From Developer to AI Teammate: Building an Agentic Automation Prototype
Transform repetitive developer workflows into an intelligent, AI-powered teammate using LangChain, retrieval-augmented generation (RAG), and lightweight automation loops.
Join the DZone community and get the full member experience.
Join For FreeThe Problem: Developer Workflows Are Still Too Manual
Despite CI/CD, containerization, and mature DevOps practices, developers still spend hours on repetitive, low-value tasks — restarting services, parsing logs, or cross-checking configurations.
Common examples include:
- “What’s the latest Kafka broker IP in production?”
- “Did the deployment pipeline succeed?”
- “Show me the last 10 lines of the Redis log.”
- “Is this alert a known issue or a new one?”
These queries are context-rich but tedious. Most could be automated if our tools “understood” the environment — the services, logs, and workflows involved.
That’s where the agentic AI pattern comes in.
The Idea: Agentic AI for Developer Productivity
Agentic AI combines LLM-based reasoning, RAG for contextual awareness, and autonomous workflows to create what feels like a teammate — not just a script.
Instead of writing fixed automation logic, you build a system that
- Understands natural-language queries.
- Retrieves relevant data from APIs, logs, or documentation.
- Acts or summarizes intelligently.
- Improves through continuous feedback.
Over time, it becomes context-aware, learning naming conventions, deployment patterns, and common fixes — evolving into a true AI teammate.
Architecture Overview
Conceptually, the system follows this flow:
Developer → LangChain Agent → RAG Store → LLM → Action/Observation Loop
| |
↓ ↓
Internal APIs Monitoring & Logs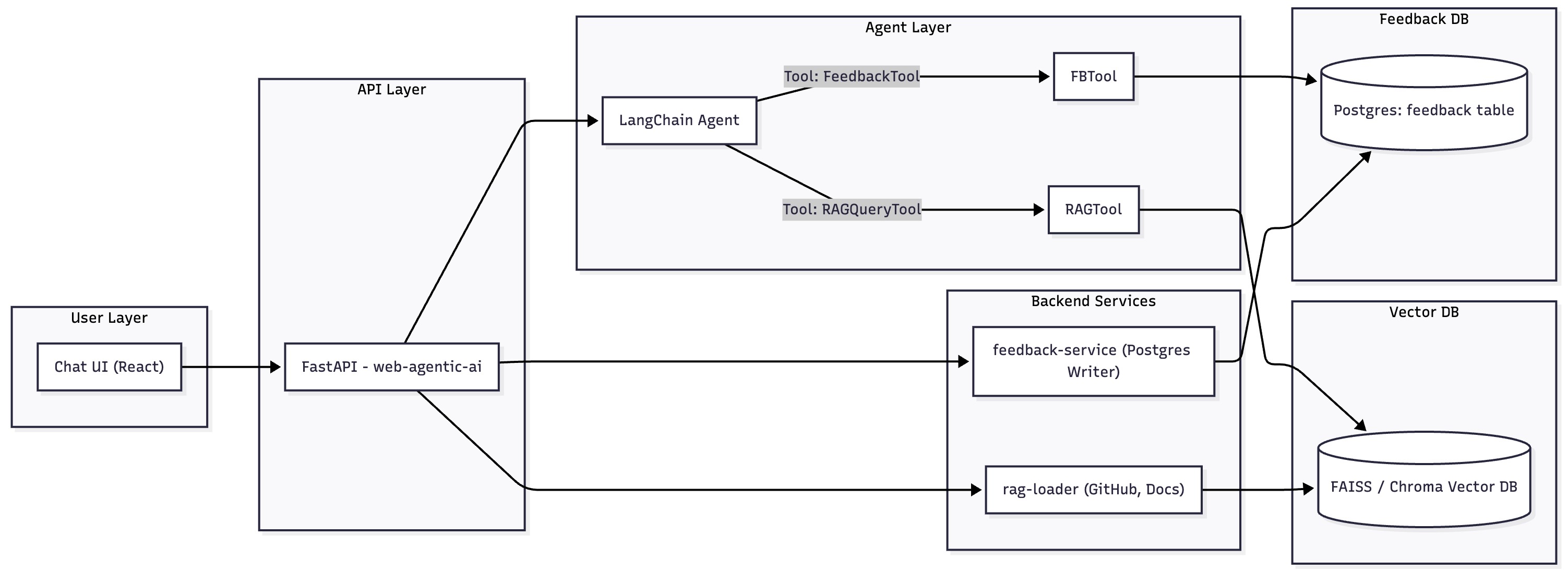
Building the Prototype: LangChain + RAG
At the heart of this system is LangChain, which helps chain together LLM reasoning, retrieval, and tool calls.
Here’s a minimal working prototype:
from langchain.chains import RetrievalQA
from langchain.llms import Ollama
from langchain.vectorstores import FAISS
# Initialize a simple retrieval-augmented agent
qa = RetrievalQA.from_chain_type(
llm=Ollama(model="llama3"),
retriever=faiss_index.as_retriever(),
)
query = "Show latest pod status for hyperwarp namespace."
print(qa.run(query))This agent:
- Accepts a developer query.
- Retrieves context from stored documentation or API outputs.
- Generates a grounded, intelligent response.
You can extend this with adapters for:
- Kubernetes APIs for pod status or deployment checks
- CI/CD systems for build or release info
- Monitoring dashboards for alert summaries
- Ticketing systems for auto-triage
Example: Daily System Health Assistant
Imagine your AI teammate starts each morning with:
“All services are healthy except the payments API (503 errors detected). The fix applied last week resolved a similar issue — would you like to retry that remediation?”
This level of proactive, context-aware automation is achievable by combining the following:
- Healthcheck endpoints
- RAG retrieval from incident logs
- LLM reasoning to suggest remediation
- Feedback loops to confirm or learn from outcomes
Lessons Learned and Trade-Offs
|
Aspect |
What Worked |
What to Watch Out For |
|
LangChain |
Simplifies orchestration between LLMs, APIs, and RAG |
Can add latency for small actions |
|
RAG |
Ensures factual, context-based responses |
Requires frequent vector updates |
|
Local LLMs (Ollama/Mistral) |
Offer privacy and quick prototyping |
Less performant for complex multi-step reasoning |
|
Feedback Loops |
Drive real learning and adaptation |
Need a persistent data store (e.g., Postgres) |
|
Action Execution |
Enables end-to-end workflows |
Must include safety validation before automation |
Building Feedback Loops That Matter
The secret sauce isn’t just retrieval — it’s learning from feedback.
Each user query and rating (✅ helpful / ❌ not helpful) is stored and linked to:
- Query embeddings
- Response metadata
- Execution results
This historical data can then be used to:
- Fine-tune the retrieval pipeline
- Adjust embeddings dynamically
- Train reinforcement models on successful actions
This ensures that your AI teammate gets smarter over time — not just faster.
Integrating Into Cloud-Native Workflows
The same architecture can integrate seamlessly with existing tools
- ChatOps: Slack/Teams integration for natural-language commands.
- CI/CD: Trigger AI checks before or after deployment.
- Incident management: Summarize logs or auto-escalate issues.
- Monitoring: Auto-interpret metric anomalies.
Example of a ChatOps interaction:
Dev: /ask-ai restart kafka secondary broker in us-south
Agent: “Restart confirmed for broker-2 (region: us-south). Monitoring logs for recovery…”
Behind the scenes:
- The LLM parses intent.
- The agent retrieves relevant cluster info.
- A Kubernetes API executes the command.
- Results are fed back for traceability.
This creates a continuous loop — intent → action → feedback → learning.
Why This Matters
Traditional automation relies on rigid scripts — if-then logic that breaks when context shifts. Agentic AI changes that by introducing adaptability and understanding.
Benefits include:
- Fewer manual lookups or restarts
- Reduced cognitive load for engineers
- Higher system uptime and faster incident response
- Traceable, auditable decision paths
Instead of remembering every command, developers express intent — “restart service,” “check last failure,” or “show latency trends” — and the system handles the details.
Extending to Multi-Agent Architectures
Future evolution may involve specialized AI agents working collaboratively
- Retriever Agent: Fetches precise documents or logs
- Reasoner Agent: Synthesizes context and suggests actions
- Executor Agent: Executes approved automation tasks
- Auditor Agent: Validates safety and compliance
Such multi-agent ecosystems can scale horizontally, each focusing on a specialized domain of the developer workflow.
Real-World Trade-off: Local vs. Cloud Deployment
|
Mode |
Pros |
Cons |
|
Local-first |
Privacy-preserving, faster for devs |
Limited compute for large models |
|
Cloud-based |
Scalable, integrates with enterprise systems |
Data governance and latency challenges |
|
Hybrid |
Best of both — sensitive data local, LLM calls in the cloud |
Requires an orchestration layer |
For early prototyping, a local-first setup (Ollama, Podman, Docker Compose) is ideal. Once stable, scaling to a cloud-ready stack with container orchestration and managed vector databases enables production-grade reliability.
Final Thoughts
Building an AI teammate is no longer a futuristic concept — it’s a practical engineering challenge.
By combining LLM reasoning, retrieval pipelines, and feedback-driven learning, developers can move beyond repetitive scripts to intelligent automation.
Key Takeaways
- Start simple - automate one daily task intelligently.
- Make it observable — expose logs, metrics, and feedback.
- Evolve iteratively — add memory, context, and safe actions.
- Keep privacy and safety at the core.
This approach doesn’t replace developers — it amplifies them, allowing engineers to focus on design, debugging, and innovation while AI handles the operational noise.
Explore and Connect
You can explore the full implementation, architecture examples, and starter code here:
GitHub Repository: https://github.com/sayan1886/agentic-ai
Let’s connect and discuss AI-driven automation, agentic systems, and developer productivity:
LinkedIn: www.linkedin.com/in/sayan-ai-cloud
Opinions expressed by DZone contributors are their own.
Comments