Navigating the Benefits and Risks of Request Hedging for Network Services
Learn how to request hedging can improve network service predictability while balancing cost-effectiveness and user experience.
Join the DZone community and get the full member experience.
Join For FreeTail latency is a persistent challenge for network services, with unpredictable spikes in response times due to factors such as CPU wait times and network congestion. While cost-effectiveness is often achieved through the use of shared resources, this can lead to a compromise in user experience.
In this blog post, we examine the technique of request hedging as a solution to this problem. By understanding its benefits and limitations, we aim to provide insights into when and how this technique can be effectively utilized to build more predictable services.
Improving Tail Latency With Request Hedging
If you have a dependency with high variance and can't fix it soon, you can use a technique called "request hedging." The idea is to send two or more requests and pick the fastest one, canceling the slow ones if needed. But this only works for idempotent requests, meaning requests that can be made multiple times with the same outcome. You also need to route requests to different nodes, such as using a load balancer.
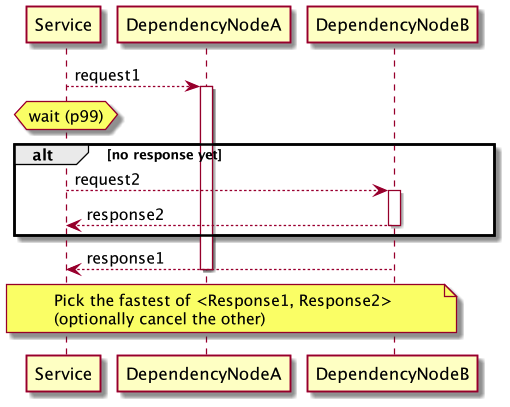
The wait time is based on the latency percentile of the dependency. For example, if you choose a p99 latency, only 1% of requests will get a second sub-request.
Let’s play around with a simulation:
- Using Log-normal distribution.
- Dependency’s
p0..p99.9=10..1000ms - Send a single hedge request for the slowest 1% of sub-requests. To achieve this, we’ll set the hedge delay to the Dependency’s
p99. - See how it affects the Service’s
p99.9
In this case the p99.9(Service)=260ms, compared to the p99.9(Dependency)=1000ms, which corresponds to the p99.2(Dependency).
This is an impressive improvement!
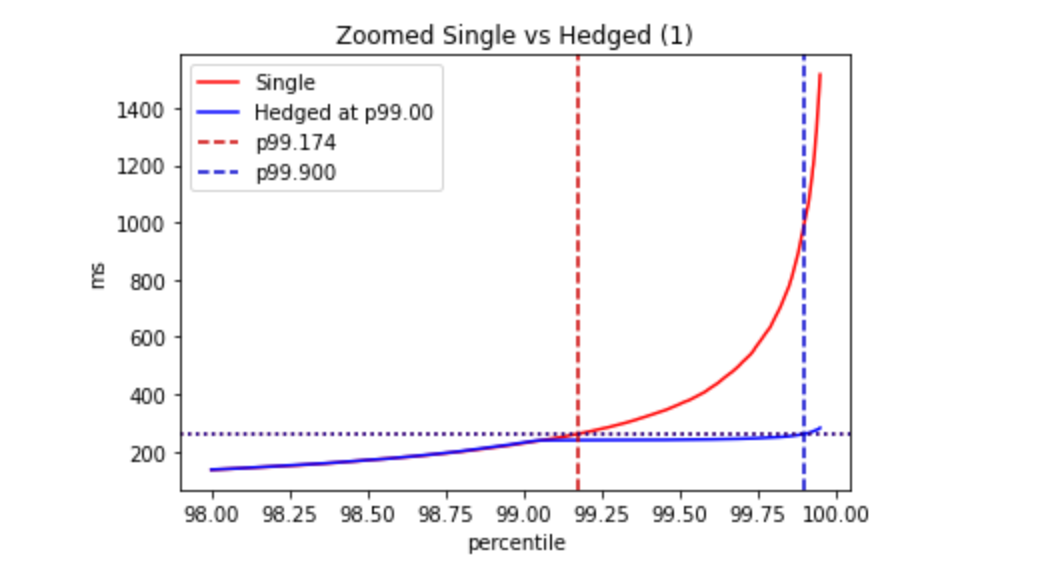
The percentage of hedged requests is 1.012%.
This is especially notable because it comes with a tiny price — the number of requests to dependency is increased by 1% (because in 99% of cases, no additional requests are sent).
Unfortunately, request hedging hits the law of diminishing returns pretty quickly. The next 1% of the service latency improvement costs ~5% of additional requests. And even if we double the number of requests, we get (at most) another 1% of latency improvement for the service’s p99.9:
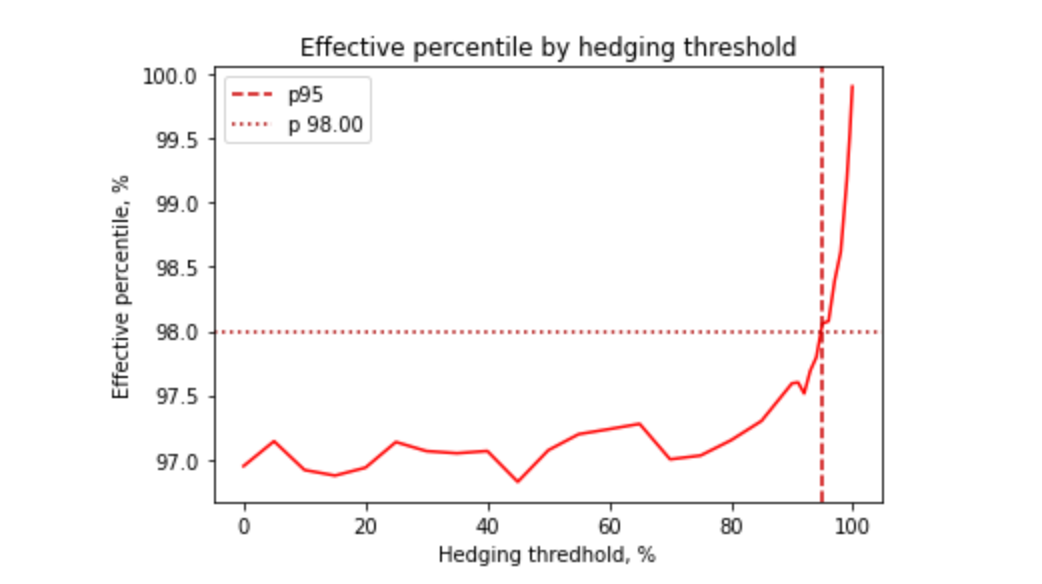
Of course, this can be improved a bit further by sending three or more requests in parallel to pick the fastest response, but the cost may outweigh the benefits.
Request Hedging Is Not Effective for Small Variance
If the variance in a system is already small, then request hedging will not provide much improvement. For instance, if, p0..p99.9(Dependency)=50..200ms, then p99.9(Service)=130ms:
It's important to consider the cost and benefits before implementing request hedging, as it will make the system more complex and costly. The gain in latency doesn't come without a price.
When Request Hedging Goes Wrong
It's important to be aware of the potential downsides of request hedging. If not carefully managed, the technique can amplify outages by increasing the number of requests made. A scenario could unfold like this:
- The dependency service slows down.
- The primary service sends more sub-requests, which reinforces the slowdown in the dependency service.
- The dependency service starts timing out or returning errors.
- The primary service and/or its callers initiate retries, further exacerbating the situation.
- The primary service's availability drops.
To avoid such scenarios, it's essential to implement measures that limit the overhead. These can include a negative feedback loop, a circuit breaker that suspends request hedging under certain conditions, or a combination of the two.
Some strategies for mitigating the risks of request hedging include:
- Using a token bucket that refills every N operation and sending a sub-request only if there is an available token (rate-limiting).
- Periodically refreshing the threshold to match the actual latency percentile.
- Monitoring the availability and performance of the dependency service and suspending request hedging if it drops.
When designing a system that employs request hedging, it's always better to temporarily degrade the quality of service than to cause an outage. Disabling non-critical functionality during stress conditions is a wise precaution.
Conclusion
Request hedging can provide benefits to the user experience, but it also comes with potential risks that must be considered. Careful management of the technique, including cancellation of slower sub-requests to conserve resources, is key. Remember, engineering is about making trade-offs, not perfect systems.
This post is related to Ensuring Predictable Performance in Distributed Systems, which explores the variance and tail latency of network services.
Opinions expressed by DZone contributors are their own.
Comments