FIFO vs. LIFO: Which Queueing Strategy Is Better for Availability and Latency?
Learn how to improve your service's performance under heavy load with a comparative analysis of queueing strategies: FIFO, LIFO, Adaptive, and request prioritization. Explore the trade-offs with modeling and simulation.
Join the DZone community and get the full member experience.
Join For FreeAs an engineer, you probably know that server performance under heavy load is crucial for maintaining the availability and responsiveness of your services. But what happens when traffic bursts overwhelm your system? Queueing requests is a common solution, but what's the best approach: FIFO or LIFO? In this post, we'll explore both strategies through a simple simulation in Colab, allowing you to see the impact of changing parameters on system performance. Comparing the pros and cons of each approach helps to build an understanding of the trade-offs and make better calls about queueing strategies, improving your engineering skills in the process. After all, as the saying goes: "I hear and I forget, I see and I remember, I do and I understand."
Model
To compare the performance of FIFO (which processes requests in the order they are received) and LIFO (which prioritizes the most recent requests) queueing strategies, we'll build a simple model using a Client that generates requests and a Server that handles them. You can find the details in this Colab. The essential characteristics of the model are:
- The client generates queries of random complexity using the lognormal distribution.
- The server can handle a certain amount of requests before queueing them.
- We'll simulate traffic ramp-up gradually reaching about 3x of the server capacity and observe how response time, error rate, and throughput are affected for both FIFO and LIFO queueing.
By running this simulation, we'll be able to compare the two queueing strategies and identify their strengths and weaknesses under heavy load. So, let's dive into the details and see how FIFO and LIFO queueing stack up against each other.
Availability
All the model parameters (you can find them in the "Client simulation code" section) are adjustable. I tuned them to make the server handle about 15 QPS and made the traffic ramp up from 1 QPS to 50 QPS. Let's see how the error rate for FIFO/LIFO compares as the traffic grows:
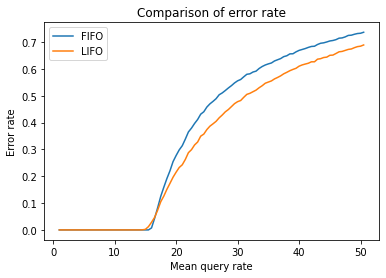
So the server can handle up to 15 QPS without any timeouts, and then we see gradual availability degradation. While LIFO performs slightly better if the rate is much higher than the capacity threshold, it starts returning errors a bit sooner. This is because LIFO may act "unfair" and just forget older queries. To address this issue, we can use an adaptive queueing strategy that switches between FIFO and LIFO, depending on the queue size.
So FIFO or LIFO? Adaptive!
In the following comparison plot, we can see how the adaptive queueing strategy outperforms both FIFO and LIFO, maintaining low overhead and high availability even at high query rates close to the capacity threshold:
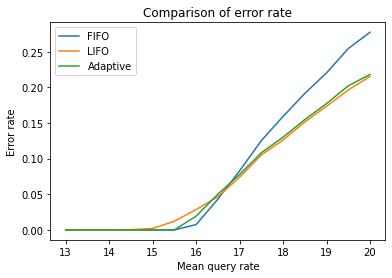
As shown in the comparison plot, the adaptive queueing strategy maintains low overhead and high availability at high query rates close to the capacity threshold. It works by acting as FIFO at low QPS and then switching to LIFO when the saturation point is reached. This approach combines the strengths of both queueing strategies, achieving the best of both worlds.
Request Prioritization
Another dimension to consider in queueing strategies is request prioritization. In many applications, not all functions are equally important, and during times of stress, it's crucial to keep the primary functions available at all costs. To model this scenario, we'll assume that 50% of requests are primary functions, while the remaining 50% are "best-effort" requests. We'll use the LIFO queueing strategy for both scenarios, with and without request prioritization. It's important to note that for the purpose of simulating request prioritization, we'll use LIFO instead of the Adaptive strategy to minimize variables in our model and better understand how they work in isolation.
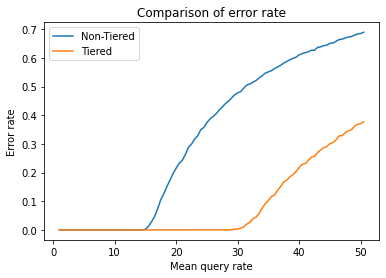
As we can see from the plot, prioritizing "primary" requests can allow us to handle twice as many critical requests at the expense of the "best-effort" ones. During periods of high demand, prioritization can help ensure that the most important functions of your service remain available, while still providing value to your customers through the "best-effort" requests if resources allow. Being aware of customer value and explicitly prioritizing requests can be an effective strategy to improve overall customer satisfaction.
Throughput
In addition to measuring response time and error rate, overall throughput is also a critical factor in evaluating the effectiveness of different queueing strategies. The following plot shows the total number of queries processed by the server using FIFO, LIFO, and adaptive queueing strategies as the traffic increases. Take a look at the graph below:
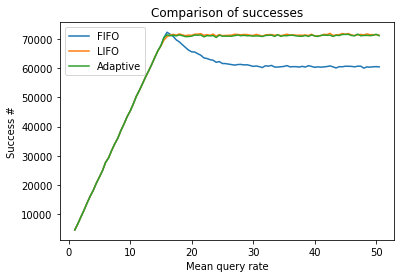 As you can see, while LIFO and Adaptive reach the saturation point and maintain stable throughput, FIFO handles fewer queries overall and wastes a significant portion of capacity, thrashing the queue without a positive outcome (and that's why it has a lower throughput).
As you can see, while LIFO and Adaptive reach the saturation point and maintain stable throughput, FIFO handles fewer queries overall and wastes a significant portion of capacity, thrashing the queue without a positive outcome (and that's why it has a lower throughput).
Latency
And finally, let's examine the impact of different queueing strategies on latency. After all, it's not just about the response time but how quickly your clients receive their responses. We'll compare the mean, median, and p90 latencies for all three queueing strategies: FIFO, LIFO, and the adaptive strategy.
In the latency graph, we consider only successful requests and calculate the "latency overhead," which is the surplus added by queueing on top of the latency that queries have themselves. Ideally, we'd like to keep this overhead close to zero:
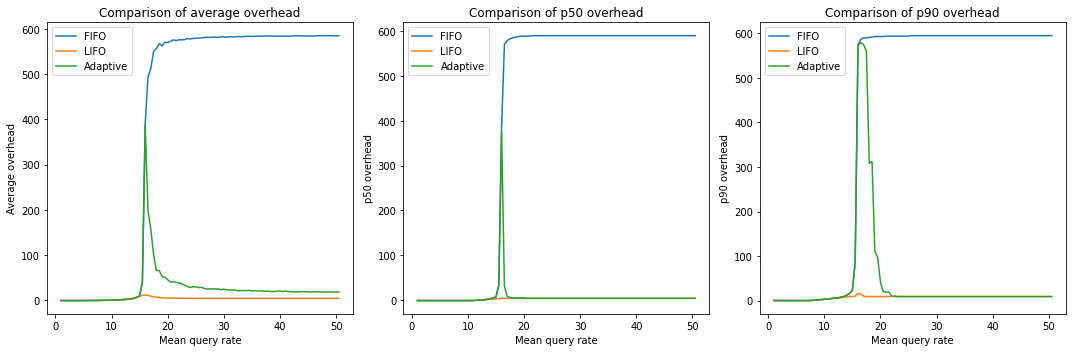
Looking at the latency data, FIFO performs poorly after the saturation point, with a high number of failed requests and successful ones at the edge of the timeout (600s in this model). The Adaptive strategy has a spike due to switching from FIFO to LIFO but eventually stabilizes.
It's important to remember that engineering is all about trade-offs and rarely offers a solution without any downsides. LIFO has a stable latency, but as we saw earlier, it starts failing requests a bit sooner.
Closing Thoughts
In summary, the results show that while LIFO outperforms FIFO at higher query rates, it begins to return errors earlier due to its "unfair" nature of forgetting certain queries. The "Adaptive" queueing strategy, which switches between FIFO and LIFO based on the queue size, performs the best overall.
Additionally, prioritizing requests combined with LIFO (or Adaptive) improves the service's performance, enabling it to handle more queries without significantly impacting the latency overhead. This approach may be useful for maintaining essential functionality during periods of high traffic at the expense of secondary and best-effort features.
We also saw that FIFO not only served fewer queries but also experienced a significant increase in latency overhead. In contrast, the Adaptive approach had a quick spike during the switch from FIFO to LIFO, but the latency quickly returned to LIFO levels (a.k.a. self-healing).
Feel free to play around with the simulation to get a sense of the model and how different parameters may affect it. Remember, there is no shortcut to skipping practice when it comes to learning how to dance!
This post continues the theme of improving service performance/availability touched on in previous posts Ensuring Predictable Performance in Distributed Systems, Navigating the Benefits and Risks of Request Hedging for Network Services, and Isolating Noisy Neighbors in Distributed Systems: The Power of Shuffle-Sharding.
Opinions expressed by DZone contributors are their own.
Comments