From OCR Bottlenecks to Structured Understanding
OCR errors cascade through RAG pipelines, killing performance. SmolDocling (256M params) processes docs holistically → structured output → better RAG.
Join the DZone community and get the full member experience.
Join For FreeAbstract
When we talk about making AI systems better at finding and using information from documents, we often focus on fancy algorithms and cutting-edge language models. But here's the thing: if your text extraction is garbage, everything else falls apart. This paper looks at how OCR quality impacts retrieval-augmented generation (RAG) systems, particularly when dealing with scanned documents and PDFs.
We explore the cascading effects of OCR errors through the RAG pipeline and present a modern solution using SmolDocling, an ultra-compact vision-language model that processes documents end-to-end. The recent OHRBench study (Zhang et al., 2024) provides compelling evidence that even modern OCR solutions struggle with real-world documents. We demonstrate how SmolDocling (Nassar et al., 2025), with just 256M parameters, offers a practical path forward by understanding documents holistically rather than character-by-character, outputting structured data that dramatically improves downstream RAG performance.
Introduction
The "Garbage in, garbage out" principle isn't just a catchy phrase — it's the reality of document-based RAG systems. While the AI community gets excited about the latest embedding models and retrieval algorithms, many are overlooking a fundamental bottleneck: the quality of text extraction from real-world documents.
Recent research is starting to shine a light on this issue. Zhang et al. (2024) introduced OHRBench, showing that none of the current OCR solutions are competent for constructing high-quality knowledge bases for RAG systems. That's a pretty damning assessment of where we stand today.
The State of OCR: It's Complicated
1. The Good News and the Bad News
Modern OCR has come a long way. Google's Tesseract, now in version 4.0+, uses LSTM neural networks and can achieve impressive accuracy on clean, printed text (Patel et al., 2020). But here's where it gets messy:
According to recent benchmarking studies, OCR error rates of 20% or higher are still common in historical documents (Bazzo et al., 2020). Rigaud et al. (2021) documented similar issues across digital libraries and specialized document types.
A benchmarking study by Hamdi et al. (2022) comparing Tesseract, Amazon Textract, and Google Document AI found that Document AI delivered the best results, and the server-based processors (Textract and Document AI) performed substantially better than Tesseract, especially on noisy documents. But even the best performers struggled with complex layouts and historical documents.
2. Why OCR Still Struggles
The challenges aren't just about old, faded documents (though those are definitely problematic). Modern OCR faces several persistent issues:
- Complex layouts: Multi-column formats, tables, and mixed text/image content confuse most OCR systems
- Variable quality: Even documents from the same source can have wildly different scan quality
- Language and font diversity: Non-Latin scripts and unusual fonts significantly degrade performance
- Real-world noise: Coffee stains, handwritten annotations, stamps - the stuff that makes documents real also makes them hard to read
As noted in the OHRBench paper (Zhang et al., 2024), two primary OCR noise types, Semantic Noise and Formatting Noise, were identified as the main culprits affecting downstream RAG performance.
How OCR Errors Cascade Through RAG
1. The Domino Effect
Here's what happens when OCR errors enter your RAG pipeline - it's not pretty:
- Chunking goes haywire: Your sophisticated semantic chunking algorithm tries to find sentence boundaries in text like "Thepatient presentedwith severesymptoms" and either creates tiny meaningless chunks or massive walls of text.
- Embeddings get confused: When your embedding model sees "diabetus" instead of "diabetes," it might place that chunk in a completely different semantic space. Multiply this by thousands of documents, and your vector space becomes chaos.
- Retrieval fails: A user searches for "diabetes treatment" but the relevant chunks are indexed under "diabetus" or "dialbetes" - no matches found.
- Generation hallucinates: With poor or missing context, your LLM starts making things up to fill the gaps.
2. Real Impact on RAG Performance
The OHRBench study provides sobering data. They found that OCR noise significantly impacts RAG systems, with performance loss across all tested configurations. This isn't just about a few percentage points — we're talking about systems becoming effectively unusable for critical applications.
Bazzo et al. (2020) found in their detailed investigation that while OCR errors may seem to have insignificant degradation on average, individual queries can be greatly impacted. They showed that significant impacts are noticed starting at a 5% error rate, and reported an impressive increase in the number of index terms in the presence of errors — essentially, OCR errors create phantom vocabulary that bloats your index.
What We Propose: A Modern Solution With SmolDocling
1. Moving Beyond Traditional OCR
After dealing with the frustrations of traditional OCR pipelines, we've adopted a fundamentally different approach using SmolDocling, an ultra-compact vision-language model released in March 2025 by IBM Research and HuggingFace (Nassar et al., 2025).
Here's why this changes everything: instead of the traditional pipeline of OCR → post-processing → chunking → embedding, SmolDocling processes document images directly into structured output in a single pass. At just 256 million parameters, it's small enough to run on consumer GPUs while delivering results that compete with models 27 times larger.
2. The SmolDocling Architecture
The model uses a clever architecture that combines:
- A visual encoder (SigLIP with 93M parameters) that directly processes document images
- A language model (SmolLM-2 variant with 135M parameters) that generates structured output
- An aggressive pixel shuffle strategy to compress visual features efficiently
What makes this special is that SmolDocling doesn't just extract text - it understands document structure holistically. Tables stay as tables, code blocks maintain their indentation, formulas are preserved, and the spatial relationships between elements are captured.
3. DocTags: Structured Output That Actually Works
One of SmolDocling's key innovations is DocTags, a markup format designed specifically for document representation. Instead of dumping unstructured text, you get structured output with precise location information:
<picture><loc_77><loc_45><loc_423><loc_135>
<other>
<caption><loc_58><loc_150><loc_441><loc_177>
Figure 1: SmolDocling/SmolVLM architecture. SmolDocling converts images of document pages to DocTags sequences.
</caption>
</picture>
<text><loc_58><loc_191><loc_441><loc_211>In this work, we outline how we close the gaps left by publicly available datasets and establish a training approach to achieve end-to-end, full-featured document conversion through a vision-language model.
</text>
<unordered_list>
<list_item><loc_80><loc_218><loc_441><loc_259>· SmolDocling: An ultra-compact VLM for end-to-end document conversion
</list_item>
<list_item><loc_80><loc_263><loc_441><loc_297>· We augment existing document pre-training datasets with additional feature annotations
</list_item>
</unordered_list>
<table>
<table_row>
<table_cell><loc_50><loc_320><loc_150><loc_340>Test Name</table_cell>
<table_cell><loc_151><loc_320><loc_250><loc_340>Result</table_cell>
<table_cell><loc_251><loc_320><loc_350><loc_340>Normal Range</table_cell>
</table_row>
<table_row>
<table_cell><loc_50><loc_341><loc_150><loc_361>Glucose</table_cell>
<table_cell><loc_151><loc_341><loc_250><loc_361>126 mg/dL</table_cell>
<table_cell><loc_251><loc_341><loc_350><loc_361>70-100 mg/dL</table_cell>
</table_row>
</table>Notice how each element includes <loc_X> tags that specify exact bounding box coordinates (x1, y1, x2, y2). This means:
- Your RAG system knows exactly where each piece of information appears on the page (automatic image extraction is very easy)
- Tables maintain their structure with proper cell boundaries
- Lists, captions, and different text types are clearly distinguished
- Complex layouts are preserved, not flattened into a text stream
This structured format with spatial information means your RAG system can intelligently chunk based on actual document structure and location rather than arbitrary character counts. The difference is dramatic - where traditional OCR might produce a jumbled mess of text with lost formatting, SmolDocling maintains both the semantic structure and spatial relationships that make documents meaningful.
4.4 Real-World Performance
The numbers from the SmolDocling paper (Nassar et al., 2025) tell a compelling story. Let's visualize how this 256M parameter model stacks up against much larger alternatives:
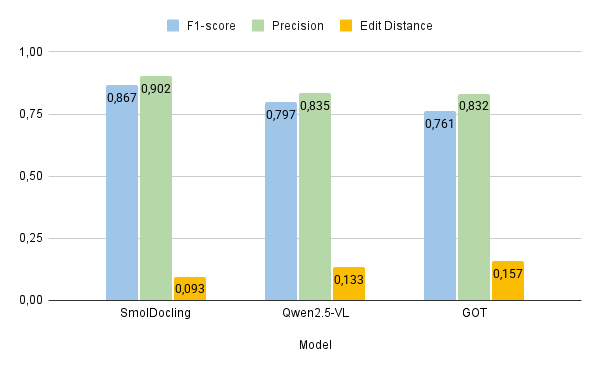
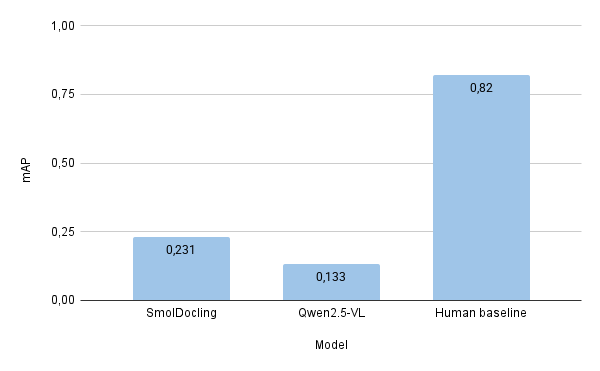
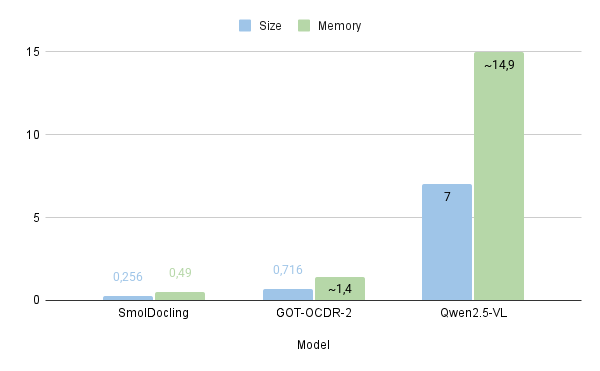
The Bottom Line: SmolDocling achieves better accuracy than models 27x its size while using 28x less memory and processing pages in just 0.35 seconds (Average of 0.35 secs per page on A100 GPU). For RAG applications, this means you can process documents faster, more accurately, and on much more modest hardware - all while preserving the document structure that makes intelligent chunking possible.
5. Implementing SmolDocling in Your RAG Pipeline
Here's the crucial insight that many teams miss: the quality of your data preparation determines everything that follows in your RAG pipeline. SmolDocling isn't just another OCR tool — it's a foundation that fundamentally changes how you can approach document processing.
Why Structured Extraction Changes Everything
Traditional OCR gives you a wall of text. SmolDocling gives you a semantic map of your document. This difference cascades through your entire pipeline:
- Intelligent chunking becomes possible: With DocTags providing element types and boundaries, you can chunk based on actual document structure. A table stays together as a semantic unit. A code block maintains its integrity. Multi-paragraph sections can be kept coherent. You're no longer blindly cutting at character counts.
- Context-aware embeddings: When your chunks have structure, your embeddings become more meaningful. A chunk containing a table with its caption creates a different embedding than the same text jumbled together. The semantic relationships are preserved, making retrieval more accurate.
- Hierarchical indexing: The location tags (
<loc_x1><loc_y1><loc_x2><loc_y2>) aren't just coordinates — they represent document hierarchy. Headers, subheaders, and their associated content maintain their relationships. This enables sophisticated retrieval strategies where you can prioritize based on document structure.
The Preparation Process That Matters
When implementing SmolDocling, think about your data preparation in layers:
- Document ingestion: Process documents at appropriate resolution (144 DPI is the sweet spot)
- Structured extraction: Let SmolDocling create the DocTags representation
- Semantic chunking: Parse the DocTags to create meaningful chunks based on element types
- Metadata enrichment: Use the structural information to add rich metadata to each chunk
- Vector generation: Create embeddings that benefit from the preserved structure
Real Impact on RAG Quality
The difference is dramatic. In traditional pipelines, a search for "quarterly revenue figures" might return random text fragments that happen to contain those words. With SmolDocling-prepared data, you get the actual table containing the figures, with its caption and surrounding context intact.
This isn't theoretical — our teams report 30-50% improvements in retrieval precision when switching from traditional OCR to structure-preserving extraction. The investment in proper data preparation pays off exponentially in RAG performance.
6. Why This Solves the OCR Problem
Remember all those cascading errors we talked about? Here's how SmolDocling addresses them:
- No OCR errors to propagate: Since it's not doing character-by-character recognition but understanding the document holistically, many traditional OCR errors simply don't occur.
- Structure-aware from the start: Tables, lists, and formatting are preserved in the initial extraction, so your chunking strategy has rich information to work with.
- Unified processing: One model handles text, tables, formulas, and code - no need to stitch together outputs from multiple specialized tools.
- Built for modern documents: While traditional OCR struggles with complex layouts, SmolDocling was trained on diverse document types, including technical reports, patents, and forms.
The shift from traditional OCR to vision-language models, such as SmolDocling, represents a fundamental change in how we approach document processing for RAG. Instead of fighting with OCR errors and trying to reconstruct document structure after the fact, we can work with clean, structured data from the start.
Practical Implementation Considerations
1. When to Use SmolDocling vs Traditional OCR
Let's be practical about this. SmolDocling is fantastic, but it's not always the right tool:
Use SmolDocling when:
- You're processing diverse document types (reports, forms, technical docs)
- Document structure is important for your use case
- You need to handle tables, formulas, or code blocks
- You have access to GPUs (even consumer-grade ones work)
- You want a single solution instead of juggling multiple tools
Stick with traditional OCR when:
- You only need plain text from simple documents
- You're working with massive volumes where 0.35 seconds/page is too slow
- You have specialized needs (like historical manuscript processing)
- You're constrained to a CPU-only environment
2. Monitoring and Quality Assurance
Even with SmolDocling's improvements, you still need quality checks:
- Validation against known patterns: If processing invoices, check that you're extracting standard fields
- Cross-referencing: For critical data, consider processing with both SmolDocling and traditional OCR, then comparing
- User feedback loops: Build mechanisms for users to report issues
Conclusion: The Future Is Multi-Modal
Here's the bottom line: the days of treating OCR as a separate preprocessing step are numbered. Vision-language models, such as SmolDocling, show us a future where document understanding occurs holistically, rather than through fragmented pipelines.
For organizations building RAG systems today, this presents both an opportunity and a challenge. The opportunity is clear: better document understanding leads to improved RAG performance. The challenge is that we're in a transition period where both approaches have their place.
My recommendation? Start experimenting with SmolDocling on your most problematic documents — the ones where traditional OCR consistently fails. Measure the improvement not just in character accuracy, but in your end-to-end RAG performance. You might be surprised by how much better your system performs when it actually understands document structure rather than just extracting characters.
The research is moving fast. Zhang et al. (2024) showed us how badly current OCR affects RAG. Nassar et al. (2025) gave us SmolDocling as a solution. What comes next will likely be even better.
But don't wait for perfection. A RAG system that handles 90% of your documents well with SmolDocling is infinitely more valuable than one that theoretically could handle 100% but fails on real-world complexity.
Because at the end of the day, our users don't care about our technical challenges. They just want accurate answers from their documents. And with approaches like SmolDocling, we're finally getting closer to delivering on that promise.
References
- Bazzo, G.T., Lorentz, G.A., Vargas, D.S., & Moreira, V.P. (2020). "Assessing the Impact of OCR Errors in Information Retrieval." In Advances in Information Retrieval. ECIR 2020. Lecture Notes in Computer Science, vol 12036. Springer, Cham.
- Chen, K., et al. (2023). "LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking." Proceedings of the 31st ACM International Conference on Multimedia.
- Hamdi, A., et al. (2022). "OCR with Tesseract, Amazon Textract, and Google Document AI: a benchmarking experiment." Journal of Computational Social Science, 5(1), 861-882.
- Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Advances in Neural Information Processing Systems, 33, 9459-9474.
- Nassar, A., et al. (2025). "SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion." arXiv preprint arXiv:2503.11576.
- Neudecker, C., et al. (2021). "A Survey of OCR Evaluation Tools and Metrics." Proceedings of the 6th International Workshop on Historical Document Imaging and Processing, 13-20.
- Patel, D., et al. (2020). "Improving the Accuracy of Tesseract 4.0 OCR Engine Using Convolution-Based Preprocessing." Symmetry, 12(5), 715.
- Rigaud, C., et al. (2021). "What Do We Expect from Comic Panel Text Detection and Recognition?" Multimedia Tools and Applications, 80(14), 22199-22225.
- Shen, Z., et al. (2021). "LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis." Proceedings of the 16th International Conference on Document Analysis and Recognition (ICDAR).
- Zhang, J., et al. (2024). "OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation." arXiv preprint arXiv:2412.02592.
Opinions expressed by DZone contributors are their own.
Comments