Amazon Q Developer for AI Infrastructure: Architecting Automated ML Pipelines
Master Amazon Q Developer for ML infrastructure. Automate SageMaker pipelines, optimize GPU resources, and accelerate AI development cycles.
Join the DZone community and get the full member experience.
Join For FreeThe landscape of Machine Learning Operations (MLOps) is shifting from manual configuration to AI-driven orchestration. As organizations scale their AI initiatives, the bottleneck is rarely the model architecture itself, but rather the underlying infrastructure required to train, deploy, and monitor these models at scale. Amazon Q Developer, a generative AI–powered assistant, has emerged as a critical tool for architects and engineers looking to automate the lifecycle of AI infrastructure.
Traditionally, setting up a robust ML pipeline involved complex Infrastructure as Code (IaC), intricate IAM permissioning, and manual tuning of compute resources like NVIDIA H100s or AWS Trainium. Amazon Q Developer streamlines this by translating high-level architectural requirements into production-ready scripts, optimizing resource allocation, and troubleshooting connectivity issues within the AWS ecosystem. This article explores the technical architecture of using Amazon Q for ML infrastructure and provides practical implementation strategies.
1. The Architectural Blueprint of Q-Assisted ML Pipelines
To understand how Amazon Q Developer automates ML pipelines, we must examine its integration points within the AWS Well-Architected Framework. Amazon Q operates as a management layer that interfaces with the AWS Cloud Control API, SageMaker, and CloudFormation/CDK.
In a typical automated ML architecture, Amazon Q acts as the “intelligence agent” that sits between the developer’s IDE and the target cloud environment. It doesn’t just suggest code snippets; it understands the context of ML workloads, such as data throughput requirements and memory-intensive training jobs.

This architecture ensures that the infrastructure is not a static set of scripts, but an evolving entity that can be refactored by Amazon Q based on performance metrics received from CloudWatch.
2. Automating Infrastructure as Code (IaC) for GPU Clusters
Provisioning high-performance compute clusters for deep learning is notoriously difficult. Misconfigurations in VPC subnets or security groups can lead to latency issues during distributed training (e.g., using Horovod or PyTorch Distributed Data Parallel). Amazon Q Developer excels at generating AWS CDK (Cloud Development Kit) code that follows best practices for networking and resource isolation.
When prompted to “Create a SageMaker pipeline with VPC-only access and GPU acceleration,” Amazon Q generates the necessary constructs to ensure that training traffic stays within the AWS backbone, reducing data transfer costs and increasing security.
Comparison: Manual vs. Q-Assisted Provisioning
| Feature | Manual Implementation | Q-Assisted Implementation |
|---|---|---|
| Resource Selection | Manual benchmarking of P4/P5 instances | AI-driven recommendation based on workload |
| IAM Policy Creation | Trial and error (Least Privilege) | Automated generation of scoped IAM roles |
| Networking | Manual VPC/Subnet/NAT Gateway setup | Pattern-based VPC architecture generation |
| Scaling | Static Auto-scaling policies | Dynamic scaling based on throughput projections |
3. Streamlining the Data Engineering Layer
ML pipelines are only as good as the data feeding them. Automating the ETL (Extract, Transform, Load) process is a primary use case for Amazon Q. It can generate AWS Glue jobs or Amazon EMR configurations that handle petabyte-scale data processing.
For example, if you need to partition a massive dataset in S3 by date and feature set, Amazon Q can provide the PySpark code necessary to optimize the storage layout for Athena queries. This reduces the time data scientists spend on “data plumbing” and allows them to focus on feature engineering.
import boto3
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
# This script demonstrates a Q-assisted SageMaker Pipeline definition
def create_ml_pipeline(role_arn, bucket_name):
# Initialize SageMaker Session
sagemaker_session = sagemaker.Session()
# Amazon Q assisted in generating this processing step configuration
# It ensures the use of the correct instance type for large-scale CSV processing
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.workflow.steps import ProcessingStep
# Define the processor
from sagemaker.sklearn.processing import SKLearnProcessor
sku_processor = SKLearnProcessor(
framework_version='0.23-1',
role=role_arn,
instance_type='ml.m5.xlarge',
instance_count=2,
base_job_name='data-prep-job'
)
# Step for Data Processing
step_process = ProcessingStep(
| name="PreprocessData", | processor=sku_processor, |
| --- | --- |
| inputs=[ProcessingInput(source=f"s3://{bucket_name}/raw/", destination="/opt/ml/processing/input")], | outputs=[ProcessingOutput(output_name="train", source="/opt/ml/processing/train")], |
| code="preprocess.py" # Script logic also assisted by Q | ) |
return Pipeline(name="AutomatedMLPipeline", steps=[step_process])4. Performance Optimization and Instance Selection
One of the most complex aspects of ML architecture is selecting the right instance type for the right task. Using the wrong instance can lead to throttled performance or excessive costs. Amazon Q Developer provides deep insights into instance families. It can suggest switching from ml.p3.2xlarge to ml.g5.2xlarge for certain inference workloads to achieve a better price-to-performance ratio.
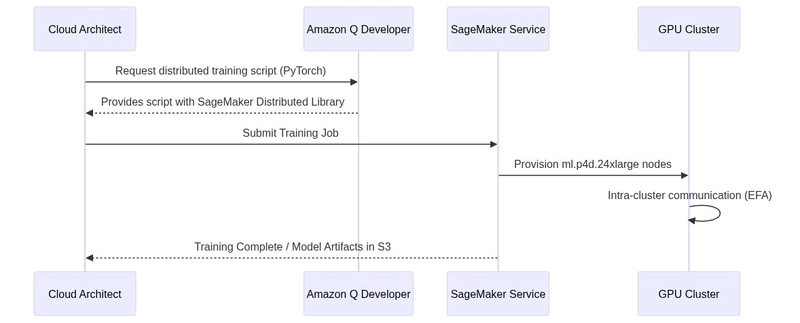
Distributed Training Sequence
The following sequence diagram illustrates how Amazon Q facilitates the setup of a distributed training job across multiple nodes.
{kind=link}
5. Security, Governance, and Compliance
In highly regulated industries (e.g., finance and healthcare), ML infrastructure must adhere to strict compliance standards such as HIPAA and PCI DSS. Amazon Q Developer helps by suggesting security configurations that developers might otherwise overlook, including:
- Encryption at rest: Automatically adding KMS key IDs to S3 buckets and EBS volumes
- Encryption in transit: Enabling inter-node encryption for distributed training jobs
- VPC endpoints: Generating configurations for interface VPC endpoints to avoid traversing the public internet
When reviewing existing IaC templates, Amazon Q can identify overly permissive IAM roles and suggest refined policies that restrict access to specific S3 prefixes or SageMaker resources.
6. Practical Use Case: Real-Time Inference Pipeline
Consider a scenario in which a retail company needs to deploy a recommendation engine. The architecture requires a SageMaker endpoint, an API Gateway, and a Lambda function for preprocessing.
Amazon Q Developer can generate the entire stack using the AWS Serverless Application Model (SAM). It provides the Swagger definition for the API, the Python code for the Lambda function (handling JSON validation), and the configuration for SageMaker Multi-Model Endpoints (MME) to save costs by hosting multiple models on a single instance.
Performance Considerations
- Cold Starts: Q can suggest Lambda Provisioned Concurrency settings based on expected traffic.
- Endpoint Latency: It can recommend enabling SageMaker Inference Recommender to find the optimal instance configuration for sub-100 ms latency.
Best Practices for Q-Driven ML Infrastructure
- Verify Generated Code: Always review AI-generated IaC in a sandbox environment before deploying to production.
- Contextual Prompting: Provide Q with specific constraints (e.g., “Use Graviton-based instances where possible”) to optimize for cost.
- Iterative Refinement: Use Q to refactor legacy ML pipelines. Ask it to “modernize this CloudFormation template to use AWS CDK v2.”
- Integrate with CI/CD: Use Q to generate GitHub Actions or AWS CodePipeline definitions that automate testing of your ML infrastructure.
Conclusion
Amazon Q Developer is transforming the role of the ML architect from a manual scriptwriter into a high-level system designer. By automating the boilerplate of infrastructure provisioning, security configuration, and performance tuning, Q allows teams to deploy models faster and with greater confidence. As generative AI continues to evolve, the integration between developer assistants and cloud infrastructure will become the standard for building the next generation of AI-powered applications.
Opinions expressed by DZone contributors are their own.
Comments