Entity Framework Core 3.0 and SQL Server Performance Optimization, Part 1: Parameters Sniffing
Implement SQL Server performance optimization using the Entity Framework Core and parameter sniffing.
Join the DZone community and get the full member experience.
Join For FreeMany developers are complaining that the Entity Framework is not fast or it has a lack of performance. Subsequently, I have investigated the problem to find a root. In most cases, I have discovered that the Entity Framework/Core is not guilty and that the problem is coming from somewhere else. In this article, I will discuss one of the most popular, and hidden, problems with Entity Framework and SQL Server, and I share a few solutions for the problem.
Parameter Sniffing
The first time a query or stored procedure runs on a SQL Server, the SQL Server looks at the passed parameter values to the query and creates an execution plan based on these parameters, and it stores the generated plan with the passed parameters in the query plan cache. The generated plan can be used for the same query with different parameter values. With this mechanism, the SQL Server can save some query generating/recompiling time. The process of looking at parameter values when compiling a stored procedure or a query is known as parameter sniffing.
Example
ProductInventory is a persistent entity. We produce many of them, and lastly, we seed them with dummy data.
public class ProductInventory
{
public long ProductInventoryId{get;set;}
public string Name{get;set;}
public double AxisCalibration{get;set;}
public string Description{get;set;}
public DateTimeOffset CreateDate{get;set;}
}Below, I have created the seed method 149 entities (ProductInventory) with ‘Name’ “PlayStation 4”. Half of CreationDate is (2018, 5, 5) and the other half (2017, 5, 5)
for (var i = 1; i < 150; i++)
{
modelBuilder.Entity < ProductInventory > ().HasData(
new ProductInventory {
ProductInventoryId = i,
Name = @ "PlayStation 4",
AxisCalibration = random.NextDouble() * 1000,
Description =
@ "TestDataData...",
CreateDate = (IsOdd(i)) ? new DateTime(2017, 5, 5) : new DateTime(2018, 5, 5)
}
);
}Secondarily, the code below creates about 100000 entities with ‘Name’ “Xbox one”. Half of CreationDate is (2019) and the other half (2017, 5, 5).
for (var i = 150; i < 100000; i++)
{
modelBuilder.Entity < ProductInventory > ().HasData(
new ProductInventory {
ProductInventoryId = i,
Name = "XBox One",
AxisCalibration = random.NextDouble() * 1000,
Description = @ "Test Data…"
CreateDate = (IsOdd(i)) ? DateTimeOffset.Now : new DateTime(2018, 5, 5)
});
}Other data with different names are less important for the test.
for (var i = 100000; i < 101000; i++)
{
var name = Guid.NewGuid().ToString();
modelBuilder.Entity < ProductInventory > ().HasData(
new ProductInventory {
ProductInventoryId = i,
Name = name,
AxisCalibration = random.NextDouble() * 1000,
Description = @ "TestData ...",
CreateDate = (IsOdd(i)) ? DateTimeOffset.Now : new DateTime(2018, 5, 5)
});
} The generated data has the following characteristics:
The property name and
DateCreatedhave a non-cluster-index. If you are not familiar with the non-cluster-index and query plan, then, keep in mind Scan = Bad and Seek = Good... B-Tree.The data are not evenly distributed. If you have no idea what the Normal Distribution theory is, then keep is in mind that a few queries with different input parameters might return a different number of rows.
The query searches below are for data with the given name in the given time range. There are three passed parameters into the query, the name to be found, the start creation date and end creation date.
productInventoryDbContext
.ProductInventories
.Where(x => EF.Functions.Like(x.Name, queryName) && x.CreateDate >= firstDate && x.CreateDate <= secondDate)
.OrderByDescending(x => x.CreateDate)
.ToList();The first senior. Let us search for a small amount of data for example “PlayStation 4” in the year 2017, and then, we search for a big amount of data, for example, data “Xbox One” in the year 2018. I call the first query small-data-query and the other one big-data-query.
Here is the example code:
Console.WriteLine("************* Find small amount of Data 2017!******************");
var firstDate = new DateTime(2017, 1, 1);
var secondDate = new DateTime(2017, 12, 12);
var queryName = "PlayStation%";
var products2017 = FindData(productInventoryDbContext, queryName, firstDate, secondDate);
Console.WriteLine($ "************* Number of found Records: {products2017.Count()} !******************");Then, I execute the following code:
firstDate = new DateTime(2018, 1, 1);
secondDate = new DateTime(2018, 12, 12);
queryName = "XBox%";
var products2018 = FindData(productInventoryDbContext, queryName, firstDate, secondDate);
Console.WriteLine($ "************* Number of found Records: {products2018.Count()} !******************");Output:
 Figure 1— First retrieve 75 entities, after that 49925 entities
Figure 1— First retrieve 75 entities, after that 49925 entities
Keep it in mind: we have loaded 75 entities, after that, we have loaded 49925 entities.
To understand the problem, let us a look behind the scenes to see what is happening. I am using SQL Server 2019 and EF Core 3.0 Preview. Besides, I have enabled the wonderful feature Query Store when the database is created, and I can use it to see the Query Plans.
The code for enabling theQuery Store:
// Delete and create the database.
productInventoryDbContext.Database.EnsureDeleted();
productInventoryDbContext.Database.EnsureCreated();
// Enable Query Store to Generate the Query Plans!
productInventoryDbContext
.Database
.ExecuteSqlCommand(
@"ALTER DATABASE ProductInventoryDatabase
SET QUERY_STORE = ON(
OPERATION_MODE = READ_WRITE)
");
}The SQL Server has generated the Query Plan, as shown Figure 2, based on the input of the first query (with a small number of records), and it has reused the plan for the second query (with a big number of records)!
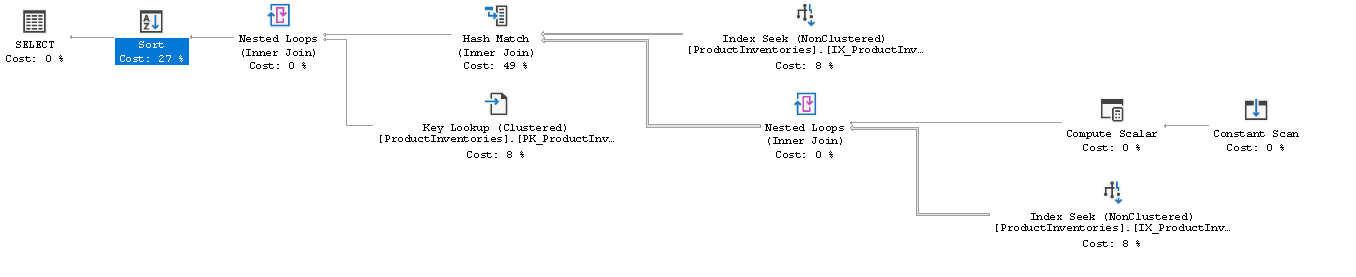
 Figure 2 — Generated Query Plan based on small data
Figure 2 — Generated Query Plan based on small data
The total time is close to 2.6 seconds, as shown above in the column “total duration,” and you can see that the execution count is 2, one time for the small query, and the other one for the big one.
The second scenario is magical; I have moved the small data query code down and the big data query up (switch the code blocks), nothing special. The total return entities are still the same. I have also cleared all query plans to make sure that the SQL Server does not use the existing one.
After that, I have executed the code once more.
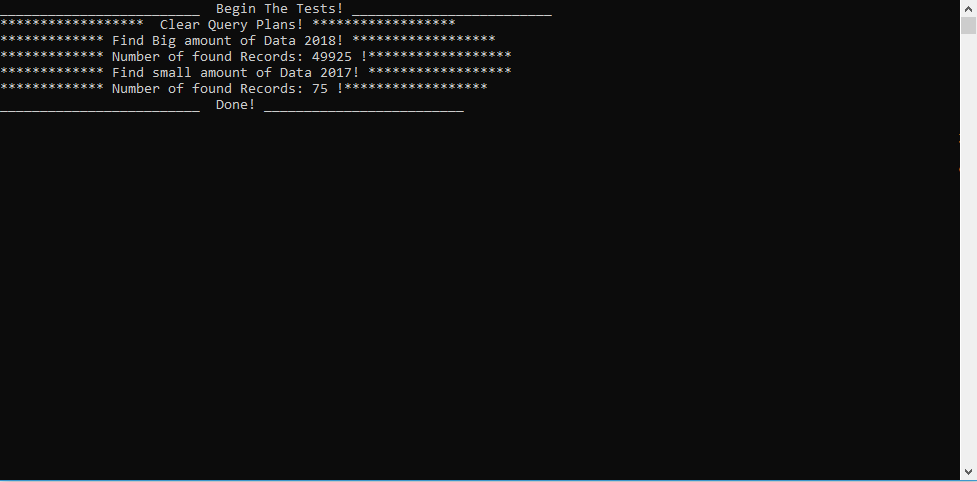 Figure 3 — first retrieve 49925, and then 75
Figure 3 — first retrieve 49925, and then 75
As you can see above. we have retrieved 49925 entities and then 75 entities.
Let us see the new generated Query Plan.
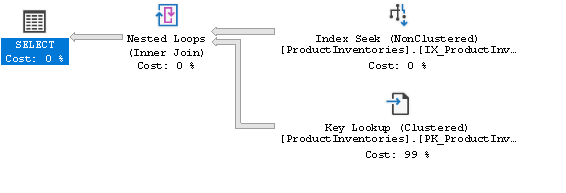
 Figure 4 — Generated Query Plan based on big data
Figure 4 — Generated Query Plan based on big data
Amazingly, we receive something that is now completely different! Moreover, the total duration time is only 1 second; this is close to a 70 percent enhancement! Wow! This example is handling only a small set of data, think about what it would be if you had millions of records! So, why we have a new plan? The answer is a straightforward — parameter sniffing. The SQL Server generates the query plan when the first query arrived and is based on the input parameters. In our first scenario, the problem was that the first plan is perfect for a small set of data and not for s big set of data, but SQL Server has used the first created plan for both scenarios.
How can we fix the problem? To be fair, the best solution for the problem is a good data access layer design with even data distribution helps you to avoid the problem. We can solve the problem in legacy systems in different ways. The core concept for the most solutions is removing the existing bad plan from the query plan cache.
To prove that concept, we go back to our first scenario. I shall call the method ClearQueryPlans between the first and second query. ClearQueryPlans removes all query plans from ProductInventoryDatabase. When the SQL Server is not obtaining the plan from the query plan cache, then it creates a new plan.
I have set a breakpoint just for this demo:
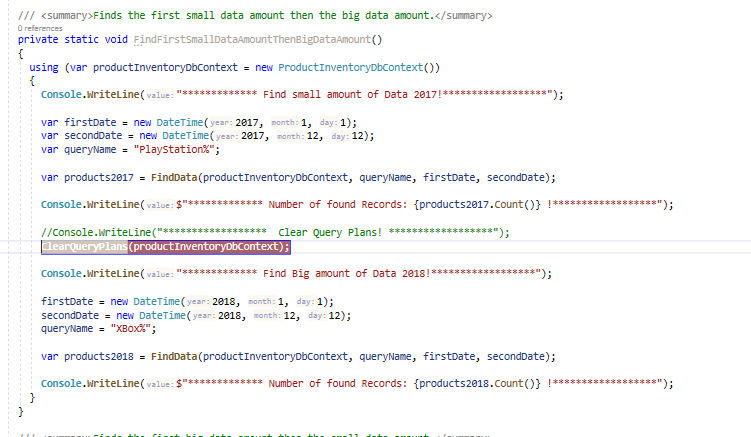
Figure 5 — Clean Query Plan cache between the data search
Immediately, when the breakpoint is hit, we can see the generated Query Plan for a small data query, as shown in Figure 6:
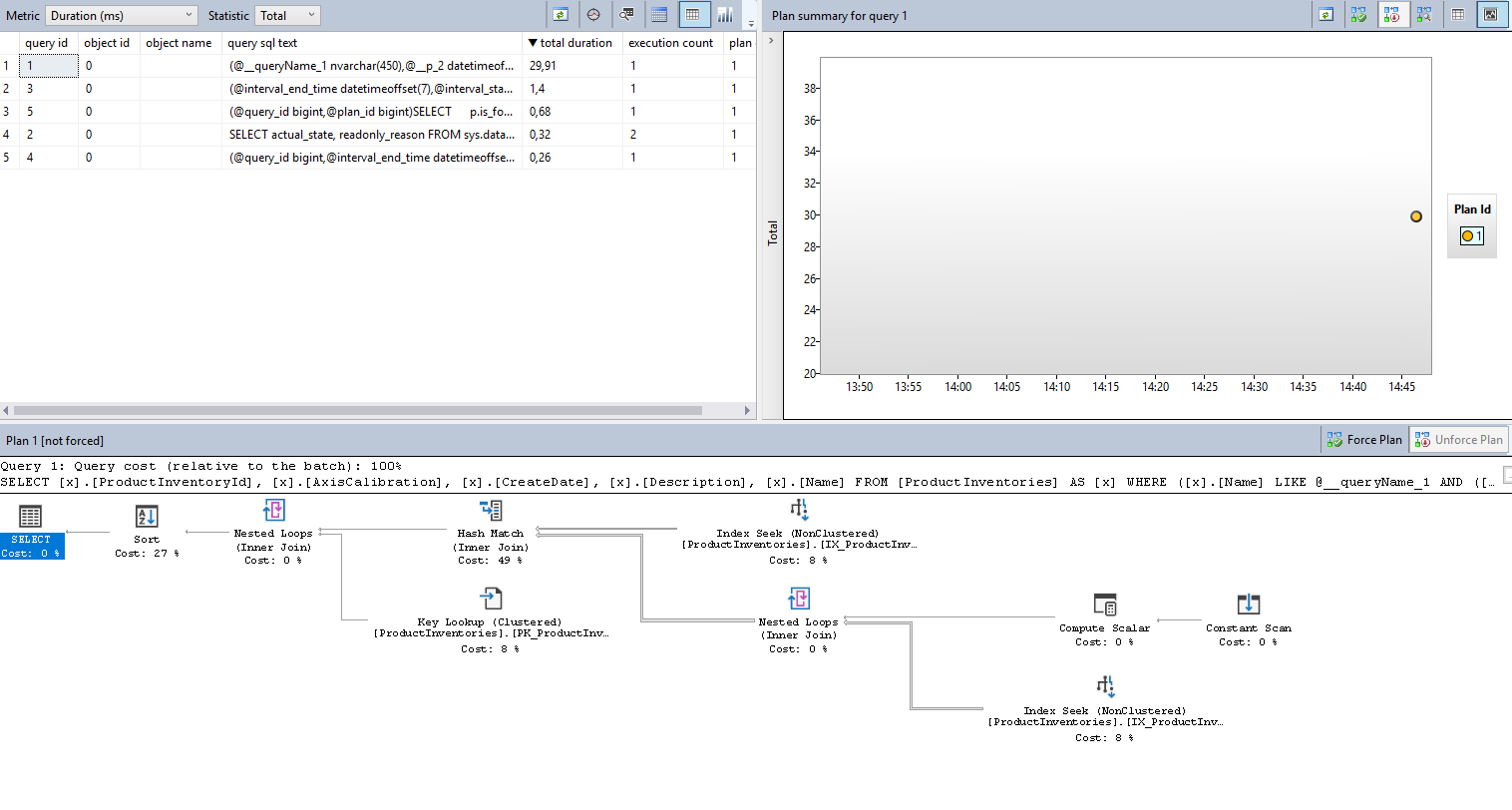 Figure 6 — Query Plan for a small amount of data before the clean cache
Figure 6 — Query Plan for a small amount of data before the clean cache
As we expected, everything is okay for the small data query.
Now, I press F5 to continue.
The bad plan is removed, and now, the SQL Server generates a new plan:
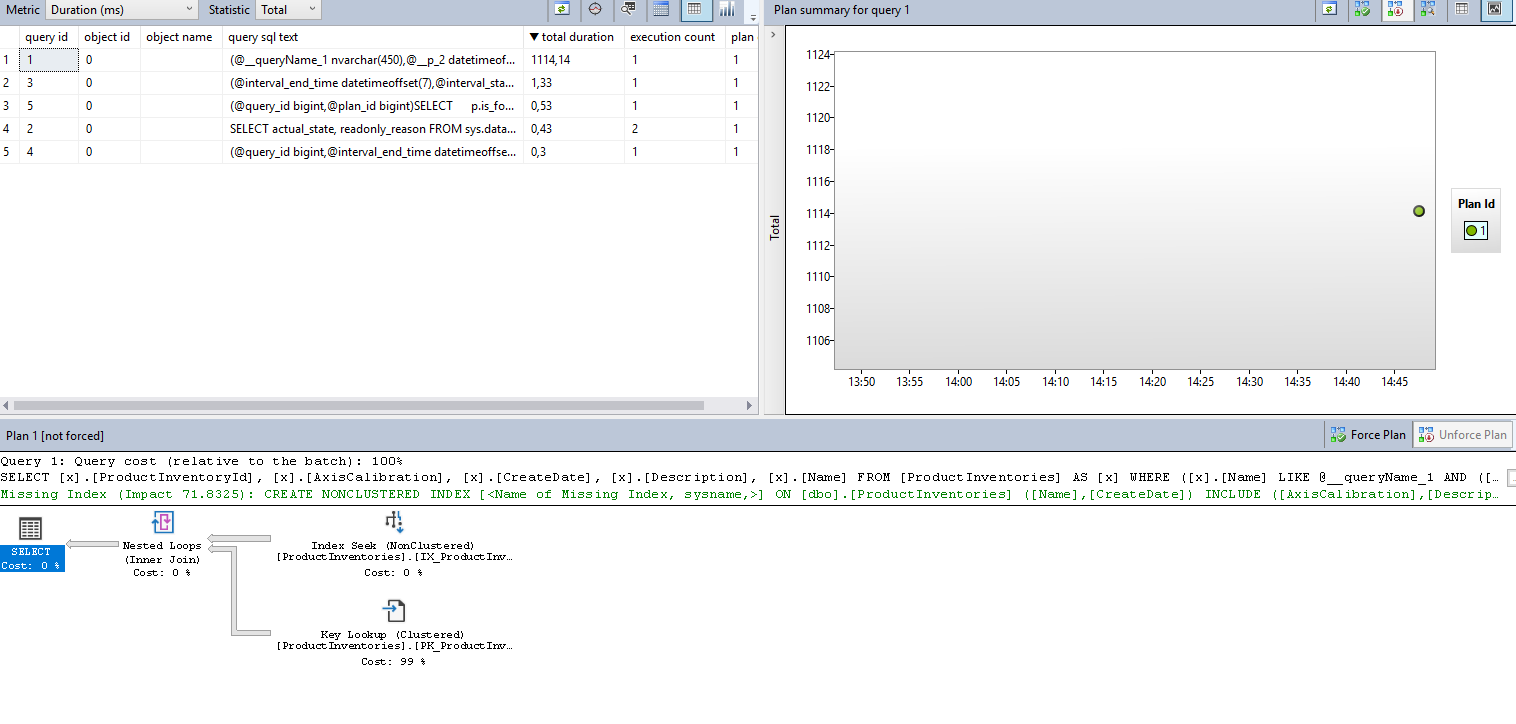
Figure 7: Query Plan for big data after clean cache
Wow, we have 1.1 seconds for the second query; the time summation for both queries is 1.1! This approach can solve the problem! How can we cleanly implement it in the Entity Framework Core?
To answer that, I would use the concept of Entity Framework Core CommandListener (because EF Core, until now, does not support Interceptors), and I can use the keyword Recompile.
Recompile forces the SQL Server to generate a new execution plan every time these queries run.
I have defined a new class, which is called QueryCommandListener and it contains the method below:
public void OnCommandExecuting(DbCommand command, DbCommandMethod executeMethod, Guid commandId, Guid connectionId, bool async, DateTimeOffset startTime)
{
if (command.CommandType != CommandType.Text || !(command is SqlCommand)) return;
if (command.CommandText.Contains("ProductInventories") && !command.CommandText.Contains("option(recompile)"))
{
command.CommandText = command.CommandText + " option(recompile)";
}
}public void OnCommandExecuting(DbCommand command, DbCommandMethod executeMethod, Guid commandId, Guid connectionId, bool async, DateTimeOffset startTime)
{
if (command.CommandType != CommandType.Text || !(command is SqlCommand)) return;
if (command.CommandText.Contains("ProductInventories") && !command.CommandText.Contains("option(recompile)"))
{
command.CommandText = command.CommandText + " option(recompile)";
}
}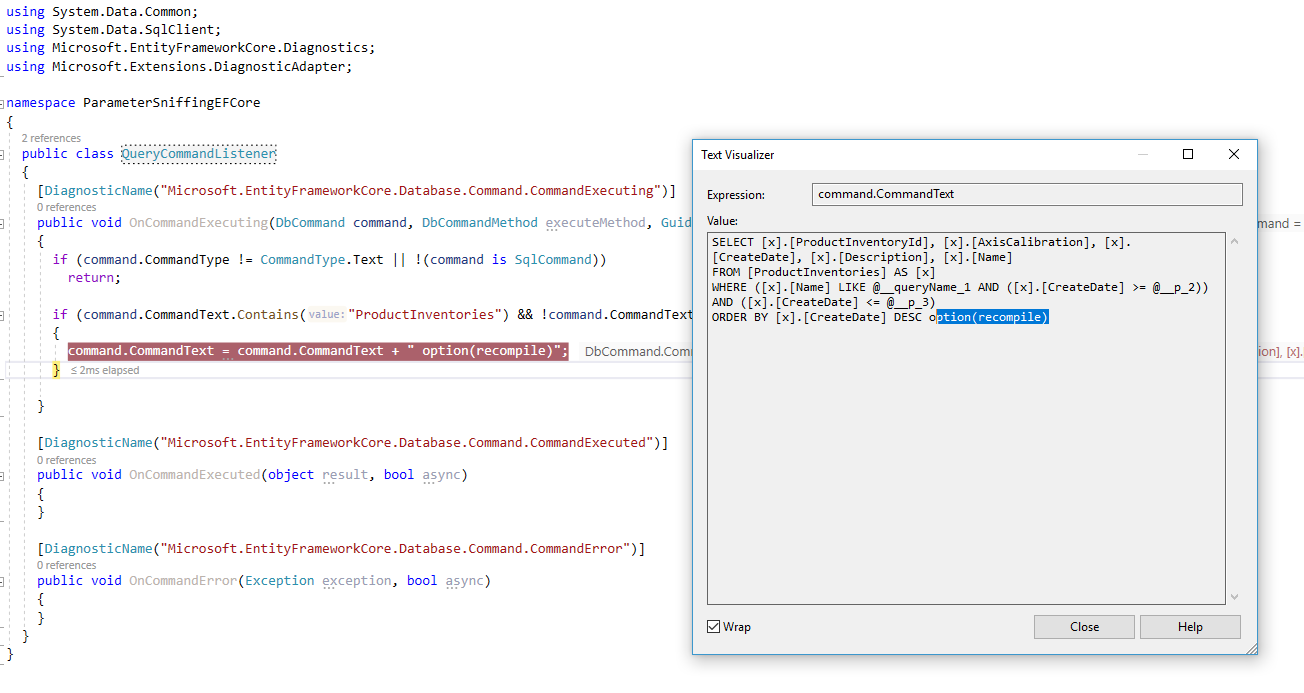
Figure 8: The problem is fixed with recompile
Finally, when we sum the time for both generated query plans, then we are close to 1.1 seconds. In addition, we have with this approach cleanly achieve our goal. There are many other tricks to solve the problem, for example, you can use OPTIMIZE FOR to help the SQL Server to find the best plan or we can build some store logic with if else according to your business logic and depending on the input parameters.
Summary
Parameter sniffing is hiding a problem, and it can have a massive impact on your performance when the database becomes large. You have many ways to fix the problem, for example, with ‘recompile’ as described in the example above, but do not forget that a good domain design for your application with the relational database can help you to avoid like those problems.
For the source code, check out my GitHub repo.
Published at DZone with permission of Bassam Alugili. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments