Event-Driven Data Management for Microservices
Learn about event-driven data management for microservices in the fifth article in our series on microservices app development. We'll explore the problem of distributed data management, event-driven architecture, and atomicity.
Join the DZone community and get the full member experience.
Join For FreeThis is the fifth article in a series about building applications with microservices. The first article introduces the Microservices Architecture pattern and discusses the benefits and drawbacks of using microservices. The second and third articles in the series describe different aspects of communication within a microservices architecture. The fourth article explores the closely related problem of service discovery. In this article, we change gears and look at the distributed data management problems that arise in a microservices architecture.
The other articles currently available in this seven-part series are:
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture
- Service Discovery in a Microservices Architecture
Microservices and the Problem of Distributed Data Management
A monolithic application typically has a single relational database. A key benefit of using a relational database is that your application can use ACID transactions, which provide some important guarantees:
- Atomicity – Changes are made atomically
- Consistency – The state of the database is always consistent
- Isolation – Even though transactions are executed concurrently it appears they are executed serially
- Durable – Once a transaction has committed it is not undone
As a result, your application can simply begin a transaction, change (insert, update, and delete) multiple rows, and commit the transaction.
Another great benefit of using a relational database is that it provides SQL, which is a rich, declarative, and standardized query language. You can easily write a query that combines data from multiple tables. The RDBMS query planner then determines the most optimal way to execute the query. You don’t have to worry about low-level details such as how to access the database. And, because all of your application’s data is in one database, it is easy to query.
Unfortunately, data access becomes much more complex when we move to a microservices architecture. That is because the data owned by each microservice is private to that microservice and can only be accessed via its API. Encapsulating the data ensures that the microservices are loosely coupled and can evolve independently of one another. If multiple services access the same data, schema updates require time consuming, coordinated updates to all of the services.
To make matters worse, different microservices often use different kinds of databases. Modern applications store and process diverse kinds of data and a relational database is not always the best choice. For some use cases, a particular NoSQL database might have a more convenient data model and offer much better performance and scalability. For example, it makes sense for a service that stores and queries text to use a text search engine such as Elasticsearch. Similarly, a service that stores social graph data should probably use a graph database, such as Neo4j. Consequently, microservices-based applications often use a mixture of SQL and NoSQL databases, the so-called polyglot persistence approach.
A partitioned, polyglot-persistent architecture for data storage has many benefits, including loosely coupled services and better performance and scalability. However, it does introduce some distributed data management challenges.
The first challenge is how to implement business transactions that maintain consistency across multiple services. To see why this is a problem, let’s take a look at an example of an online B2B store. The Customer Service maintains information about customers, including their credit lines. The Order Service manages orders and must verify that a new order doesn’t violate the customer’s credit limit. In the monolithic version of this application, the Order Service can simply use an ACID transaction to check the available credit and create the order.
In contrast, in a microservices architecture the ORDER and CUSTOMER tables are private to their respective services, as shown in the following diagram.
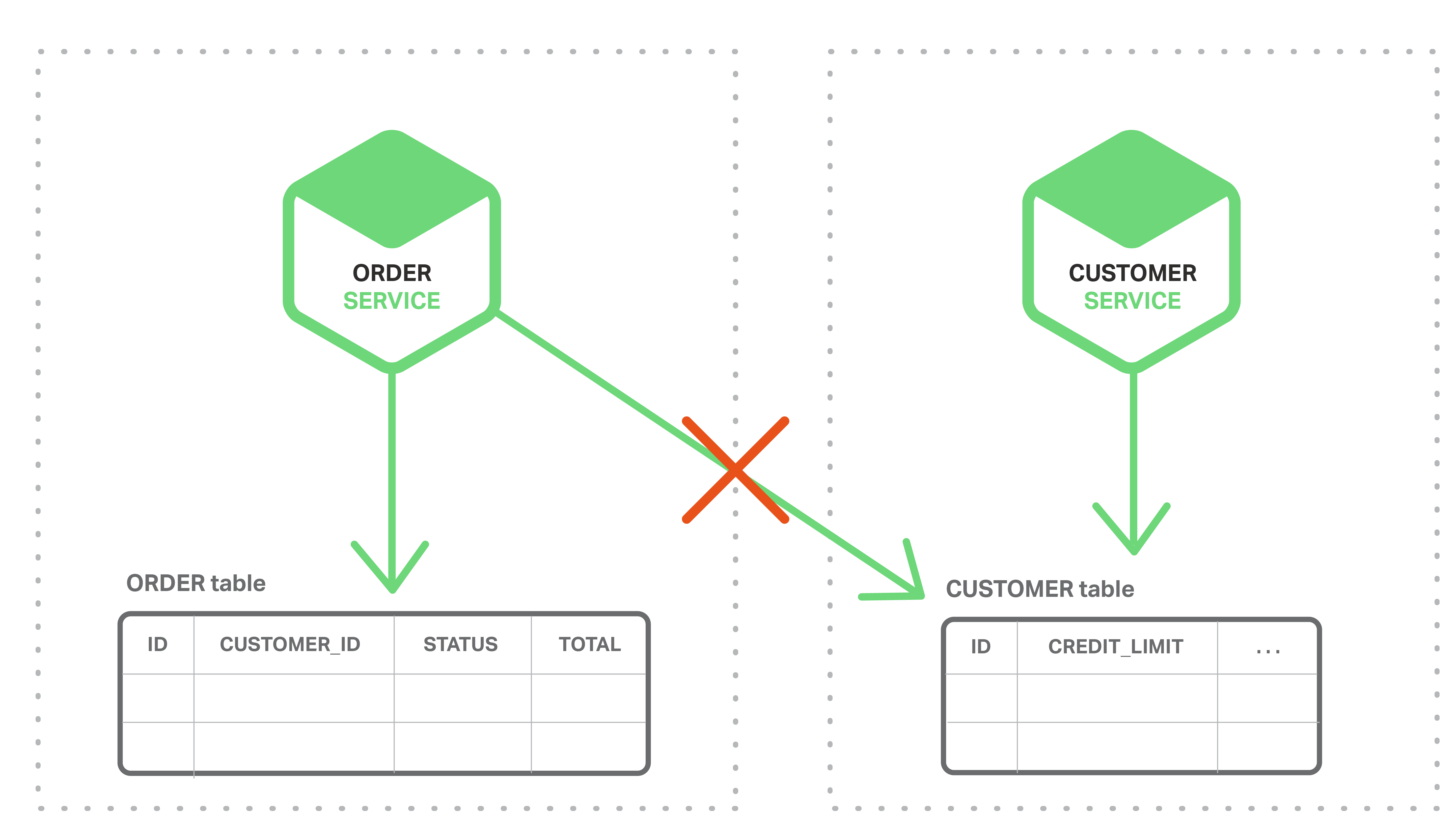
The Order Service cannot access the CUSTOMER table directly. It can only use the API provided by the Customer Service. The Order Service could potentially use distributed transactions, also known as two-phase commit (2PC). However, 2PC is usually not a viable option in modern applications. The CAP theorem requires you to choose between availability and ACID-style consistency, and availability is usually the better choice. Moreover, many modern technologies, such as most NoSQL databases, do not support 2PC. Maintaining data consistency across services and databases is essential, so we need another solution.
The second challenge is how to implement queries that retrieve data from multiple services. For example, let’s imagine that the application needs to display a customer and his recent orders. If the Order Service provides an API for retrieving a customer’s orders then you can retrieve this data using an application-side join. The application retrieves the customer from the Customer Service and the customer’s orders from the Order Service. Suppose, however, that the Order Service only supports the lookup of orders by their primary key (perhaps it uses a NoSQL database that only supports primary key-based retrievals). In this situation, there is no obvious way to retrieve the needed data.
Event-Driven Architecture
For many applications, the solution is to use an event-driven architecture. In this architecture, a microservice publishes an event when something notable happens, such as when it updates a business entity. Other microservices subscribe to those events. When a microservice receives an event it can update its own business entities, which might lead to more events being published.
You can use events to implement business transactions that span multiple services. A transaction consists of a series of steps. Each step consists of a microservice updating a business entity and publishing an event that triggers the next step. The following sequence of diagrams shows how you can use an event-driven approach to checking for available credit when creating an order. The microservices exchange events via a Message Broker.
The Order Service creates an Order with status NEW and publishes an Order Created event.
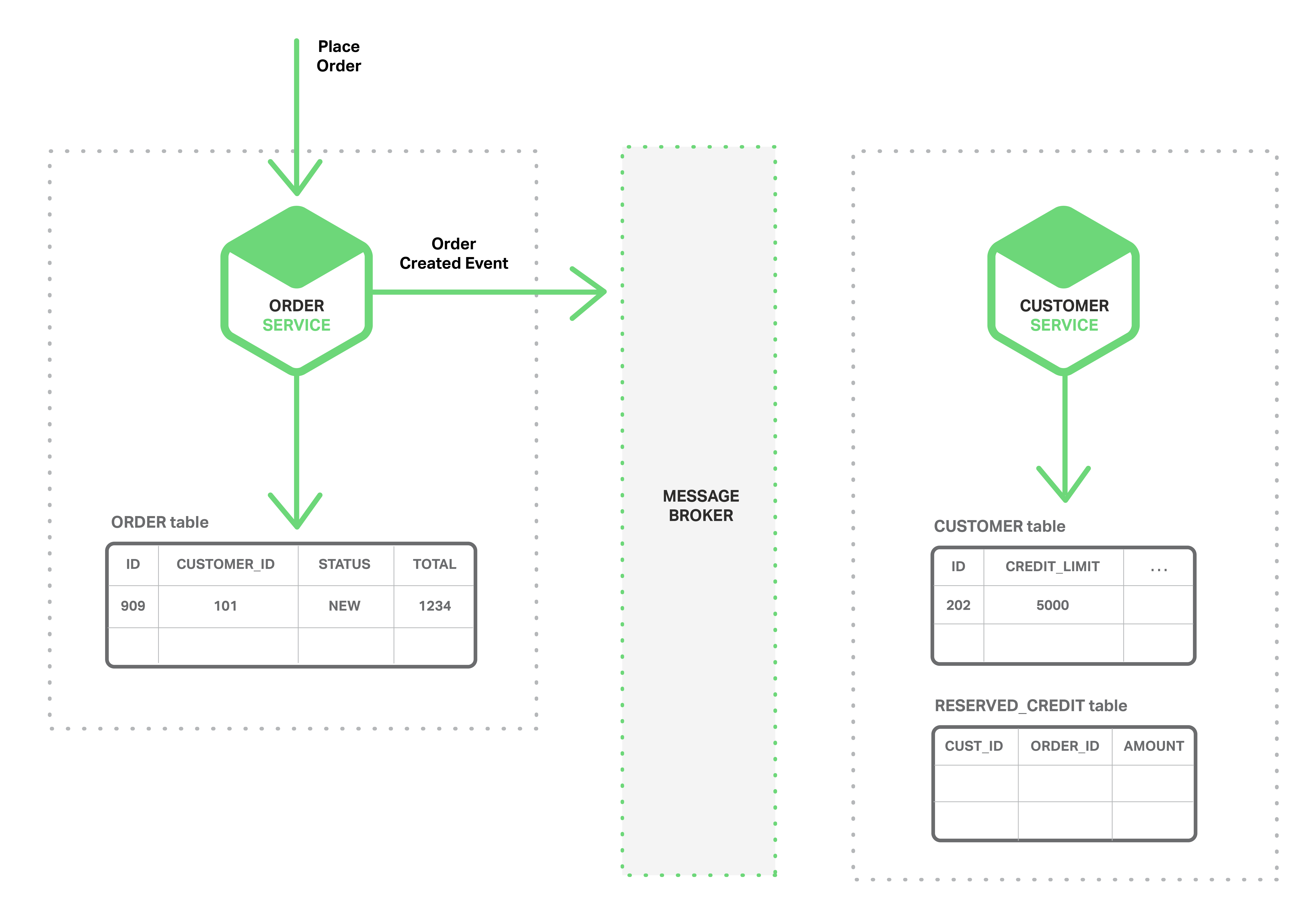
- The Customer Service consumes the Order Created event, reserves credit for the order, and publishes a Credit Reserved event.
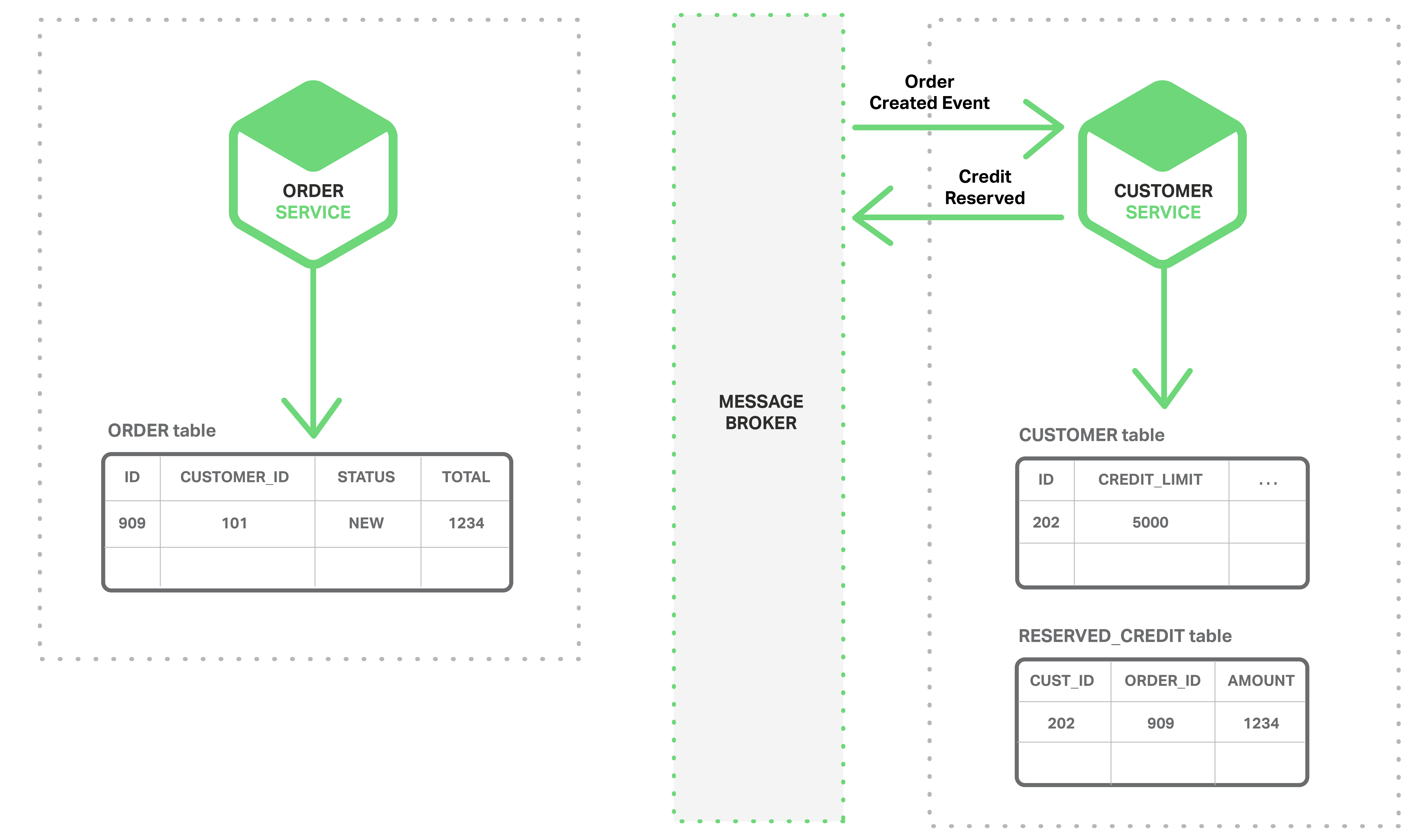
- The Order Service consumes the Credit Reserved event, and changes the status of the order to OPEN.
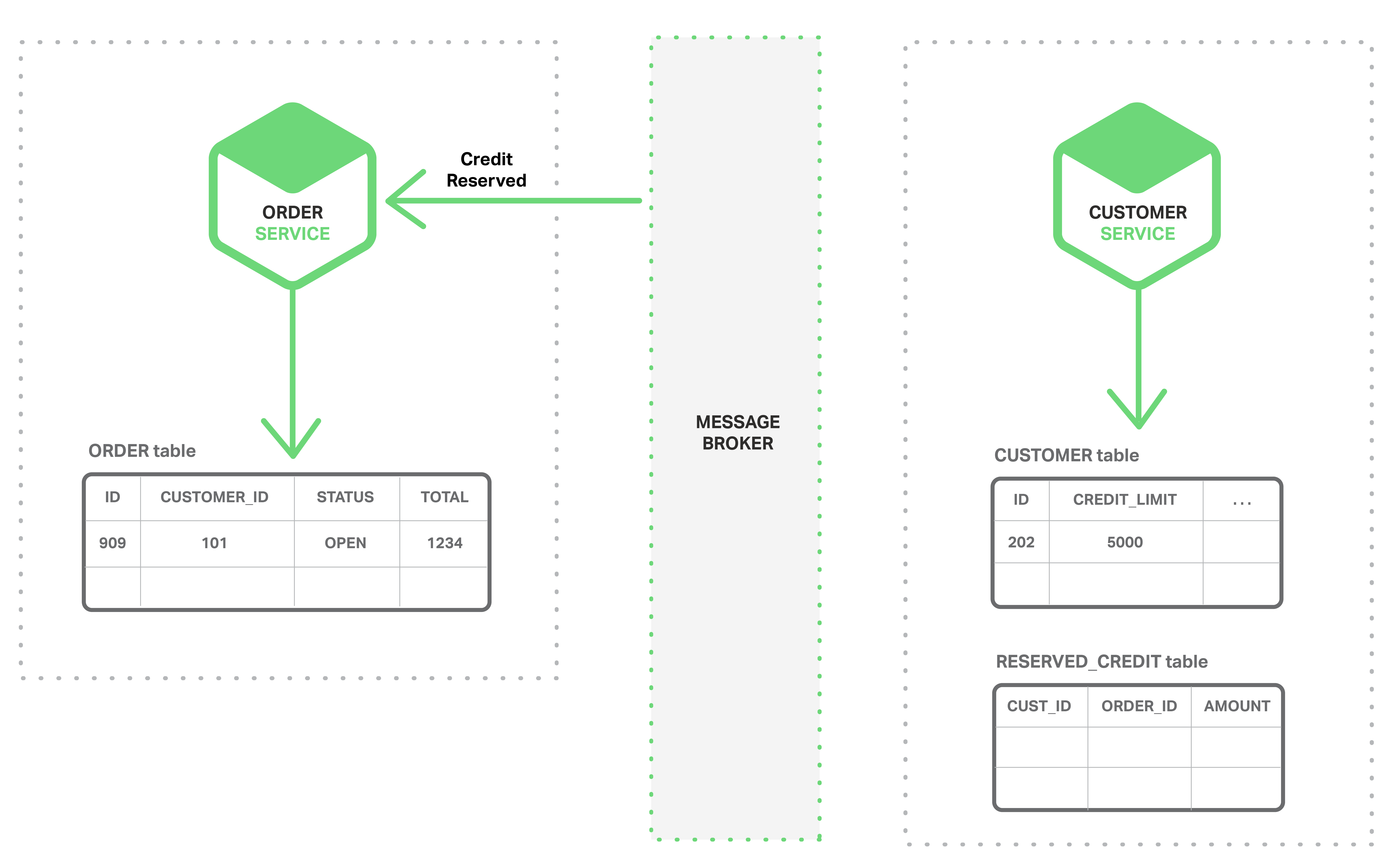
A more complex scenario could involve additional steps, such as reserving inventory at the same time the customer’s credit is checked.
Provided that (a) each service atomically updates the database and publishes an event – more on that later – and (b) the Message Broker guarantees that events are delivered at least once, then you can implement business transactions that span multiple services. It is important to note that these are not ACID transactions. They offer much weaker guarantees such as eventual consistency. This transaction model has been referred to as the BASE model.
You can also use events to maintain materialized views that pre-join data owned by multiple microservices. The service that maintains the view subscribes to the relevant events and updates the view. For example, the Customer Order View Updater Service that maintains a Customer Orders view subscribes to the events published by the Customer Service and Order Service.
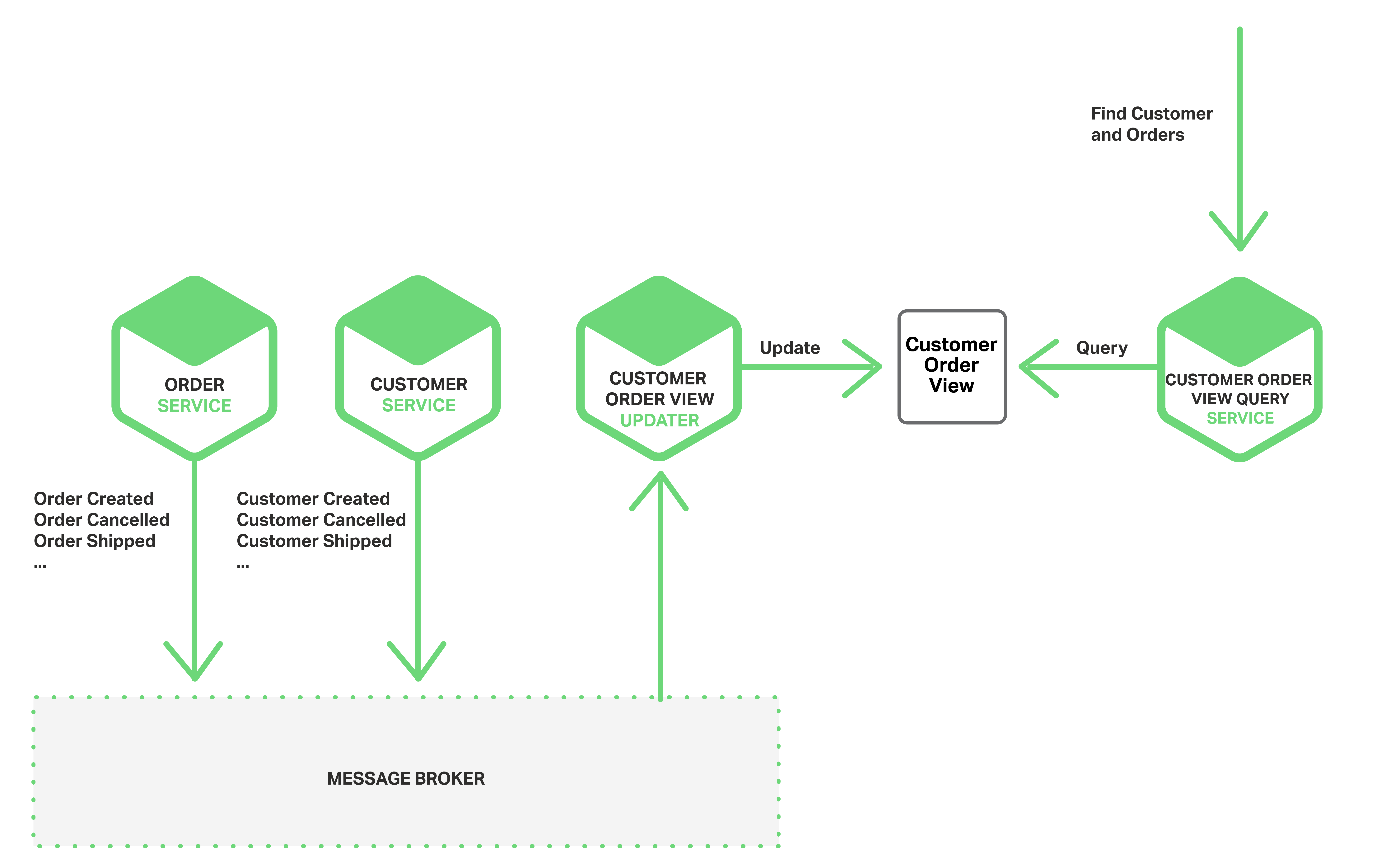
When the Customer Order View Updater Service receives a Customer or Order event, it updates the Customer Order View datastore. You could implement the Customer Order View using a document database such as MongoDB and store one document for each Customer. The Customer Order View Query Service handles requests for a customer and recent orders by querying the Customer Order View datastore.
An event-driven architecture has several benefits and drawbacks. It enables the implementation of transactions that span multiple services and provide eventual consistency. Another benefit is that it also enables an application to maintain materialized views. One drawback is that the programming model is more complex than when using ACID transactions. Often you must implement compensating transactions to recover from application-level failures; for example, you must cancel an order if the credit check fails. Also, applications must deal with inconsistent data. That is because changes made by in-flight transactions are visible. The application can also see inconsistencies if it reads from a materialized view that is not yet updated. Another drawback is that subscribers must detect and ignore duplicate events.
Achieving Atomicity
In an event-driven architecture there is also the problem of atomically updating the database and publishing an event. For example, the Order Service must insert a row into the ORDER table and publish an Order Created event. It is essential that these two operations are done atomically. If the service crashes after updating the database but before publishing the event, the system becomes inconsistent. The standard way to ensure atomicity is to use a distributed transaction involving the database and the Message Broker. However, for the reasons described above such as the CAP theorem, this is exactly what we do not want to do.
Publishing Events Using Local Transactions
One way to achieve atomicity is for the application to publish events using a multi-step process involving only local transactions. The trick is to have an EVENT table, which functions as a message queue, in the database that stores the state of the business entities. The application begins a (local) database transaction, updates the state of the business entities, inserts an event into the EVENT table, and commits the transaction. A separate application thread or process queries the EVENT table, publishes the events to the Message Broker, and then uses a local transaction to mark the events as published. The following diagram shows the design.
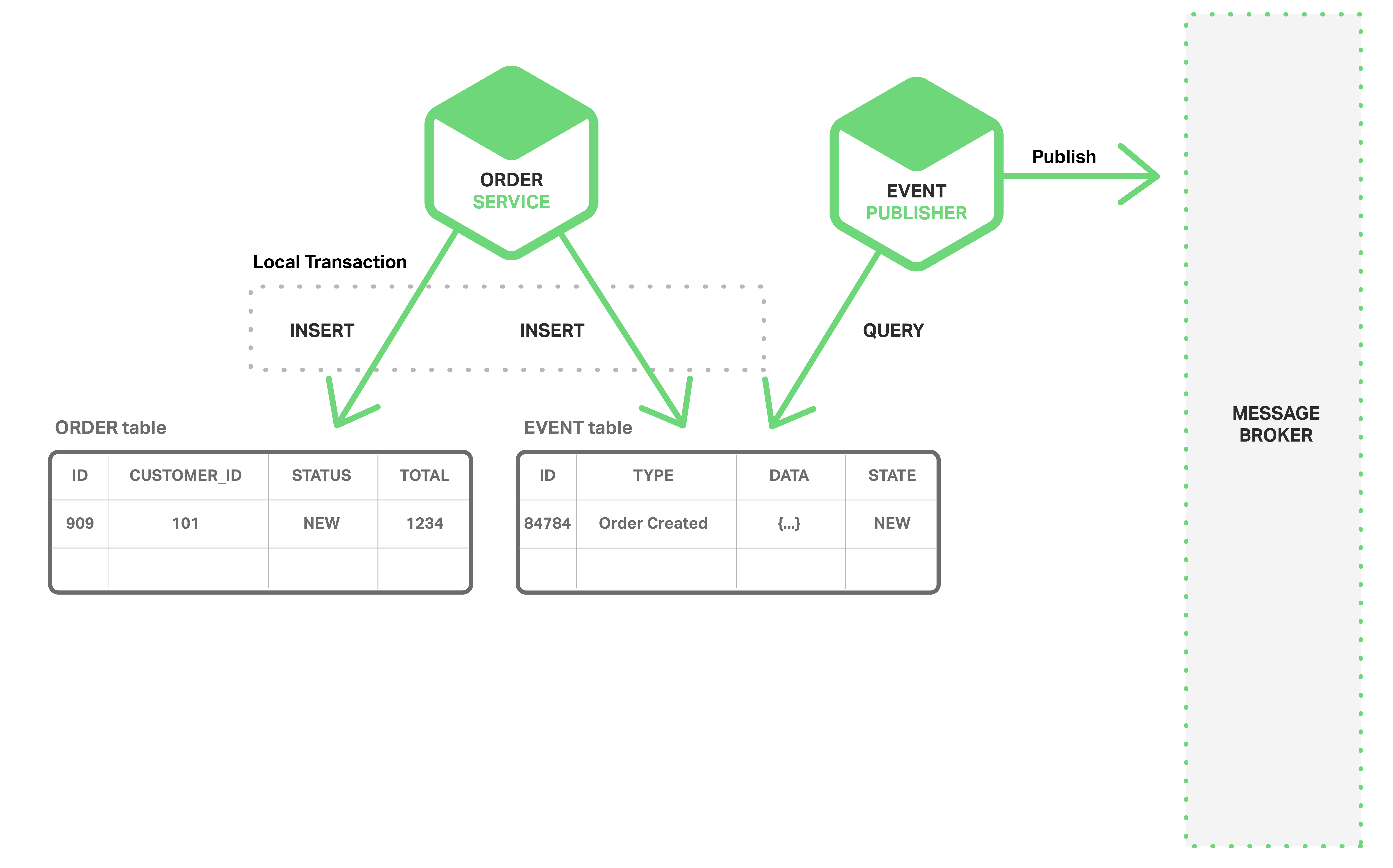
The Order Service inserts a row into the ORDER table and inserts an Order Created event into the EVENT table. The Event Publisher thread or process queries the EVENT table for unpublished events, publishes the events, and then updates the EVENT table to mark the events as published.
This approach has several benefits and drawbacks. One benefit is that it guarantees an event is published for each update without relying on 2PC. Also, the application publishes business-level events, which eliminates the need to infer them. One drawback of this approach is that it is potentially error-prone since the developer must remember to publish events. A limitation of this approach is that it is challenging to implement when using some NoSQL databases because of their limited transaction and query capabilities.
This approach eliminates the need for 2PC by having the application use local transactions to update state and publish events. Let’s now look at an approach that achieves atomicity by having the application simply update state.
Mining a Database Transaction Log
Another way to achieve atomicity without 2PC is for the events to be published by a thread or process that mines the database’s transaction or commit log. The application updates the database, which results in changes being recorded in the database’s transaction log. The Transaction Log Miner thread or process reads the transaction log and publishes events to the Message Broker. The following diagram shows the design.
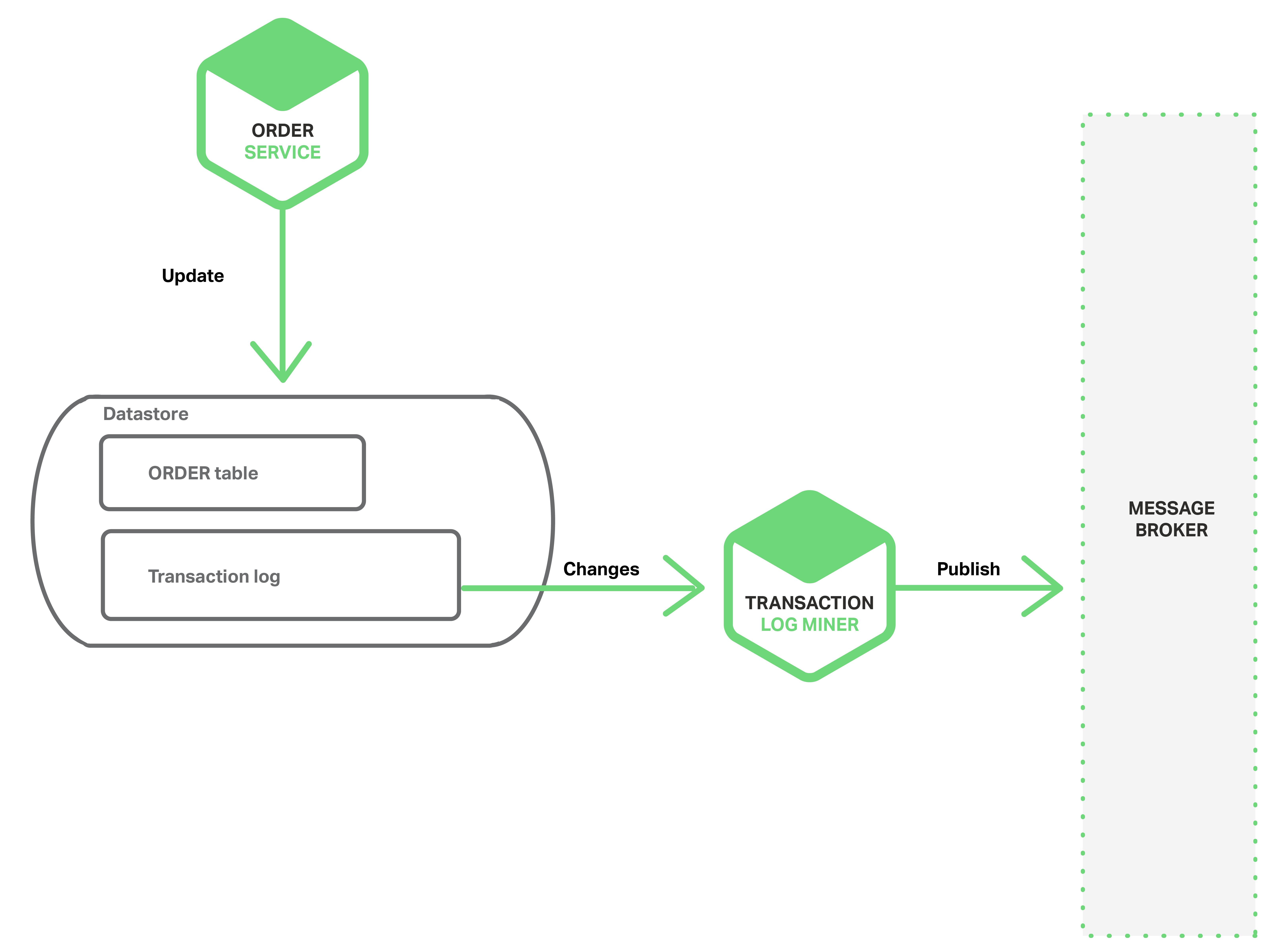
A example of this approach is the open source LinkedIn Databus project. Databus mines the Oracle transaction log and publishes events corresponding to the changes. Linkedin uses Databus to keep various derived data stores consistent with the system of record.
Another example is the streams mechanism in AWS DynamoDB, which is a managed NoSQL database. A DynamoDB stream contains the time-ordered sequence of changes (create, update, and delete operations) made to the items in a DynamoDB table in the last 24 hours. An application can read those changes from the stream and, for example, publish them as events.
Transaction log mining has various benefits and drawbacks. One benefit is that it guarantees that an event is published for each update without using 2PC. Transaction log mining can also simplify the application by separating event publishing from the application’s business logic. A major drawback is that the format of the transaction log is proprietary to each database and can even change between database versions. Also, it can be difficult to reverse engineer the high-level business events from the low-level updates recorded in the transaction log.
Transaction log mining eliminates the need for 2PC by having the application do one thing: update the database. Let’s now look at a different approach that eliminates the updates and relies solely on events.
Using Event Sourcing
Event sourcing achieves atomicity without 2PC by using a radically different, event-centric approach to persisting business entities. Rather than store the current state of an entity, the application stores a sequence of state-changing events. The application reconstructs an entity’s current state by replaying the events. Whenever the state of a business entity changes, a new event is appended to the list of events. Since saving an event is a single operation, it is inherently atomic.
To see how event sourcing works, consider the Order entity as an example. In a traditional approach, each order maps to a row in an ORDER table and to rows in, for example, an ORDER_LINE_ITEM table. But when using event sourcing, the Order Service stores an Order in the form of its state-changing events: Created, Approved, Shipped, Cancelled. Each event contains sufficient data to reconstruct the Order’s state.
Events persist in an Event Store, which is a database of events. The store has an API for adding and retrieving an entity’s events. The Event Store also behaves like the Message Broker in the architectures we described previously. It provides an API that enables services to subscribe to events. The Event Store delivers all events to all interested subscribers. The Event Store is the backbone of an event-driven microservices architecture.
Event sourcing has several benefits. It solves one of the key problems in implementing an event-driven architecture and makes it possible to reliably publish events whenever state changes. As a result, it solves data consistency issues in a microservices architecture. Also, because it persists events rather than domain objects, it mostly avoids the object‑relational impedance mismatch problem. Event sourcing also provides a 100% reliable audit log of the changes made to a business entity, and makes it possible to implement temporal queries that determine the state of an entity at any point in time. Another major benefit of event sourcing is that your business logic consists of loosely coupled business entities that exchange events. This makes it a lot easier to migrate from a monolithic application to a microservices architecture.
Event sourcing also has some drawbacks. It is a different and unfamiliar style of programming and so there is a learning curve. The event store only directly supports the lookup of business entities by primary key. You must use Command Query Responsibility Segregation (CQRS) to implement queries. As a result, applications must handle eventually consistent data.
Summary
In a microservices architecture, each microservice has its own private datastore. Different microservices might use different SQL and NoSQL databases. While this database architecture has significant benefits, it creates some distributed data management challenges. The first challenge is how to implement business transactions that maintain consistency across multiple services. The second challenge is how to implement queries that retrieve data from multiple services.
For many applications, the solution is to use an event-driven architecture. One challenge with implementing an event-driven architecture is how to atomically update state and how to publish events. There are a few ways to accomplish this, including using the database as a message queue, transaction log mining, and event sourcing.
In future blog posts, we’ll continue to dive into other aspects of microservices.
Published at DZone with permission of Patrick Nommensen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments