monitor the performance of the Elasticsearch cluster using tools like the Elasticsearch Monitoring API or dedicated monitoring solutions. Monitor key metrics such as CPU usage, memory consumption, disk I/O, and search latency to identify performance bottlenecks and optimize accordingly.
Index Segments Optimization: Optimize the size of index segments by periodically merging smaller segments into larger ones. This reduces the overhead of searching through multiple small segments and improves search performance.
Caching and Warm-Up: Take advantage of Elasticsearch's caching mechanisms to cache frequently executed queries, filter results, or aggregations. Additionally, use the warm-up API to pre-warm the indices, ensuring that the necessary data is loaded into memory for faster search responses.
Cluster Scaling: If the workload demands it, consider scaling the Elasticsearch cluster horizontally by adding more nodes to distribute the indexing and search load. This helps in achieving higher throughput and improved search performance.
By focusing on these performance optimization techniques, we can fine-tune the Elasticsearch cluster to deliver fast and efficient search operations, ensuring a responsive and scalable search experience for the application or system. Remember to continuously monitor and analyze the performance metrics to identify areas of improvement and adapt to changing requirements.
Query Optimization and Caching
Query optimization and caching are essential techniques for improving search performance in Elasticsearch. They involve optimizing search queries and leveraging caching mechanisms to reduce the computational overhead and improve response times. Let's delve into these concepts in more detail:
Query Optimization: Efficient query design plays a crucial role in optimizing search performance. Consider the following strategies for query optimization:
Use Query DSL: Utilize Elasticsearch's Query DSL to construct queries tailored to the specific requirements. Choose appropriate query types based on the nature of the data and the search criteria. For example, use term queries for exact matches and range queries for numeric or date ranges.
Filtering: Utilize filter clauses instead of query clauses for non-scoring and cacheable criteria. Filtered queries are faster because they skip the scoring process, and the results can be cached for subsequent queries.
Query Caching: Enable query caching for frequently executed queries. Elasticsearch caches the results of queries, and if the same query is executed again, it can be served directly from the cache, avoiding the need for re-evaluation. Caching is particularly useful for read-heavy workloads with repetitive queries.
Scoring Optimization: Adjust the scoring parameters to fine-tune the relevance of search results. Elasticsearch's scoring algorithm, based on TF-IDF and other factors, can be customized to prioritize certain fields or terms over others, boosting the relevance of specific results.
Caching: Caching can significantly improve search performance by storing and reusing the results of expensive operations. Elasticsearch provides several caching mechanisms:
Filter Caching: Filters that are cacheable can be stored in the filter cache. When the same filter is used again in subsequent queries, Elasticsearch can retrieve the cached results directly, saving computational resources.
Field Data Caching: Field data caching stores frequently accessed field values in memory. This is beneficial for fields that are used for sorting, aggregations, or script calculations. Caching field data reduces disk I/O and speeds up operations involving these fields.
Query Caching: As mentioned earlier, query caching caches the results of frequently executed queries, allowing them to be served from the cache without re-evaluation.
It's important to note that caching is most effective when the data being cached remains relatively stable. If the data is frequently updated, the cache may become less useful as it needs to be invalidated and refreshed more frequently.
By optimizing queries and leveraging caching mechanisms, Elasticsearch can deliver faster and more efficient search results. Regular monitoring and profiling can help identify query performance bottlenecks and fine-tune the caching strategy accordingly. Remember to strike a balance between query complexity, caching, and the freshness of data to ensure optimal search performance.
Case Studies and Real-World Applications
Case studies and real-world applications showcase the practical use of Elasticsearch in various industries and highlight its capabilities. Let's explore a few examples:
E-commerce and Retail: Many e-commerce platforms leverage Elasticsearch to power their search functionality. For instance, an online marketplace can utilize Elasticsearch to enable fast and accurate product search, filtering by attributes (e.g., price range, brand, availability), and personalized recommendations based on user behavior and preferences. Elasticsearch's indexing and querying capabilities ensure a seamless and efficient search experience, improving customer satisfaction and conversion rates.
Media and Content Management: Media organizations and content management systems benefit from Elasticsearch's powerful search capabilities. For instance, a news website can use Elasticsearch to index and search through vast amounts of articles, providing users with relevant news based on their interests and trending topics. Elasticsearch's relevance scoring and filtering options enable precise content recommendations, enhancing user engagement and retention.
Log Analytics and Monitoring: Elasticsearch is widely used for log analytics and monitoring in IT operations. Companies can collect logs from various sources, index them with Elasticsearch, and perform real-time searches and aggregations to gain insights into system performance, identify issues, and detect anomalies. Elasticsearch's speed, scalability, and ability to handle high-volume log data make it an ideal choice for log analysis and monitoring applications.
Healthcare and Life Sciences: Elasticsearch plays a significant role in healthcare for building robust medical search systems. For example, a medical research organization can utilize Elasticsearch to index and search medical literature, patient records, and clinical trial data. This enables healthcare professionals to quickly access relevant information, make data-driven decisions, and improve patient care. Elasticsearch's flexible query DSL and advanced search features are instrumental in handling complex medical data.
Financial Services: Elasticsearch is employed in the financial sector for various use cases. Banks and financial institutions can leverage Elasticsearch to power their fraud detection systems by analyzing large volumes of transaction data in real time. Elasticsearch's ability to handle streaming data, perform aggregations, and support complex queries facilitates rapid identification of potentially fraudulent activities, minimizing risks and ensuring security.
These are just a few examples of how Elasticsearch is applied in real-world scenarios. Its versatility, scalability, and powerful search capabilities make it a popular choice across industries for building intelligent search engines, data analytics platforms, and recommendation systems. Elasticsearch's ability to handle structured and unstructured data efficiently, combined with its integration with other technologies like machine learning and natural language processing, opens up endless possibilities for innovative applications in diverse domains.
Conclusion
Elasticsearch, with its powerful search capabilities and the utilization of aliases, offers an efficient solution for building high-performance search engines. Aliases provide the flexibility to optimize search operations, enhance query performance, and dynamically manage indexes. By utilizing aliases, e-commerce businesses can ensure uninterrupted service, leverage search microservices, and enhance their overall data management capabilities. Embracing aliases empowers organizations to evolve their product indexes while maintaining a stable and performant application environment. This article has explored the practical usage of aliases through an architecture diagram and examples, showcasing their significance in creating an efficient Elasticsearch search engine. We have discussed advanced the searching techniques employed by Elasticsearch, starting with an overview of its architecture. It has covered fundamental concepts such as query DSL, relevance scoring, filtering, and aggregations, enabling developers to construct precise and efficient search queries. The exploration of advanced features like multi-field querying and geospatial search demonstrates Elasticsearch's versatility in handling complex search requirements. To ensure optimal performance, the article has also touched upon optimization strategies and best practices for Elasticsearch. These include hardware and resource allocation, indexing and bulk operations, query optimization, caching, and index optimization techniques such as segment merging. By implementing these strategies, developers can fine-tune their Elasticsearch clusters and achieve faster and more efficient search operations.
Opinions expressed by DZone contributors are their own.
Comments