Gatling vs. JMeter
What's the max amount of threads you can run with each tool before you start getting errors or saturating a basic resource? Is there significantly different resource use?
Join the DZone community and get the full member experience.
Join For Freein this post, we share our results from the experiment conducted by abstracta’s own santiago peraza and pablo barceló, in which the objective was to make a comparative benchmark between gatling and jmeter tools, in versions 2.2.2 and 3.0 respectively.
aim of the experiment
we wanted to answer these questions:
-
what is the maximum amount of threads i can run with each of the tools before i start getting errors or saturating some basic resource?
-
given the same load generated by both tools, is there a significantly different resource use?
test configuration
the experiment had only one variable: the tool. the rest we kept the same: infrastructure, test, load scenario, system under test, network, etc.
infrastructure for the test
to carry out the test, we decided that the best option was to use two machines, both connected to the same router through two ethernet connection cables and generate load by making requests from one to the other. for that, we installed in one of the pcs (laptop a) the microsoft iis software, which converts one pc into a web server, and we used the other pc (laptop b) as a load generator. the laptops had 6gb of ram and an intel core i5-5200u of 2.20ghz with two cores and four threads per core.
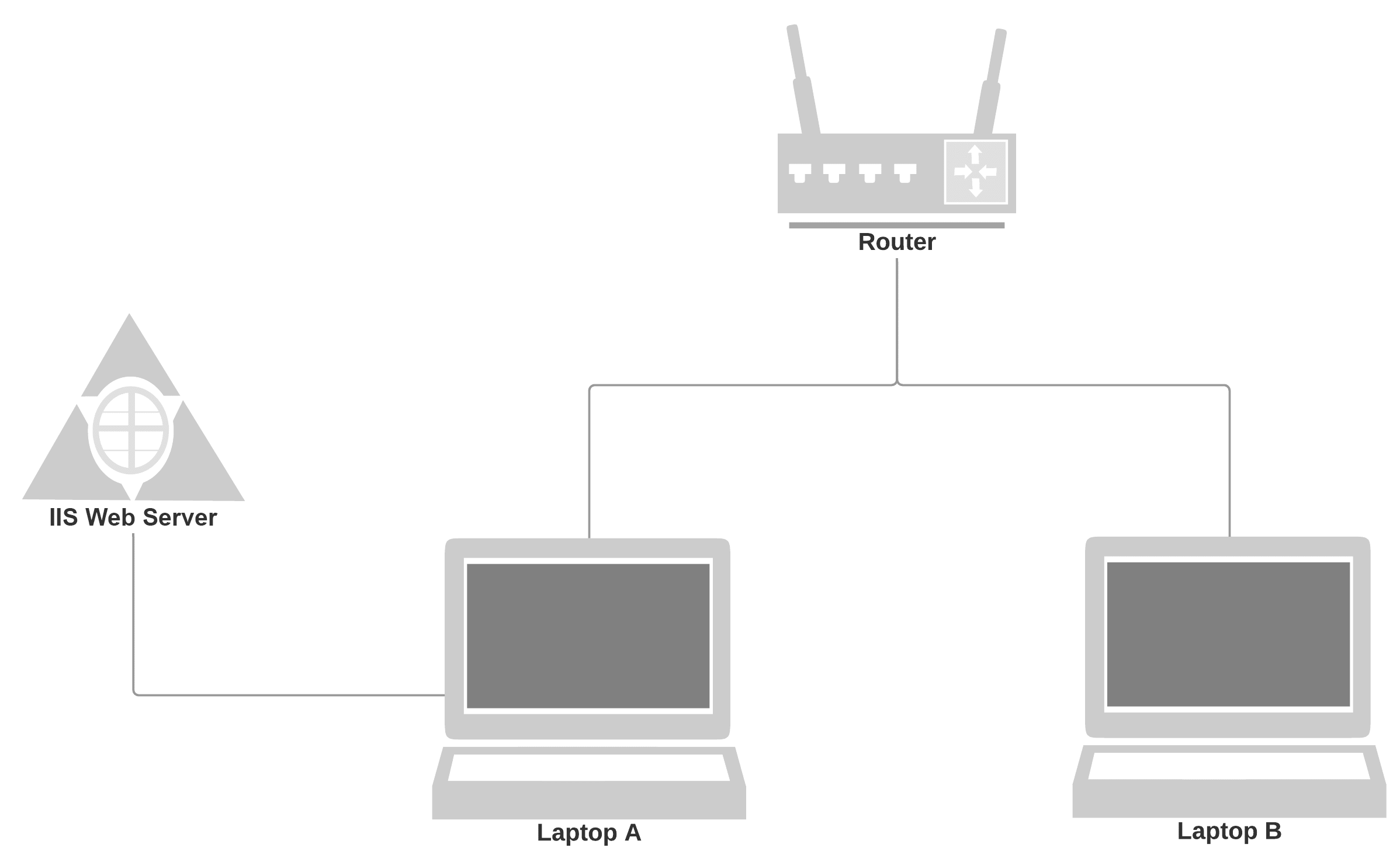 configuration considerations
configuration considerations
to make the comparison as fair as possible, it was necessary to take into account some factors that may affect performance, such as secondary orders, cookies, and cache. gatling handles cookies and cache by default. however, that is not so in the case of jmeter. therefore, it was necessary to configure the tools in the same way to avoid biased results.
cache
at the moment of defining the test you can choose to use the cache management (in that case it is necessary to add an element of the type http cache manager in jmeter) or without handling the cache (in this case it is necessary to disable the handling of cache by gatling, adding the disablecaching line in the http protocol configuration). in our case, we chose to disable the handling of the cache in gatling in order to generate a greater load during the tests.
secondary requests
both gatling and jmeter do not invoke the default secondary requests, so in the gatling script, we included the inferhtmlresources line. in jmeter, we enabled the retrieve all embedded resources option of the http request.
cookies
keeping in mind that we made the requests on a static website, it was not necessary to take into account the handling of the cookies.
test scenario
we prepared the following scenario in both tools:
-
an incremental number of virtual concurrent users, using a one-minute ramp-up on all executions.
-
endless and constant iterations for the duration of the test.
-
test duration: five minutes.
test scripts in gatling and jmeter
the scripts were very simple and both did the same thing.
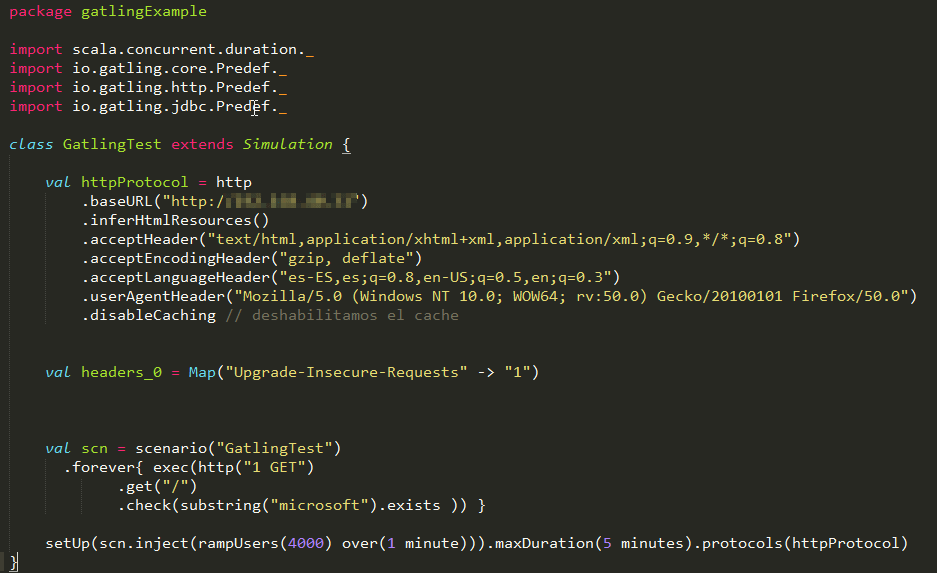
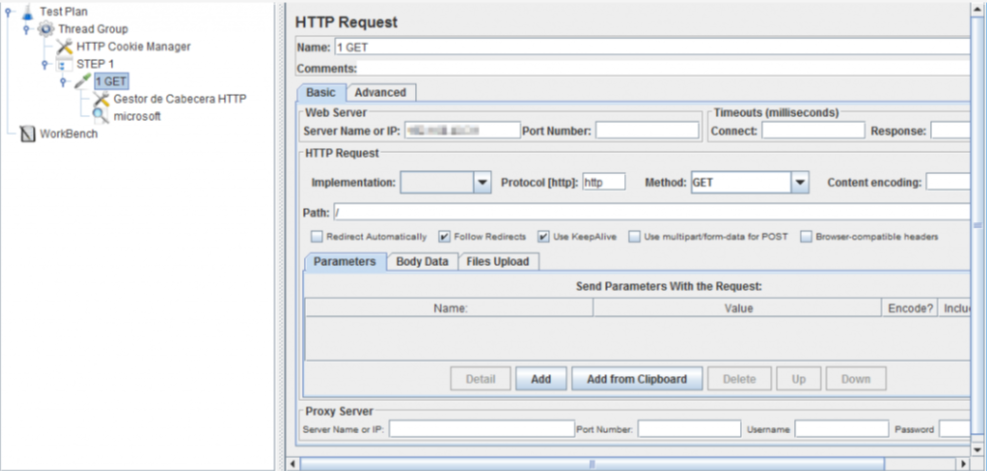
here are the results.
different handling of connections and threads
the first result was that jmeter handled connections differently, which made it necessary to make an adjustment at the operating system level in order to reach the same number of concurrent virtual users.
connections
in a first instance with jmeter simulating 400 users, we observed connection errors (non-http response code:
java.net.bindexception
). these errors are caused by limits at the operating system level. in particular, we were using windows where tcp and ip connections use the ports 1024-5000 output, so if many connections are generated in a short time, these ports become saturated. to avoid this problem, you must increase the number of ports available for connections by following the steps described on this
page
.
in turn, using gatling, we managed to run tests with up to 4,000 concurrent virtual users without encountering this problem. in order to find an explanation for why this limitation is present in one tool and not in the other, we did some further investigating, arriving at the hypothesis that the explanation is in how these tools handle connections:
-
gatling: according to what i understand of what is explained here , gatling handles a pool of connections per virtual user, but the important thing is that in the sequential requests, it reuses connections by default.
-
jmeter: according to what is discussed here , jmeter does not. additionally, the jmeter documentation mentions: there is no control over how connections are reused. when a connection is released by jmeter, it may or may not be reused by the same thread.
threads
related to the above, there is another interesting aspect that differentiates how each tool works with respect to the management of virtual users. in the case of jmeter, we have processes that make synchronous requests, and gatling handles an asynchronous process through the use of handlers. this octoperf article explains the differences quite clearly. both have the possibility to manage a pool of connections per user, which in the case of having several secondary orders, (something that didn’t happen in our experiment), they are done in parallel as the browsers usually do. in gatling this is the default configuration, with a maximum of six simultaneous connections; in jmeter, you have to specify it.
the amount of load in which we see failures in the results is similar
as we did not try to split hairs, we did not look for the exact amount of users before which it is saturated, the order is the same, there is no significant difference. with both tools, the load of 4,000 virtual users was generated, where we began to see that the http requests failed, which indicated that the results can not be trusted. this actually happened due to saturation as much as on the generator side as the server side, but by looking at the resources, the main saturation was observed on the laptop where the load generator was running.
number of users that each tool can generate without saturating the cpu
although it seems absurd, the maximum number of virtual users that can be generated without reaching 100% cpu of the machine with which the load is generated is four. this is the same with both tools, and running five concurrently “eats up” 100% of the cpu during the whole test.
this is explained by the fact that they are requests one after another, without pauses between each and the responses are almost immediate, whereby each thread is constantly working. i expected a very different result in this regard, but that was how it turned out.
faced with 4k virtual users, there was a different use of resources
let’s look at the basic monitoring graphs produced on the laptop of the load generator to analyze the differences. first, the execution of jmeter marked in red:

then the execution with gatling marked in red:

observations
-
although both were using 100% of the cpu, in the case of jmeter, there was a greater use of cpu by the system, which could be due to it having more threads to handle the virtual users.
-
gatling uses less memory than jmeter. you can see in the graph that jmeter uses almost 100%, or almost 6gb, and gatling uses a little more than 4gb, or about 30% less. this could also be explained by the handling of threads since gatling needs fewer threads in memory than jmeter for the same number of virtual users.
-
gatling seems to use more network, which would not make sense unless it generated more load. if jmeter generated less load, it is because it was more saturated and perhaps it could not execute with the same intensity as gatling.
-
gatling used less disk than jmeter, and the curious thing is that the majority in jmeter are readings. here we are lacking a little more analysis to see what is the reason for this difference, but since it doesn’t mean it’s a bottleneck, we did not find it too important.
in closing
in conclusion, while there is not much difference between the load supported by gatling and jmeter, the latter requires extra initial configuration and also uses about 30% more ram than gatling.
Published at DZone with permission of Federico Toledo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments