How to Create a Search Engine and Algorithm With ClickHouse and Snowflake
Explore a step-by-step guide to developing a search engine and algorithm using Clickhouse, an open-source data warehousing solution.
Join the DZone community and get the full member experience.
Join For FreeClickHouse is an open-source data warehousing solution that is architected as a columnar database management system. This makes it extremely powerful to work with massive datasets, especially ones that are long as they can be aggregated, ordered, or computed with low latency. When working with the same data type, it's very efficient for fast scanning and filtering of the data. This makes it a great use case for implementing a search engine.
A lot of applications use Elasticsearch as their search engine solution. However, such an implementation can be expensive both in terms of cost and time. Copying the data over to Elasticsearch can also cause lags because data is being migrated to another data store. Also, setting up the Elasticsearch cluster, configuring the nodes and defining and fine-tuning indexes can take more programmatic work, which may not be justified for all projects.
Fortunately, we can create an alternative search engine solution using a data warehousing solution such as ClickHouse (or Snowflake) that the company is already using for analytical purposes. Not only does ClickHouse support capabilities such JOINing, UNIONing data and performing statistical functions like STDDEV, but it also goes above and beyond by offering fuzzy text matching algorithms such as multiFuzzyMatchAnyIndex that does an advanced distance calculation across a haystack. Finally, ClickHouse has a more cost-effective storage model and is open-source.
In this tutorial, we will learn how to index, score, and match search queries to return results that make sense for the user.
Prerequisite
First, we need a database to work with. We will start with a movies database which contains 3 different kinds of entities: 1) movies, 2) celebrities, and 3) production houses. Below are the scripts to create a database with those 3 tables.
Movies Table
CREATE OR REPLACE TABLE movies AS
SELECT 1 as id, 'John Wick' as movie_name, 'Action movie centered around a hitman' as movie_description, 9 as imbdb_rating
UNION ALL
SELECT 2 as id, 'Midnight in Paris' as movie_name, 'Romantic movie with historical nostalgia' as movie_description, 8 as imdb_rating
UNION ALL
SELECT 3 as id, 'Foxcatcher' as movie_name, 'Sports movie inspired by true events' as movie_description, 7.0 as imdb_rating
UNION ALL
SELECT 4 as id, 'Bull' as movie_name, 'Mystery and revenge drama' as movie_description, 6.5 as imdb_rating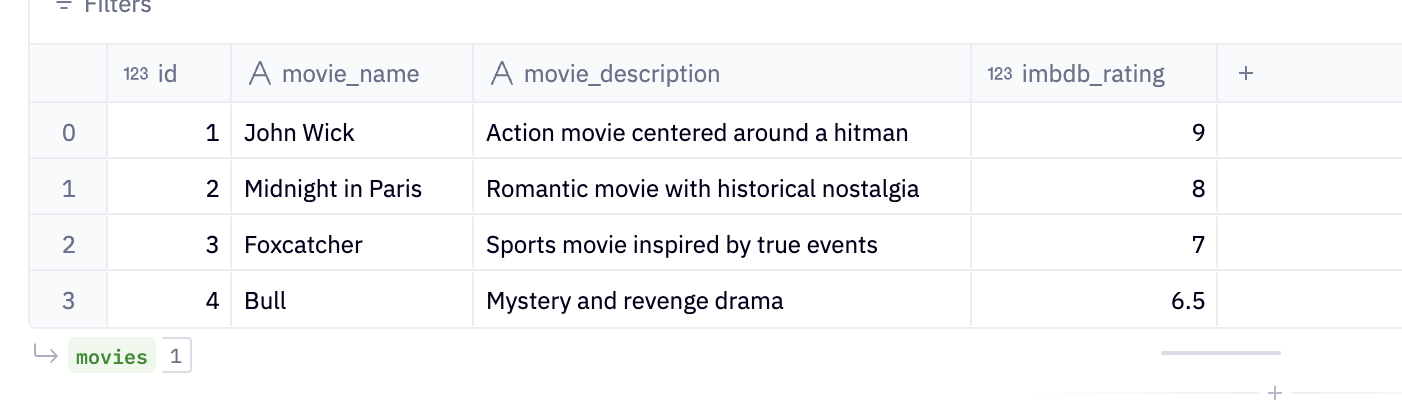
Celebrities Table
CREATE OR REPLACE TABLE celebrities AS
SELECT 1 as id, 'John Wick' as celebrity_name, 'Some actor from Nebraska' as bio, 1500 as instagram_followers
UNION ALL
SELECT 2 as id, 'Owen Wilson' as celebrity_name, 'Romantic movie with historical nostalgia' as bio, 40700 as instagram_followers
UNION ALL
SELECT 3 as id, 'Sandra Bullock' as celebrity_name, 'Sports movie inspired by true events' as bio, 2400000 as instagram_followers
UNION ALL
SELECT 4 as id, 'Robert Downey Jr.' as celebrity_name, 'Popular for his role as Iron Man' as bio, 5810000 as instagram_followers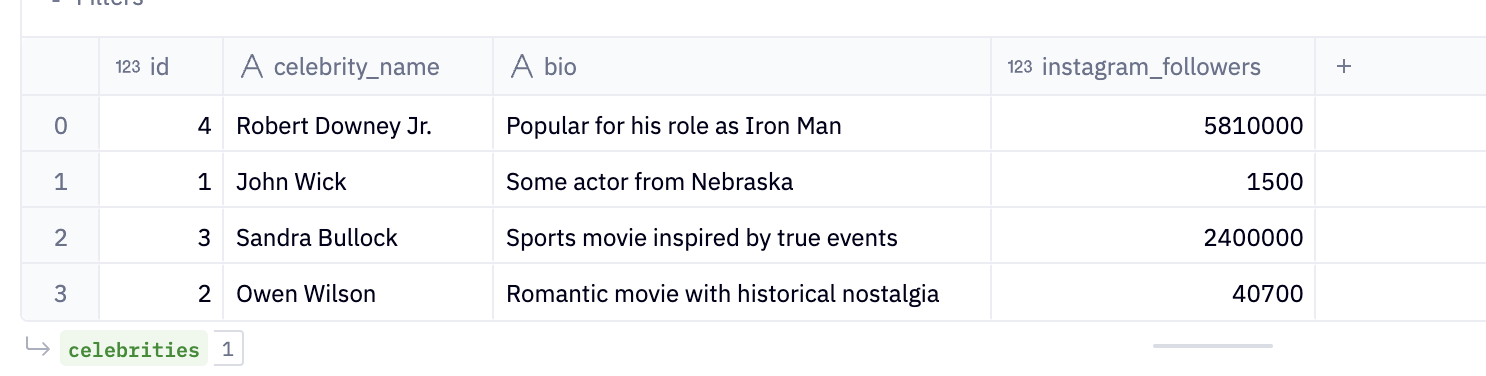
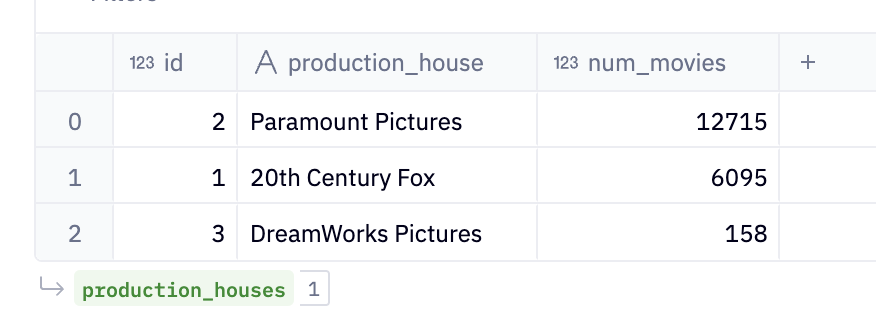
Production Houses Table
CREATE OR REPLACE TABLE production_houses AS
SELECT 1 as id, '20th Century Fox' as production_house, 6095 as num_movies
UNION ALL
SELECT 2 as id, 'Paramount Pictures' as production_house, 12715 as num_movies
UNION ALL
SELECT 3 as id, 'DreamWorks Pictures' as production_house, 158 as num_movies
Architecture
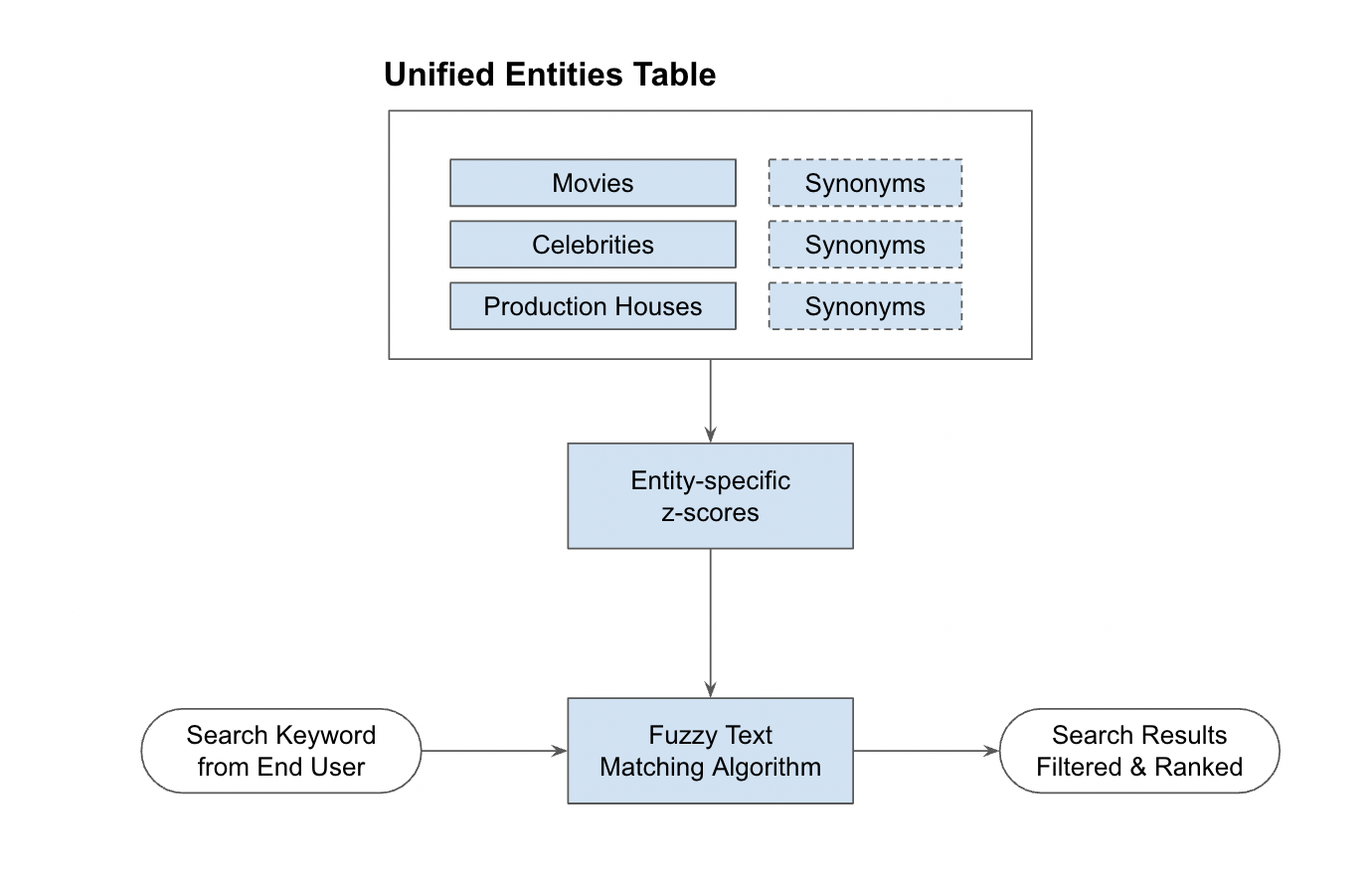
We need to create a system that can search across all the movies, celebrities, and production houses when we query by a search keyword(s) and return to us the best fitting results order in what makes most sense.
Tutorial
Indexing
As a first step, we will take all the disparate tables from the database and standardize them in a unified_entities table by UNIONing them together.
CREATE OR REPLACE TABLE unified_entities AS
SELECT 'movie' as entity_type, id as entity_id, movie_name as entity_name, movie_description as entity_description, imbdb_rating as entity_metric
FROM movies
UNION ALL
SELECT 'celebrity' as entity_type, id as entity_id, celebrity_name as entity_name, bio as entity_description, instagram_followers as entity_metric
FROM celebrities
UNION ALL
SELECT 'production house' as entity_type, id as entity_id, production_house as entity_name, '' as entity_description, num_movies as entity_metric
FROM production_houses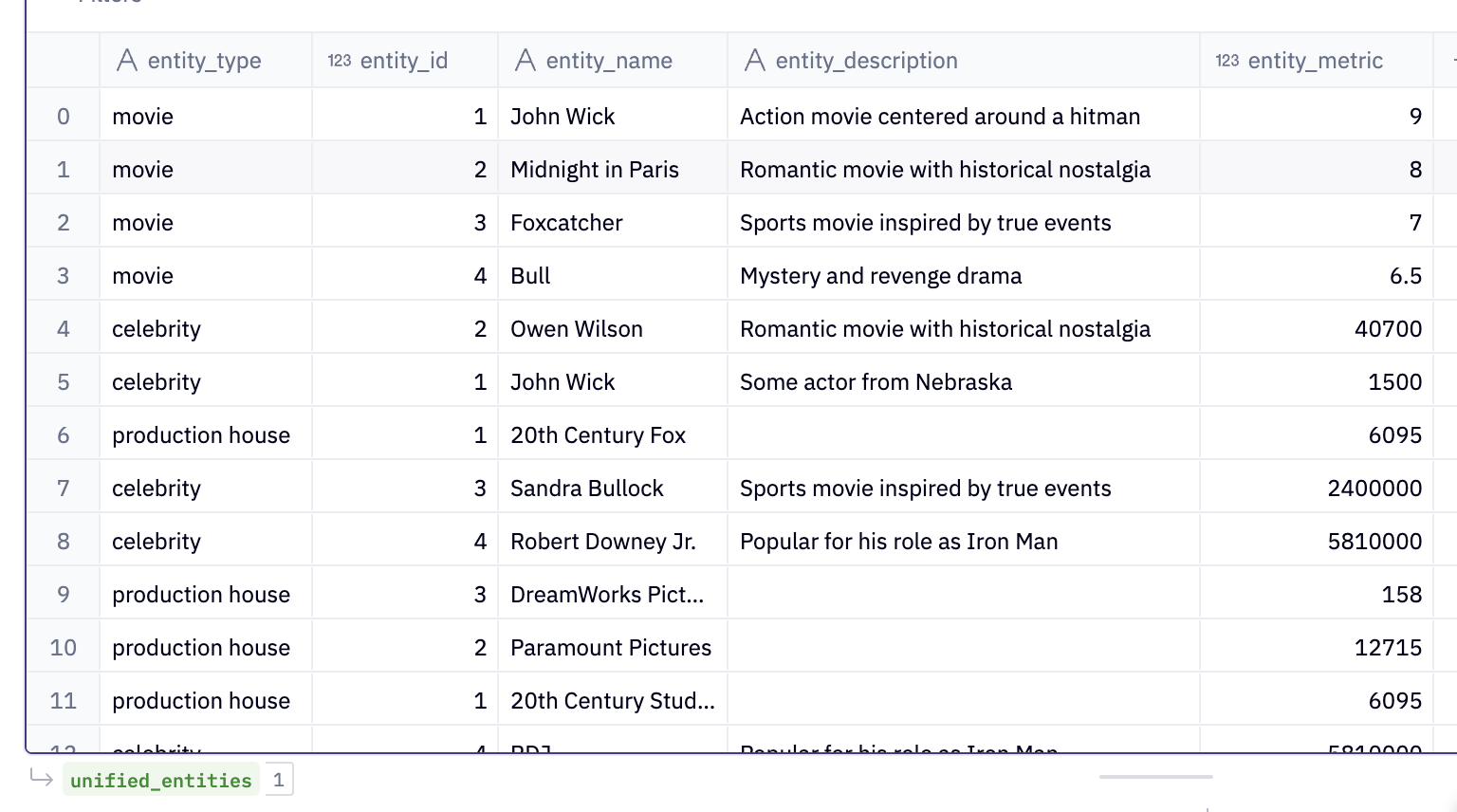
Scoring
Next, we want to make sure we create an algorithm that compares apples to apples. If there's an actor named John Wick and a movie named John Wick, we want to know which one to rank first. By simply comparing them against each other, we may not know which is bigger because we are comparing apples to oranges. The metric available for movies in our database is imdb_rating, while the metric available for celebrities in our database is instagram_followers.
Using a z-score calculation, we will be able to calculate how John Wick as a movie ranks amongst other movies, and also how John Wick as a celebrity ranks amongst other available celebrities. This same example can be used for a word like "Fox" to compare if the movie "Foxcatcher" is more popular than "20th Century Fox" or not.
CREATE OR REPLACE TABLE unified_entities_scored
SELECT
entity_type,
entity_id,
entity_name,
entity_metric,
(entity_metric - AVG(entity_metric) OVER (PARTITION BY entity_type))
/ STDDEV_POP(entity_metric) OVER (PARTITION BY entity_type) AS entity_z_score
FROM unified_entities
WHERE 1=1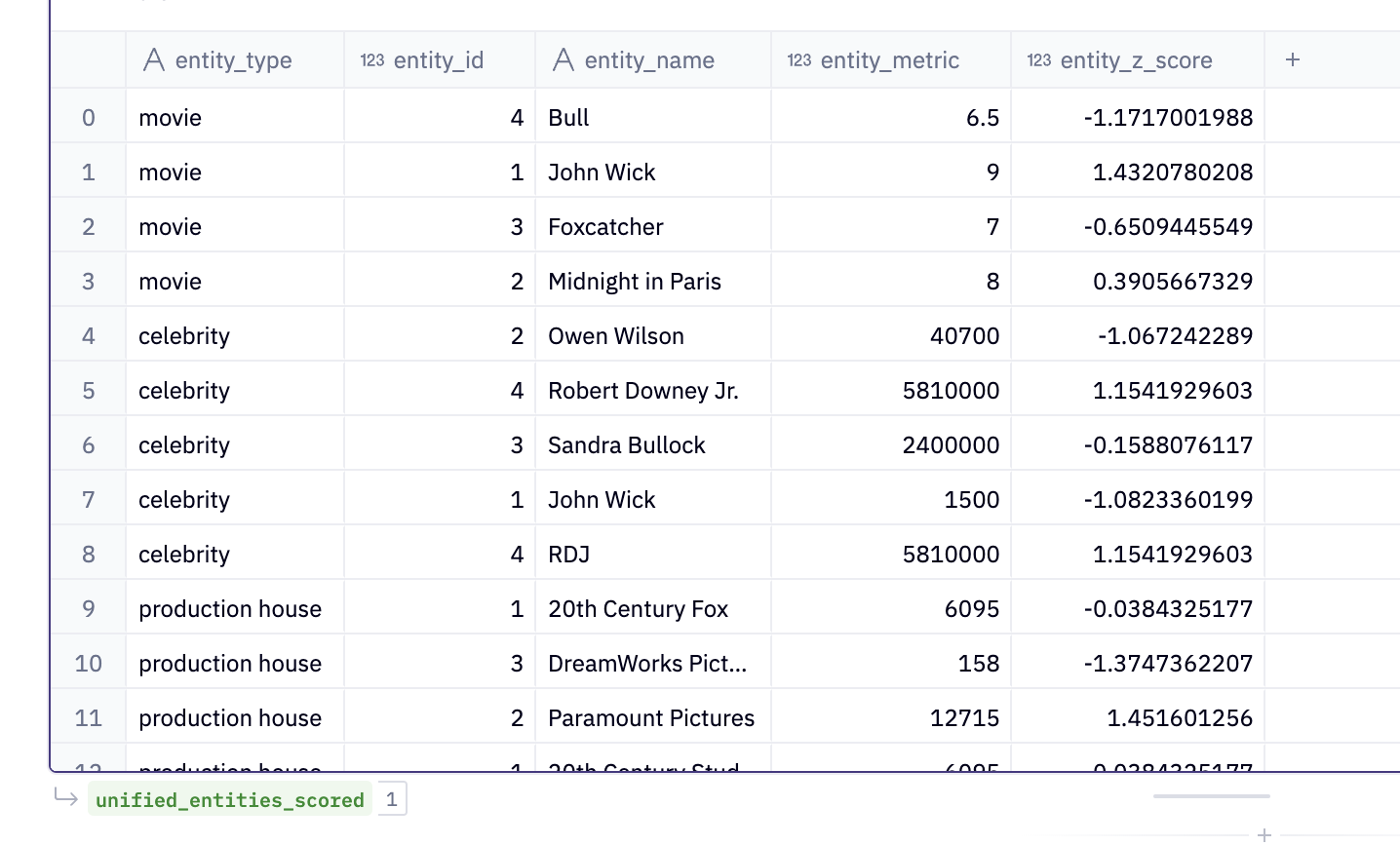
Fuzzy Text Matching
Finally, once we have unified the entities and scored them uniformly, the next step is to compare the search keyword(s) entered by a user to the name being compared to.
For fuzzy text matching, we ended up using ClickHouse's function multiFuzzyMatchAnyIndex.
SELECT
entity_name,
entity_type,
entity_metric,
entity_z_score
FROM unified_entities_scored
WHERE multiFuzzyMatchAnyIndex(entity_name, 1, ['(?i)john', '(?i)wick']) > 0
ORDER BY entity_z_score DESC;As you would have seen, we also ended up ranking the search results by the z-scores we calculated for each entity (within their entity type).
Below, we can see the search results returned are not only correct but are ranked in the right order with John Wick, the movie, getting a higher score than John Wick, the celebrity.

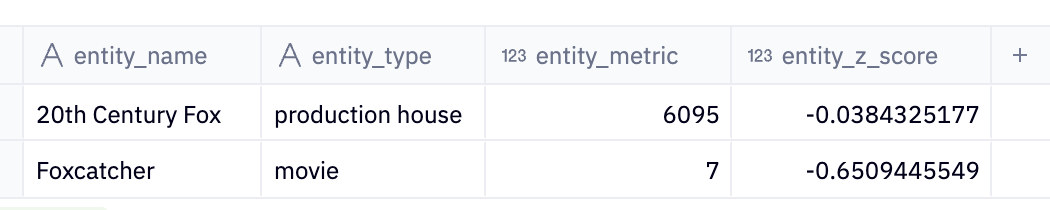
We can try a similar search for the keyword "Fox."
SELECT
entity_name,
entity_type,
entity_metric,
entity_z_score
FROM unified_table_scored
WHERE multiFuzzyMatchAnyIndex(entity_name, 1, ['(?i)fox']) > 0
ORDER BY entity_z_score DESC;This tells us that 20th Century Fox is a better-ranked search result because it is more prominent as a production house than Foxcatcher's prominence as a movie.
multiFuzzyMatchAnyIndex() is a ClickHouse-specific function. Hence, if we were doing this in Snowflake, everything so far stays the same. However, in Snowflake, we will have to change the query to as below:
SELECT
entity_name,
entity_type,
entity_metric,
entity_z_score
FROM unified_table_scored
WHERE LOWER(entity_name) ILIKE '%john %wick%'
ORDER BY entity_z_score DESC;Further Sophistication
As demonstrated, this search algorithm gets us pretty solid search outcomes. However, if we wanted to further improve our search, we need a use-case of searching by synonyms such as "RDJ" instead of Robert Downey Jr. or NYC instead of New York.
For us to be able to do that, we can start by first creating a synonyms table:
Synonyms Table
CREATE OR REPLACE TABLE entity_synonyms AS
SELECT 'celebrity' as entity_type, 4 as entity_id, 'RDJ' as synonym
UNION ALL
SELECT 'production house' as entity_type, 1 as entity_id, '20th Century Studios' as synonym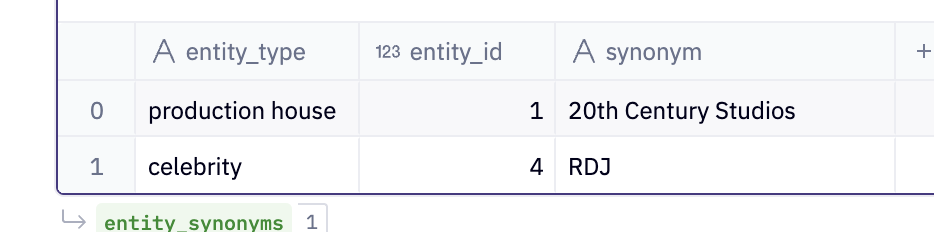
Merge Synonyms to Unified Entities
Now, it's time to JOIN the entity_synonyms to the unified_entities we created and make the unified_entities table a longer table. When we UNION these tables, we shall just create a new column called search_string that can take the value of entity_name for entity records and the value of synonym for the synonym records.
CREATE OR REPLACE TABLE unified_entities AS
WITH unified_entities_v1 as (
SELECT 'movie' as entity_type, id as entity_id, movie_name as entity_name, movie_description as entity_description, imbdb_rating as entity_metric
FROM movies
UNION ALL
SELECT 'celebrity' as entity_type, id as entity_id, celebrity_name as entity_name, bio as entity_description, instagram_followers as entity_metric
FROM celebrities
UNION ALL
SELECT 'production house' as entity_type, id as entity_id, production_house as entity_name, '' as entity_description, num_movies as entity_metric
FROM production_houses
)
SELECT u.entity_type, u.entity_id, u.entity_name, u.entity_name as search_string, u.entity_description, u.entity_metric
FROM unified_entities_v1 u
UNION ALL
SELECT u.entity_type, u.entity_id, u.entity_name, s.synonym as search_string, u.entity_description, u.entity_metric
FROM unified_entities_v1 u
INNER JOIN entity_synonyms s ON u.entity_type = s.entity_type AND u.entity_id = s.entity_id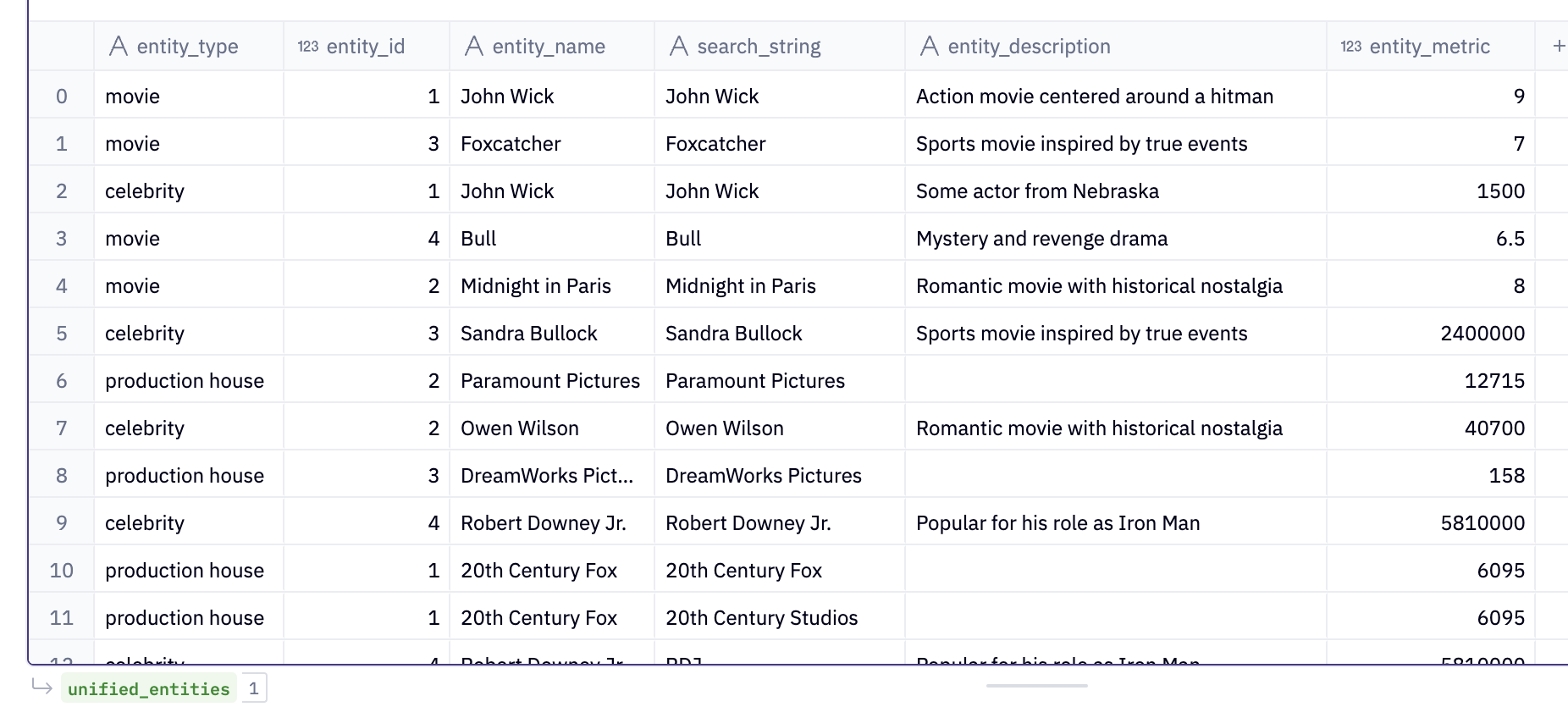
Search Query
We can try searching by "RDJ" and here's what we will get below:
SELECT
entity_id,
entity_name,
entity_type,
entity_metric,
entity_z_score
FROM unified_entities_scored
WHERE multiFuzzyMatchAnyIndex(search_string, 1, ['(?i)RDJ']) > 0
ORDER BY entity_z_score DESC;
In this example, we used the search_string column for fuzzy text matching. However, we used the entity_name and entity_id columns for displaying the records returned. This is done for the most optimal user experience.
As we can see, the search result returns the same result for Robert Downey, Jr. despite searching by the synonym "RDJ", which is our intended outcome.
Summary
This article showed a full tutorial on how to create a cross-entity search engine in ClickHouse from scratch. We took an example of a movie database and demonstrated the key steps involved such as indexing, scoring, and text matching. This implementation can be easily replicated for any other domain such as e-commerce or fintech.
Opinions expressed by DZone contributors are their own.
Comments