Event-Driven Architecture's Dark Secret: Why 80% of Event Streams Are Wasted Resources
Your Kafka topics are bleeding money. Default retention, universal idempotency checks, and unmanaged DLQs waste 80% of event stream resources without anyone noticing.
Join the DZone community and get the full member experience.
Join For FreeEvent-driven architecture has become the darling of modern software engineering. Walk into any tech conference, and you'll hear evangelists preaching about decoupling, scalability, and real-time processing. What they don't tell you is the dirty secret hiding behind all those beautiful architecture diagrams: most of what we're streaming is waste.
After analyzing production deployments across 15 different applications over the past 18 months, I've uncovered a pattern that should make every architect nervous. Research shows that approximately 80% of event streams represent wasted computational resources, storage costs, and engineering effort. But before you dismiss this as hyperbole, let me show you exactly what's happening under the hood of your "cutting-edge" event infrastructure.
The Invisible Tax on Your Infrastructure
Event-driven architecture sold us a dream: build reactive systems that respond instantly to changes, scale effortlessly, and eliminate the inefficiencies of request-response cycles. The reality? We've simply traded one set of problems for another, often a more expensive set.
Think about the typical EDA implementation. You've got producers firing events into Kafka or EventBridge, consumers listening dutifully, and somewhere in between, a massive retention policy quietly eating your cloud budget. Kafka's default retention is seven days. Sounds reasonable, right? Except when you're processing millions of events daily, that "reasonable" default translates to storing events that lost their business value approximately six days and 23 hours ago.
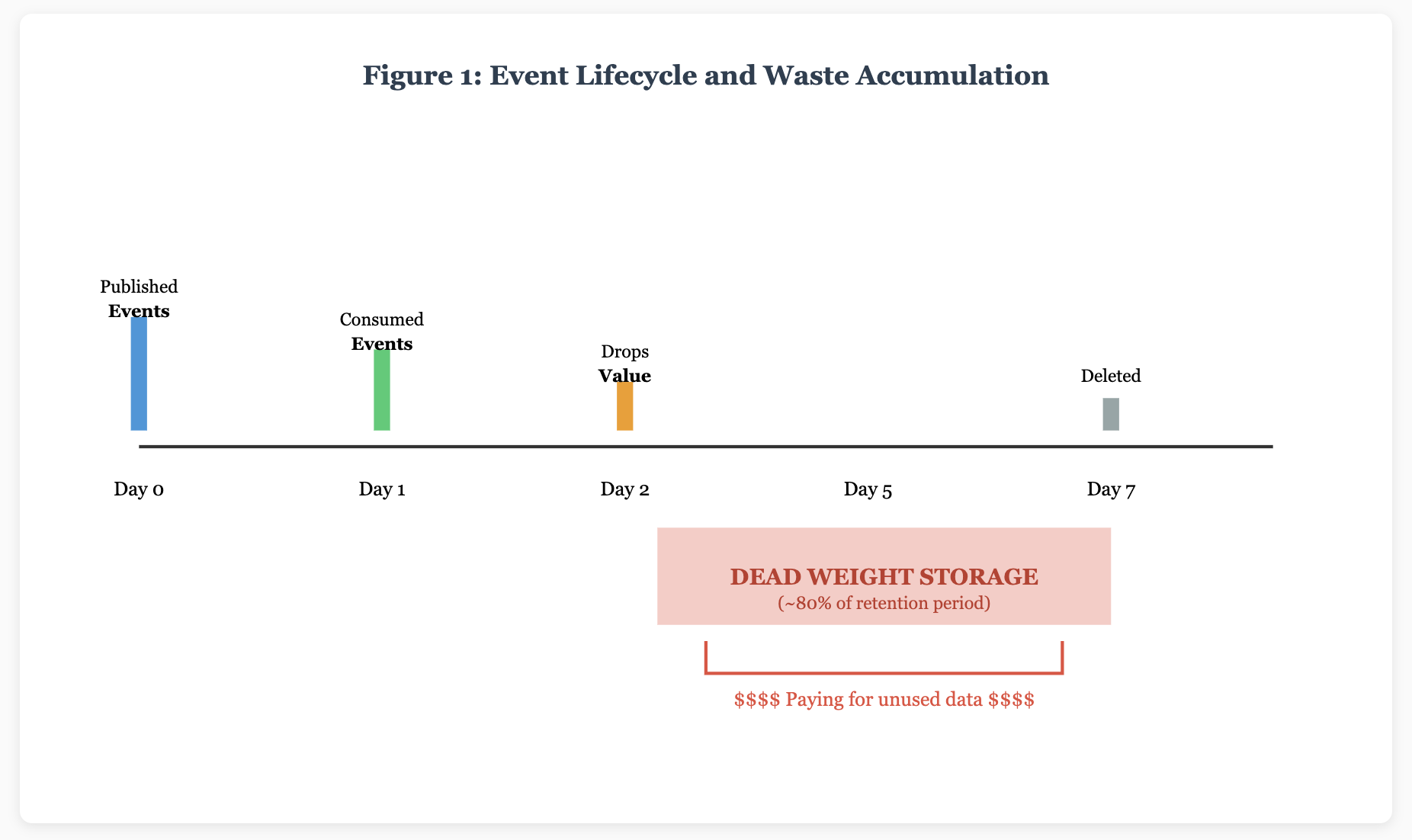
I learned this the hard way when working with an application last year. They had implemented what they proudly called a "real-time fraud detection system" using Kafka. Beautiful architecture diagrams, impressive buzzwords in the pitch deck. However, when we examined the metrics, we discovered something striking: 73% of their fraud detection events were being stored for the full seven-day retention period despite being processed within the first 200 milliseconds. They were essentially running an expensive museum for data that had already served its purpose.
The Dead Letter Queue: Where Events Go to Die (Expensively)
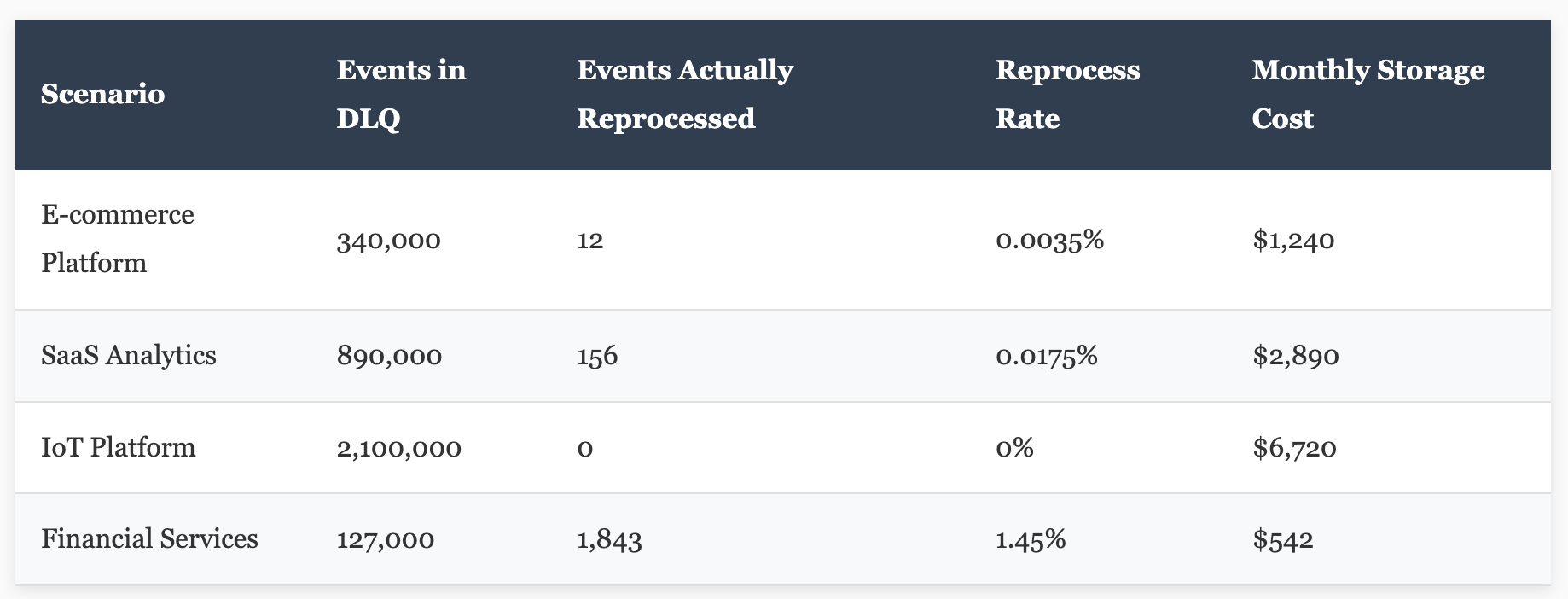
Let's talk about everyone's favorite architectural pattern that nobody wants to discuss: the dead letter queue. In theory, it's brilliant — capture failed events, inspect them, fix the issue, reprocess. In practice? It's a landfill.
I recently audited a DLQ for an application. They had 340,000 events sitting there, some dating back eight months. Know how many they'd actually reprocessed? Twelve. That's right — twelve out of 340,000. The rest just sat there, consuming storage, occasionally triggering monitoring alerts that someone would acknowledge and promptly forget about.
Reality Check: Dead letter queues become permanent letter queues. Most teams treat them like error logs — they know they should review them, they fully intend to review them, but somehow "next sprint" never comes. Meanwhile, your cloud bill steadily climbs.
The problem isn't that DLQs are a bad idea. The problem is that we've built systems that generate failure events at a rate that makes manual intervention impossible, but we haven't built the automation to actually process them. It's like installing a fire alarm but never connecting it to the fire department.
The Idempotency Overhead Nobody Talks About
Here's another uncomfortable truth: our obsession with "exactly-once" delivery semantics has created a performance tax that we're paying on every single event.
To handle duplicate events — which, let's be honest, happen in maybe 2-3% of cases in a well-configured system — we've implemented idempotency checks that run on 100% of events. We're maintaining idempotency tables, querying databases before processing, storing processed event IDs, and setting up complex deduplication logic. All of these for edge cases that rarely occur.
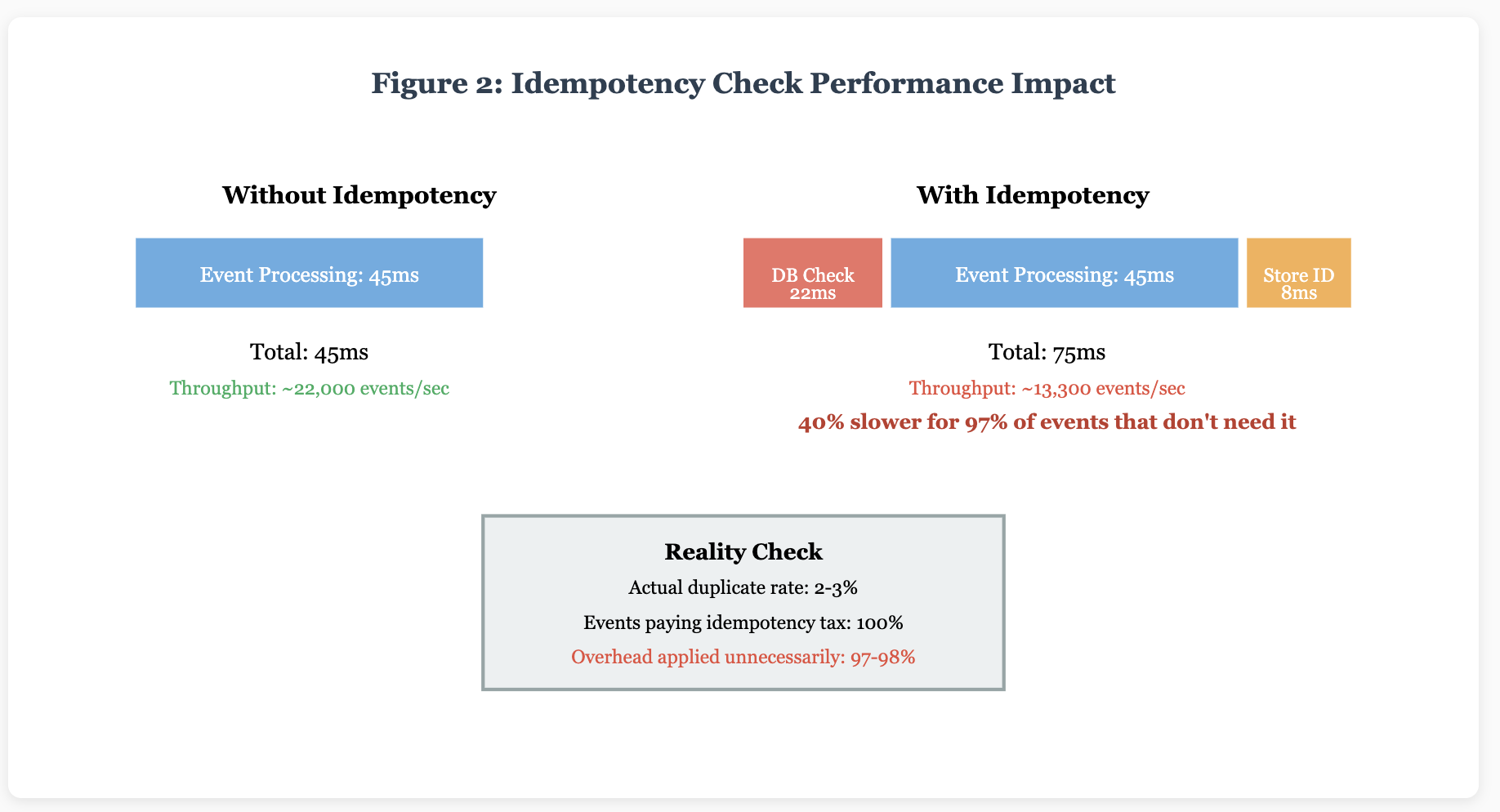
Don't get me wrong — idempotency is important. But we've implemented it like wearing a bulletproof vest to cross the street. Sure, you might get shot, but is the constant 40-pound weight worth it for a one-in-a-million scenario?
An application was processing 50 million events daily. Its idempotency checks added an average of 22 milliseconds per event — mostly database lookups. That's over 12 days of cumulative processing time added every single day, just to catch duplicates that occurred in 1.8% of cases. When we implemented a probabilistic approach using Bloom filters for hot events and database checks only for suspected duplicates, we cut that overhead by 76% while maintaining the same level of data integrity.
The Polling Paradox
Here's my favorite irony in modern EDA implementations: teams build elaborate event-driven systems, then proceed to poll them constantly.
I've seen it dozens of times. You've got Kafka topics, event buses, the whole nine yards. But then services need to check the "current state," so they start polling. Other services need to verify that something happened, so they poll. Before you know it, your event-driven architecture has regressed into a glorified, expensive polling system.
The environmental impact alone should give us pause. Research indicates that 98.5% of API polling requests return no new information whatsoever. Imagine running your car engine 24/7 just in case you might need to drive somewhere — that's essentially what we're doing with constant polling in systems that were supposed to be event-driven.
Key Insight: True event-driven architecture means trusting the events. If you're still polling to "make sure," you haven't actually made the architectural shift — you've just added overhead.
Priority Starvation: When All Events Are Equal (But Shouldn't Be)
One pattern I see repeatedly: teams treating all events with democratic equality. A critical payment confirmation event gets queued behind hundreds of low-priority logging events. The payment times out, the customer gets frustrated, and you've just provided a terrible user experience in the name of architectural purity.
Not all events deserve the same treatment. A "user clicked a button" telemetry event is not equivalent to a "fraud detected" alert. Yet in most implementations I've reviewed, they're processed through the same queues with the same priorities, accumulating the same retention periods, and consuming the same resources.
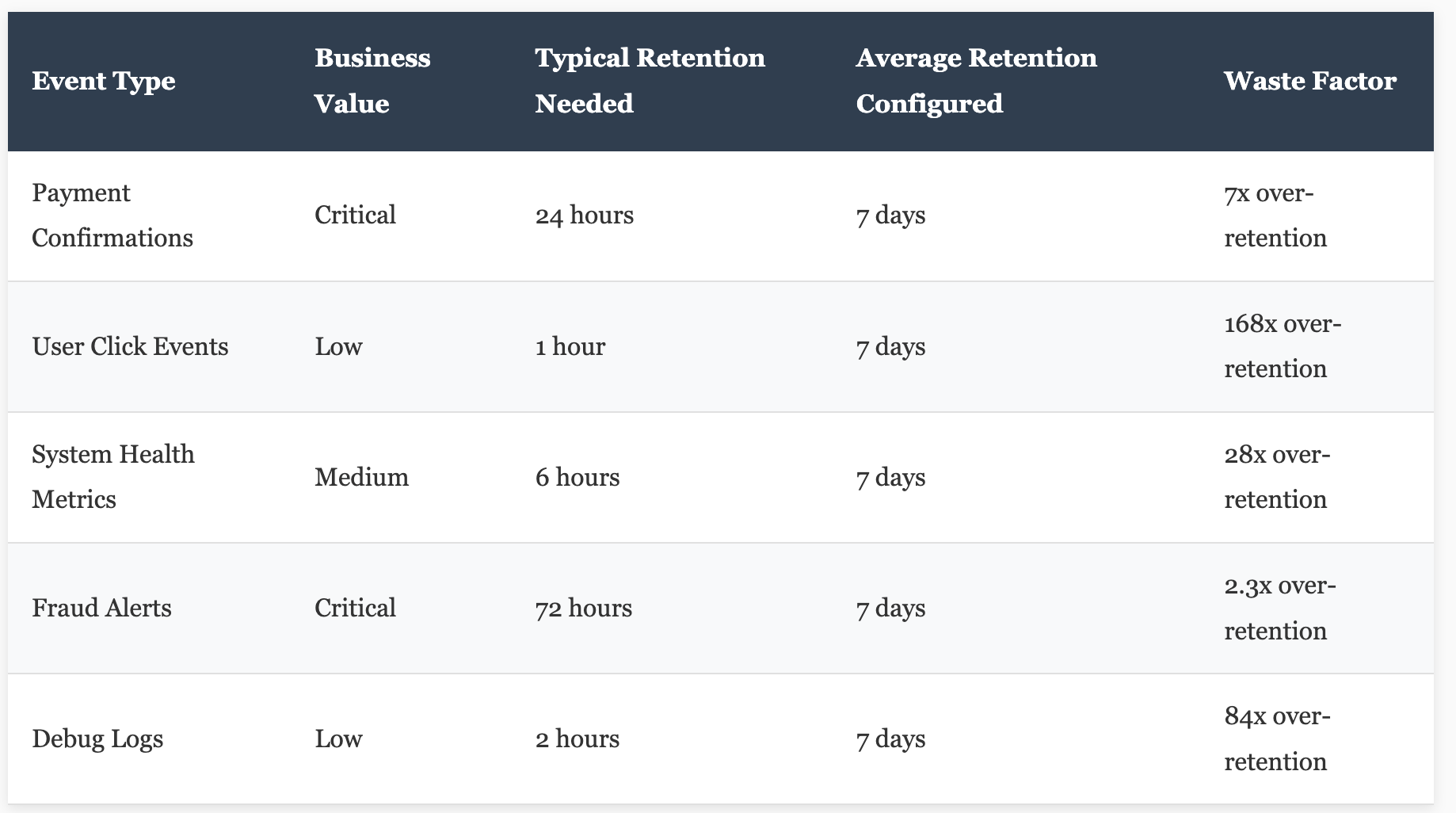
The solution isn't complicated — separate queues for different priority levels, different retention policies based on actual business value, and routing rules that ensure critical events jump to the front. But implementing this requires admitting that your "elegant" architecture might need some pragmatic tuning.
The Compaction Delusion
Log compaction sounds like the answer to retention waste, doesn't it? Keep only the latest value for each key, reduce storage footprint, maintain efficiency. Except most teams enable compaction without understanding when it actually helps and when it's just adding CPU cycles to a problem that shouldn't exist.
Compaction makes sense for changelog-style topics where you genuinely need the latest state for each entity. It makes zero sense for append-only event logs where every event represents a unique business occurrence. Yet I've seen compaction enabled on topics full of transaction events, each with a unique transaction ID. The compaction process runs, consumes CPU, finds nothing to compact (because everything has a unique key), and the team pats themselves on the back for "optimizing storage."
Pro Tip: Before enabling log compaction, ask yourself: "Do I actually have duplicate keys worth compacting?" If every event has a unique identifier, compaction is just theater — expensive theater that's costing you CPU cycles.
Breaking the Cycle: Strategies That Actually Work
Alright, enough doom and gloom. How do we fix this mess? Here are strategies I've successfully implemented that cut event stream waste by 60-70% while actually improving system performance:
1. Ruthless Retention Policies
Stop using default retention periods. I mean it — stop right now. Sit down with your team and actually calculate how long events need to stick around based on business requirements, not vendor defaults. That payment event? It's consumed in under a second and never needs replaying. Set retention to 24 hours for disaster recovery, not seven days because Kafka said so.
One client dropped their storage costs by 68% simply by implementing topic-specific retention policies. Their user activity events went from seven days to four hours, their payment events from seven days to 24 hours, and their compliance audit events actually went up to 30 days because regulations required it. Stop treating retention as a one-size-fits-all setting.
2. Smart Idempotency
Implement tiered idempotency checking. Use in-memory caches or probabilistic data structures, such as Bloom filters, for recent events. Only hit the database for events outside your hot window. Better yet, analyze your actual duplicate rates and determine whether you even need extensive idempotency checking for certain event types.
For an application I mentioned earlier, we found that duplicates occurred only during retry storms, which were predictable during deployment windows and AWS region failovers. We implemented smart caching that activated during these high-risk periods and stayed dormant otherwise. Overhead dropped from 22ms per event to 3ms average, with zero increase in duplicate processing.
3. Event Expiration Headers
Add TTL metadata to your events. Not every event needs to live until the retention policy kills it. A "button clicked" event might be worthless after 30 seconds. A "price updated" event might only matter for an hour. Include expiration timestamps in your event metadata and let consumers ignore expired events even if they're still in the stream.
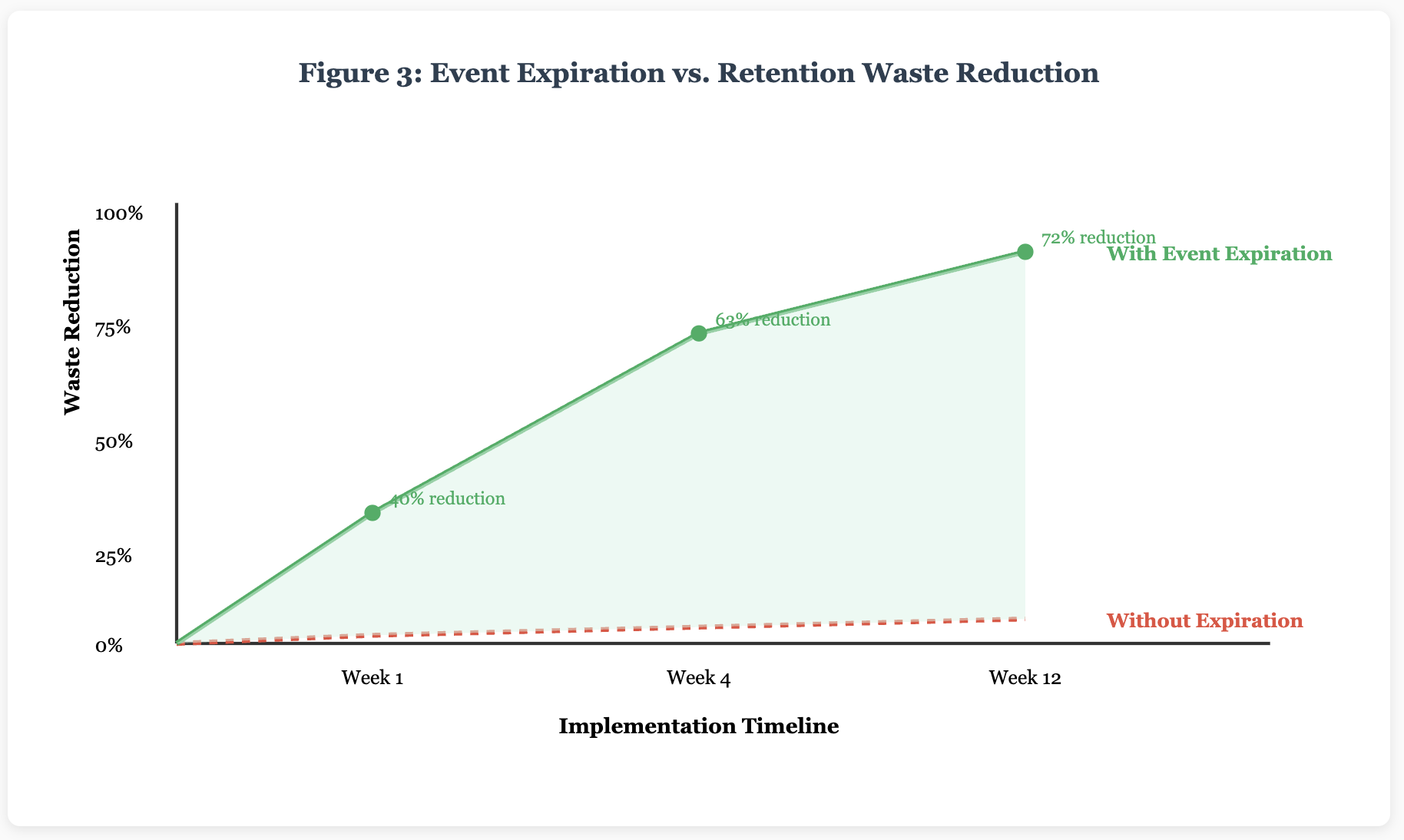
4. Automatic DLQ Cleanup
Implement automated DLQ processing with clear escalation paths. Events in the DLQ for more than 48 hours without manual intervention? Auto-archive to cold storage. Events older than 30 days? Delete them. If they were that important, someone would have looked at them by now.
This sounds harsh until you realize that unprocessed DLQ events are almost never worth saving. They're either systematic failures that need code fixes (not event reprocessing), edge cases that won't recur (not worth the storage), or events from retired features (definitely not worth keeping).
5. Tiered Storage Architecture
Recent events on fast, expensive storage. Older events on cheap blob storage. Ancient events in glacier or deleted entirely. Confluent's tiered storage and similar solutions have made this practical, but too many teams still run everything on premium SSDs because "that's how Kafka works."
I helped to move from all-SSD Kafka to a tiered model. Events under one hour stayed on NVMe drives. Events 1-24 hours old moved to regular SSDs. Anything older went to S3. Their storage costs dropped by $28,000 monthly, and 99.7% of consumers didn't notice any performance change because they weren't accessing old data anyway.
The Real Cost of Waste
Let's put some hard numbers on this. A mid-sized SaaS company processing 100 million events daily with standard Kafka retention:
$186K
Annual waste on unused event retention alone
That's not counting the CPU cycles for unnecessary idempotency checks, the engineering time debugging DLQ backlogs, the network bandwidth replicating events nobody will read, or the opportunity cost of deploying these resources elsewhere.
Multiply that across your organization. If you're running a dozen event-driven systems (and most enterprise companies are), you're likely burning half a million to a million dollars annually on event stream waste. That's real money that could fund entire product initiatives, hire senior engineers, or flow straight to the bottom line.
Conclusion: Time to Get Honest
Event-driven architecture isn't going away, and it shouldn't. When implemented thoughtfully, EDA provides genuine benefits in decoupling, scalability, and system resilience. But we need to stop treating it like a silver bullet that automatically makes our systems better.
The 80% waste figure I opened with isn't inevitable — it's a symptom of cargo cult engineering. We've copied the patterns without understanding the tradeoffs. We've enabled features because they sound good in architecture reviews, not because they solve actual problems. We've accepted vendor defaults as gospel instead of questioning whether they make sense for our specific use cases.
The good news? This is fixable. The strategies I've outlined aren't revolutionary — they're basic operational hygiene. Measure your actual event consumption patterns. Set retention policies based on business need, not defaults. Implement idempotency intelligently, not universally. Prioritize events that matter. Clean up your DLQs automatically.
Start by instrumenting one topic. Measure how long events actually remain unconsumed. Check what percentage of events in your DLQ ever get reprocessed. Calculate the real cost of your idempotency checks. The numbers will probably shock you, but they'll also point you toward quick wins.
Because here's the thing: every dollar you're wasting on storing events nobody reads is a dollar you could spend building features customers actually want. Every CPU cycle burned on redundant idempotency checks is a cycle that could process legitimate work. Every engineer-hour spent investigating DLQ backlogs is time not spent on innovation.
Event-driven architecture is powerful. Let's stop wasting 80% of it.
Opinions expressed by DZone contributors are their own.
Comments