Garbage Collection Settings for Elasticsearch Master Nodes
This post investigates how garbage collection can have a significant impact on your Elasticsearch cluster's performance.
Join the DZone community and get the full member experience.
Join For FreeElasticsearch comes with good out-of-the-box garbage collection settings. So good, in fact, that the Definitive Guide recommends not changing them. While we agree that most use-cases wouldn't benefit from GC tuning, especially when it turns out there simply isn't enough heap, there are exceptions. We found that G1 GC, for example, works well on big heaps. This allows you to have less, bigger nodes, which in turn means less network traffic in a large cluster.
Elasticsearch Garbage Collection discussions are often about data nodes, since they do most of the work. There's less information about dedicated masters: when Garbage Collection issues may appear, why, and how to solve them. In this post, we'll refer to master nodes, though a lot of this information applies to other situations.
Workload and Potential Issues
Usually, dedicated master nodes are mostly idle. Even the active master uses little CPU, because its only constant job is to ping the other nodes. It also has process cluster state changes, such as the addition of an index, a field or a node.
We should all design for small, infrequently updated cluster states, e.g. under 20 nodes, under 5000 shards and under 100 fields per index. Sometimes requirements simply don't allow for this. A full cluster restart on a 100-node, 50K-shard cluster (which generates a lot of cluster state updates) might bring exciting issues.
If the master is overloaded with the number of updates it has to process, it will queue them. The cluster becomes unresponsive for longer, at least to writes, but it will eventually catch up.
Many cluster state updates also generate a lot of garbage. If garbage can't be collected fast enough, heap may run out. Or a long GC pause can disconnect the active master from the cluster. In both cases, a new master will get elected, which may run out of memory as well.
Fixing OOM Errors on Master Nodes
If GC throughput is indeed the problem, we can make the GC work harder, trading some overhead for throughput. We can do this by lowering CMSInitiatingOccupancyFraction in jvm.options. This setting determines when the old generation garbage collector (CMS by default) kicks in. Assuming there's plenty of heap for when masters aren't busy, a value of 50 instead of the default 75 should be a good bet.
"Busy master nodes should have a lot of spare heap. Then, lowering InitiatingOccupancyFraction trades overhead for throughput, lowering chances of OOM or allocation failures."
Increasing the size of eden and survivor spaces might also help here. When processing many cluster state updates, used heap becomes garbage rather quickly (e.g., after each update). Larger young generations should push more work on the Parallel Collector that works on it. And the Parallel Collector has better throughput.
Here's how to double the Survivor spaces, while increasing the Eden space by a third:
-XX:NewRatio=1 # defaults to 2 -XX:SurvivorRatio=6 # defaults to 8 Note that verbose GC logs can give more details on how long each part of the GC process took. This, in turn, gives you more insight on the root cause. You can enable verbose GC logging from jvm.options: they are written but commented by default.
Parallel Collector
Since giving more heap to the Parallel Collector works with CMS, why not use the Parallel Collector everywhere? The Parallel Collector trades latency for throughput - and we can't let GC pause Elasticsearch for too long. Yet, if heaps are small (like the default 1GB), this won't be a problem, and the Parallel Collector might actually be the best choice. We went on to test this claim:
- Took an Elasticsearch node with 1GB of heap and 4 vCPUs, which is pretty common for dedicated masters.
- Ran a script that continuously generated cluster state update changes (by adding new fields to the mapping).
- Monitored heap and GC times with SPM.
- Sent pending update times as reported by _cat/pending_tasks to Logsene and plotted them with Kibana.
We ran this with the default CMS settings and then we removed them and tried again. Removing GC settings, on the Java 8 test machine, meant using the Parallel Collector. While comparing them, GC overhead dropped by about 20% with the Parallel Collector:
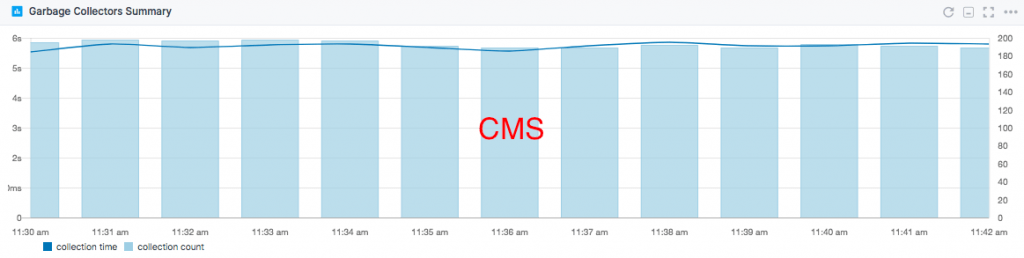
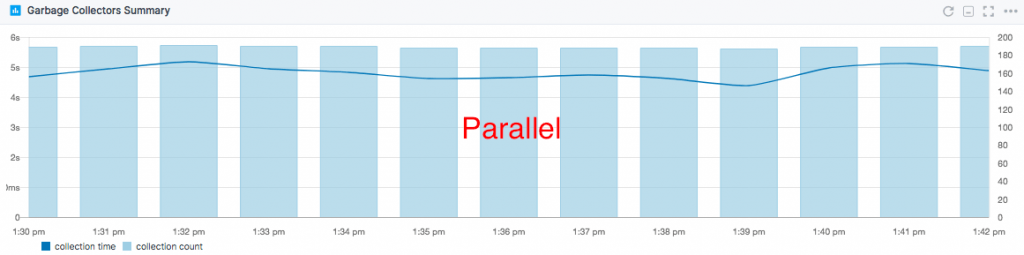
While that's expected (we're using a higher throughput collector), it's nice to see that individual collection times dropped by the same 20%. Values were small in both cases, too small to be logged in the Elasticsearch default logs.
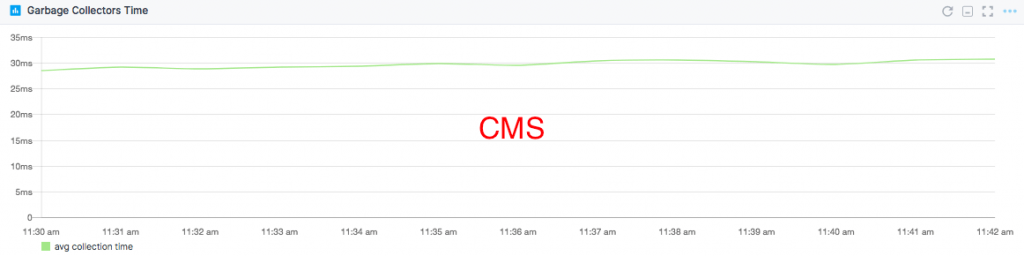
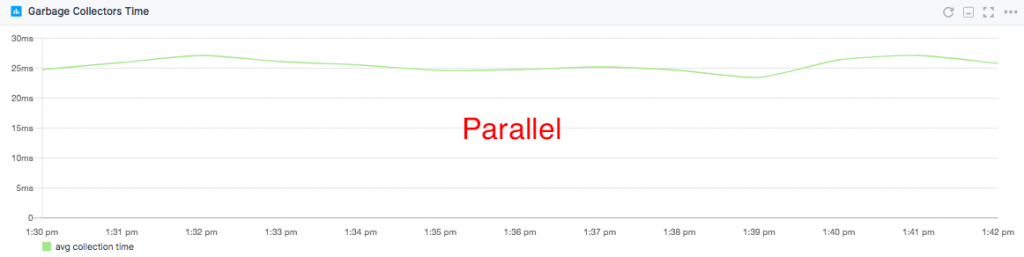
The average time spent in queue also dropped by 20% with the Parallel Collector. This means Elasticsearch can process cluster state updates 20% faster. Here's the timeframe where we had 25-28K fields in the cluster state:
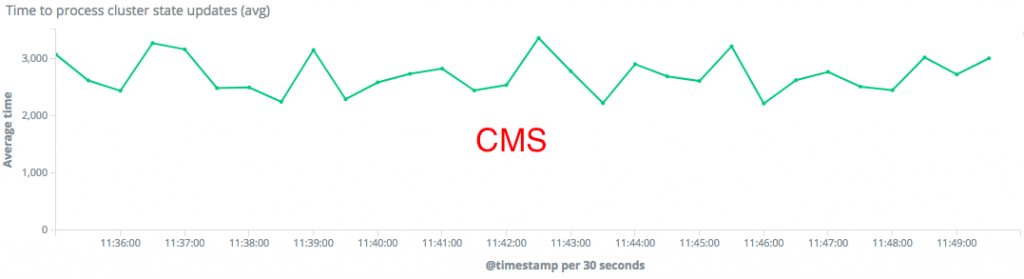
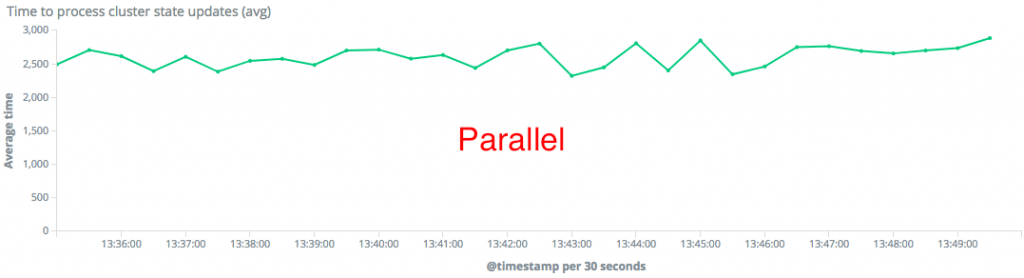
"For dedicated master nodes with 1GB of heap, Parallel Collector outperformed CMS by 20% on both throughput and latency."
G1 Garbage Collector
If heap size is large (e.g. 8GB or higher), the G1 GC might help, especially if you are running Elasticsearch on Java 9. It actually did help a few of our customers in this very situation: master nodes running out of heap during cluster restart. G1 defragments heap and adapts generation sizes based on previous collection information. With larger heaps, it tends to have better throughput than CMS. Some people advise against it, but we had mostly good experience with G1 on both Elasticsearch and Solr. To enable G1, replace the default GC configuration in jvm.options:
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly with:
-XX:+UseG1GC -XX:MaxGCPauseMillis=400 This enables G1 and sets a target pause time to 400ms. The default is 200ms, but increasing MaxGCPauseMillis will trade some latency for throughput. Normally, you'd start with default values and then tune. In this case, though, you probably don't have many shots at fixing the problem, which most likely came up unexpected.
"Master nodes with large heaps benefit from G1 GC. Relaxing MaxGCPauseMillis allows for more throughput."
Speaking of time pressure, if you can quickly throw more hardware at the problem, it might actually be your safest bet. Without looking in the heap dump, which also takes time, it's hard to tell if the problem is with GC throughput or whether there's simply not enough heap. Bigger boxes will address both scenarios: more RAM can hold a bigger heap, giving more headroom. A GC running on more threads will also collect garbage faster.
Conclusions
The default GC configuration works well for most use-cases. That said, when cluster state is large and starts receiving a lot of updates (like in a full cluster restart), the active master may run out of heap. In this situation, often a large part of the heap is garbage, and tuning the GC for throughput might help:
- If heap is small (e.g. 1GB), the Parallel Collector is likely the best.
- If heap is "moderate" (e.g. 4GB), the default CMS can be tuned for more throughput by increasing the young generation. Making old generation GC kick in earlier should also help.
- If heap is larger (e.g. 8+GB), you might be better off with G1 GC. Increasing the pause target will help with throughput even further.
Published at DZone with permission of Radu Gheorghe. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments