Embedding Ethics Into Multi-AI Agentic Self-Healing Data Pipelines
With this article, understand how to include ethical practices while developing a multi-agent generative AI framework for self-healing data pipelines.
Join the DZone community and get the full member experience.
Join For FreeThe race to design a fully autonomous system is fostering innovations in the development of modern data systems. Developers are striving to create data ecosystems that are self-correcting and have minimal downtime so as to manage data movement effectively within their organizations.
Due to such a drive for automation, the use of self-healing data pipelines has increased rapidly. A conventional data pipeline consists of data processing elements connected in a relevant manner to move data between two different data systems. For example, extracting data from IoT devices, such as temperature sensors, and loading it into an analytical database for monitoring forms a simple ELT data pipeline. Such traditional pipelines are prone to limitations, including downtime, crashes, low scalability, and excessive monitoring overhead.
To overcome these drawbacks, you can opt for self-healing pipelines that can detect errors, correct them, and monitor the continuous movement of data through different components in an autonomous manner. Due to such efficiency, self-healing data pipelines are increasingly becoming an integral component of modern data workflows in enterprises.
In addition, self-healing pipelines facilitate data reliability, scalability, and the reduction of maintenance and recovery costs. Despite these benefits, using a self-healing data pipeline presents some ethical challenges. This can include questions such as how the self-healing systems detect errors, make corrections, and what logic they use to transform or discard data.
This article explains the ethical challenges of using self-healing data pipelines and measures to overcome these limitations.
A Brief Overview of Building Self-Healing Pipelines Using a Multi-Agent GenAI Framework
To build robust self-healing data pipelines, you can use a combination of several AI agents known as the multi-agent GenAI framework. Each AI agent performs a specific task assigned to it by leveraging an LLM to monitor, identify, and resolve errors occurring in a data pipeline without human involvement.
Components of Multi-Agentic Self-Healing Data Pipelines
Agent Architectural Framework
The agent architecture is a team of AI agents that can ingest, transform, and load data between different sources and destinations. This framework also consists of AI agents that can diagnose and fix errors as data moves between source and target systems.
Large Language Models
LLMs are useful for reasoning, identifying contextual gaps, making predictions, and fine-tuning data pipelines based on feedback. By facilitating these functionalities, LLMs help in the continuous improvement and optimization of self-healing data pipelines.
Communication Protocols
Components such as APIs and event buses help in communicating between multiple agents. This helps in maintaining coordination and task distribution between the multiple agents of the data pipeline framework.
Workflow Orchestration Tools
Orchestration tools such as Airflow DAGs and LangGraph help in automating and scheduling various tasks of self-healing data workflows. You can also build customized workflow agents to orchestrate the movement of data throughout the pipeline.
Ethical Discrepancies in Self-Healing Data Pipelines
Absence of Explainability
The AI agents used in developing multi-agentic self-healing data pipelines leverage LLMs to perform designated functions. If the LLMs do not possess explainability capabilities, then the AI agent-based self-healing system behaves like a black box.
In such cases, the agents will diagnose and fix problems without giving any explanations. Sometimes this can lead to the deletion or alteration of sensitive or critical data, and you may not be able to trace which agent performed the action. Such opacity can lead to violations of data regulatory guidelines and can even introduce additional errors instead of resolving them.
For example, a self-healing data pipeline system used in a bank makes self-correction flags for a particular transaction of data as inappropriate without providing any explanation. If the customer asks for an explanation citing ‘right to explanation’ under GDPR regulation, the compliance authorities and developers may find it difficult to explain why the transaction was declared as inappropriate. Such a violation of the data governance framework can lead to a lack of transparency and decrease trustworthiness among the bank customers.
Hidden Biases
If the AI systems used in your self-healing data pipeline contain hidden biases, then there is a risk that the pipeline starts treating biased information as legitimate. Here, the real danger is not that the pipeline can break, but the fact that it can start drifting from its intended ethical usage.
For example, a self-healing sales data pipeline can start flagging rural regions as noise, eliminating the rural market from sales. Such drifting of function can result in degradation of the pipeline’s performance. In addition, such bias can not only lead to reduced profits but also promote discrimination.
Limitations of Autonomous Corrections
In self-healing data pipelines built using a multi-agentic generative AI framework, each component behaves in an autonomous manner. However, these elements can behave asynchronously sometimes if one component nullifies the action of other components.
For example, a resource-allocation agent can scale up compute nodes to accommodate increased data load, while a performance optimization agent can scale them down to reduce costs. This usually happens if there is no central coordination logic in your data pipeline system.
How to Make Self-Healing Data Pipelines Transparent
Human Checkpoints
Include manual checkpoints or an overview of the working of each AI agent within your self-healing data pipeline. Develop a mechanism such that every agent that takes self-healing decisions keeps a log of its actions. You can also integrate a manual checkpoint before an agent permanently deletes or transforms data. Adopt AI explainability techniques such as SHAP or LIME to better interpret the actions of agents.
Audit Trails and Versioning
Audit trails are a detailed record of all the changes made in a system over a period of time. You can integrate audit trails in the multi-agentic self-healing data pipelines to keep a log of tasks such as data ingestion failures, schema evolution, and model retraining. You can use tools such as OpenTelemetry, Datadog, and Elastic Stack for this purpose.
Tools such as Delta Lake, LakeFS, and DVC help in version control by taking snapshots of datasets and reverting to earlier versions. Auditing and versioning facilitate data replay and root-cause analysis required for correcting failures in self-healing data pipelines.
Enforce Standard Ethical Policy
Each AI agent within the self-healing data pipeline architecture should follow organizational ethical policy. You can utilize platforms such as Open Policy Agent and Kyverno to ensure data pipelines work within the standard ethical norms.
Additionally, you can track performance metrics such as bias drift score, override ratio, and explainability gap using MLFlow tracking servers or Grafana dashboards. This helps in measuring the ethical reliability of your self-optimized data pipelines.
Leverage Governance Agents
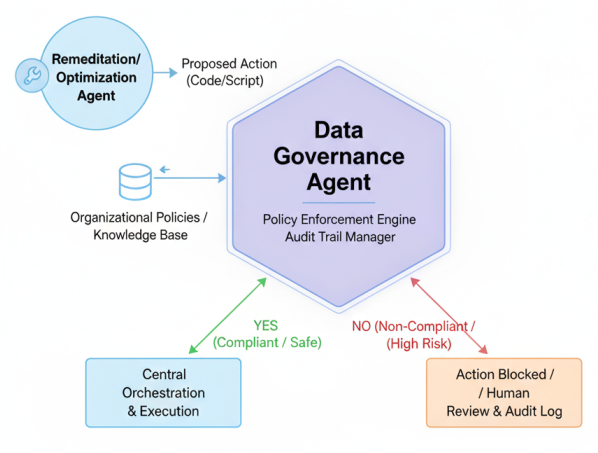
Governance agents are specialized systems that function independently to monitor, validate, and log actions taken by agents in self-healing data pipelines. Behaving like a control layer above orchestration architecture, governance agents help in monitoring metadata along with data movement. As a result, you can leverage them for ethical policy enforcement, version control, and explainability.
For example, governance agents use a policy-as-code framework to evaluate whether an action is completed or not. Before a correction is executed, the agent informs the governance agent API. If the action does not meet the ethical policy standards, the governance agent rejects it, preventing a mishap.
package pipeline.governance
deny[msg] {
input.action == "delete_records"
input.dataset == "financial_transactions"
msg := "Record deletion requires manual approval in financial datasets"
}Conclusion
Self-healing data pipelines are becoming a necessity as more and more businesses are looking to automate their organizational workflows. This article sheds light on the ethical challenges associated with multi-agentic self-healing data pipelines. I have also discussed practices as well as tools to overcome these challenges.
As software developers or engineers, it is our responsibility to create not only intelligent but also ethical AI-driven systems. Keeping this in mind, it is possible to develop a robust framework of multi-agentic self-healing data pipelines that are smart in completing the assigned tasks, as well as set an example of responsible usage of AI. By doing so, we can make our organizational data workflows resilient as well as reliable by leveraging technology along with human expertise.
Opinions expressed by DZone contributors are their own.
Comments