How Unified Data Pipelines Transform Modern AI Infrastructure
AI now uses diverse data types, and old pipelines struggle. Unified data flows centralize data, simplifying management and improving model training and performance.
Join the DZone community and get the full member experience.
Join For FreeOver time, the rate of improvement in AI models has outpaced that of pipelines intended to support them. Teams are moving towards more complex signals and higher workloads, but it becomes increasingly difficult for the pipelines to support this. This gap widens with every new data source that adds to this stack, forcing the engineers to hold together workflows that were never designed to work together.
Performance slows, iteration decreases, and now the system begins to limit the very models it was built to support. This issue is solved by a unified data flow, which ensures that AI has a scalable structure. The sections below will break down the key details on why this change is so important.
Multiformat Data as the New Standard
Modern AI models collect data from sources that do not resemble each other, arrive at different speeds, and contain very different data structures. Teams are now mixing visual signals with text, machine output with human-generated content, as well as time-based streams with static artifacts.
The range keeps expanding, and with every category, it brings in new limitations that are fed into the pipeline. The traditional pipelines are no longer able to keep up with the diversity that this current model demands. There are also some new pressures introduced by this model, like:
- Formats that require different preparation strategies before training
- Inputs that vary widely in size, timing, complexity, and other characteristics
- Workflows that are increasingly difficult to align, as every source pursues a different path.
Unified data flows let teams manage all their data in one consistent pipeline, instead of dealing with scattered processes that don’t work well together.
Where Traditional Pipelines Break Down
Legacy data pipelines were designed for workloads that appeared to be uniform and predictable. They assume a steady flow of inputs with similar structure, timing, and preprocessing needs. But as teams begin working with a broader set of data sources, all of those assumptions collapse.
Each category forces the pipeline to behave differently, which in turn leads to different code paths, special-case handling, and storage layouts that are no longer a single, integrated system.
Over time, these differences create friction that slows experimentation and makes interpreting model results difficult. The weaknesses tend to show up in practical ways, such as:
- Pipelines that split into format-specific tracks, which never line up perfectly
- Logic for preprocessing develops in different teams and tools.
- Metadata becomes inconsistent, which disrupts downstream phases
The teams are affected as the projects continue to expand in size, with models using a wider range of inputs. Legacy designs then become a limiting factor, rather than being a support, over time.
Why Unified Data Flows Matter
Unified data flows provide a mechanism for teams to manage different inputs without being left with a maze of separate, independent workflows. In other words, rather than working with format-specific tools, this pipeline applies a consistent set of structural requirements to all sources.
This ensures a consistent flow of data, which reduces friction across ingestion, preparation, and delivery. This, in turn, ensures that models are able to access data in a format that facilitates stable learning. A unified approach makes it much easier to evolve the pipeline over time, since changes occur in one place rather than across scattered subsystems. Several advantages that define the value of unification are as follows:
- Stronger alignment between preparation steps, regardless of origin
- Less engineering overhead due to repeated logic
- Greater predictable behavior during training and inference.
This approach shows how modern platforms like Apache Spark, Ray, and Daft support multimodal workloads in a common execution model rather than different modes being considered as separate systems.
Essential Components of a Modern Pipeline
A modern pipeline handles variation by establishing a stable structure that every input can accommodate. This structure does not eliminate differences between formats, but provides a path that absorbs them without needing separate workflows.
Each stage contributes to a structure that remains predictable despite new sources, new tools, or model requirements entering the picture. Teams provide a foundation that functions as a single engine rather than a series of disconnected components. Some characteristics make up this foundation:
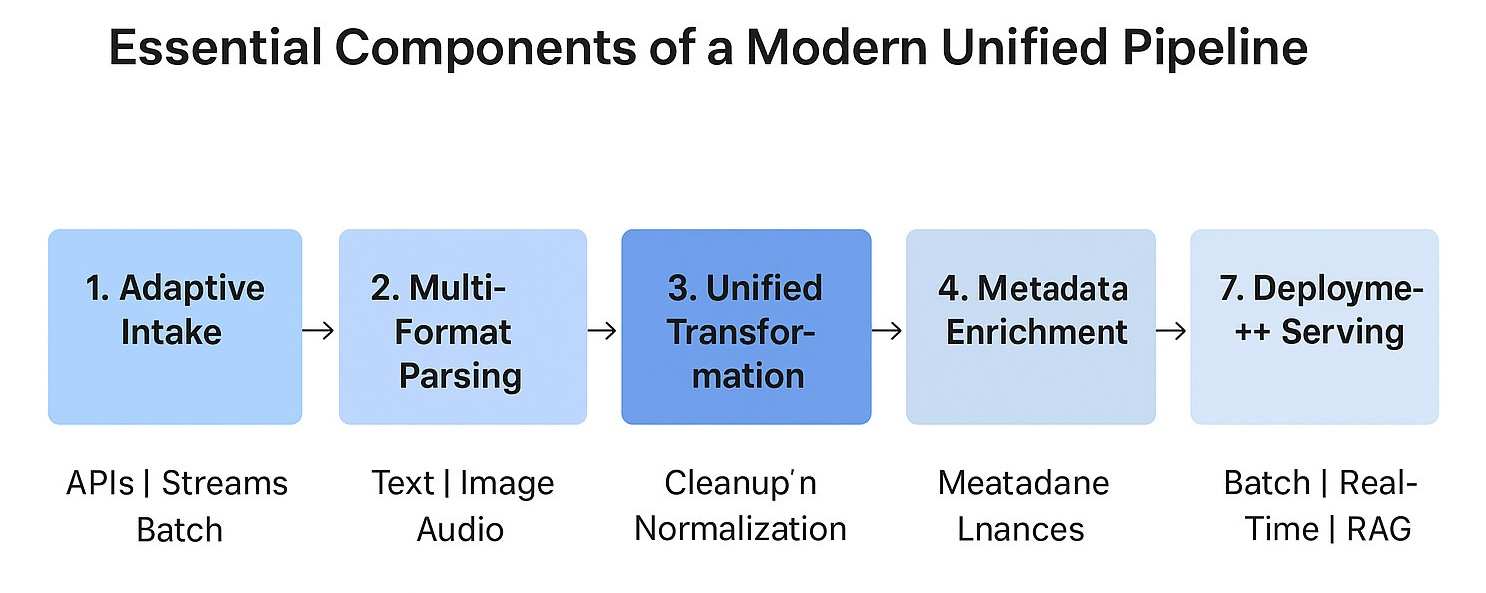
- Adaptive intake layers: These components accept data from various sources and convert it into a form that can be processed by the pipeline without requiring any format-specific rewriting.
- Cross-format extraction steps: Raw inputs are analyzed and reshaped so that downstream stages receive a consistent structure, even when the sources differ widely.
- Unified transformation logic: A set of common rules for normalization, cleanup, and shaping, which prevents divergence across modalities and stabilizes model behavior.
- Reliable metadata handling: The context remains consistent throughout the workflow, providing models with all the necessary information needed to interpret each output correctly.
These components work together to support a pipeline that can grow and develop in a manner that has well-defined boundaries.
How Unified Flows Improve Model Quality
Models benefit when their input data comes in a form that represents consistent preparation and timing. A unified flow of data brings a form of consistency where all sources are taken in the same sequence of checks, shaping steps, and routing logic. Variations that were seen due to format-specific preprocessing begin to disappear, which strengthens the signals models rely on during training.
Where there were conflicting inputs before, or where inputs were received in a misaligned manner, these inputs now support each other, which in turn enhances patterns and representation for the model. Also, as teams optimize their workflows, having united flows becomes a performance-booster rather than a hindrance.
Some organizations are now using Daft to manage various inputs using a single pipeline. This aims to relieve the strain created by disconnected workflows.
Operational Wins for Engineering Teams
Unified data flows represent a starting point rather than an endpoint for modern AI systems. As models grow more sophisticated and rely on richer combinations of inputs, demands on infrastructure are only likely to escalate. Pipelines that gracefully handle variation will set the course for how models in the next wave are constructed.
The focus is shifting towards environments that integrate new data types without requiring extensive rework and that scale within a single, coherent framework. Organizations that adopt early will find it easier to support complex workloads and keep pace with how quickly AI evolves.
Future Directions for Unified AI Infrastructure
Unified data flows are emerging as a defining feature of modern AI infrastructure. They offer a streamlined architecture that replaces fragmented workflows with a flexible structure that can accommodate additional data sources, volumes, and complexity.
Teams gain stability, clearer pathways for scaling, and a foundation that supports faster development. As AI complexity increases, pipelines built around a unified flow will set the course for how companies approach their most critical workloads.
Opinions expressed by DZone contributors are their own.
Comments