Generating Simulated Streaming Data
In this article, learn more about using the Python library, Faker, to build synthetic data for tests and utilize Pulsar to send messages to topics at scale.
Join the DZone community and get the full member experience.
Join For FreeFor demos, system tests, and other purposes, it is good to have a way to easily produce realistic data at scale utilizing a schema of our own choice.
Fortunately, there is a great library for Python called Faker that lets us build synthetic data for tests. With a simple loop and a Pulsar produce call, we can send messages to topics at scale.
pip3 install Faker
Let's build a topic to send data to as below:
bin/pulsar-admin topics create persistent://public/default/fakeuserStep 1:
We build a Faker record by adding providers to the Faker object.
from faker import Faker
from faker.providers import internet, address, automotive, barcode, company, date_time, geo, job, misc, person
from faker.providers import phone_number, user_agent
fake = Faker()
fake.add_provider(internet)Step 2:
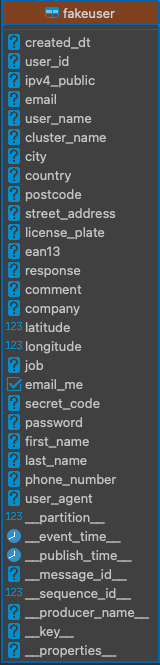
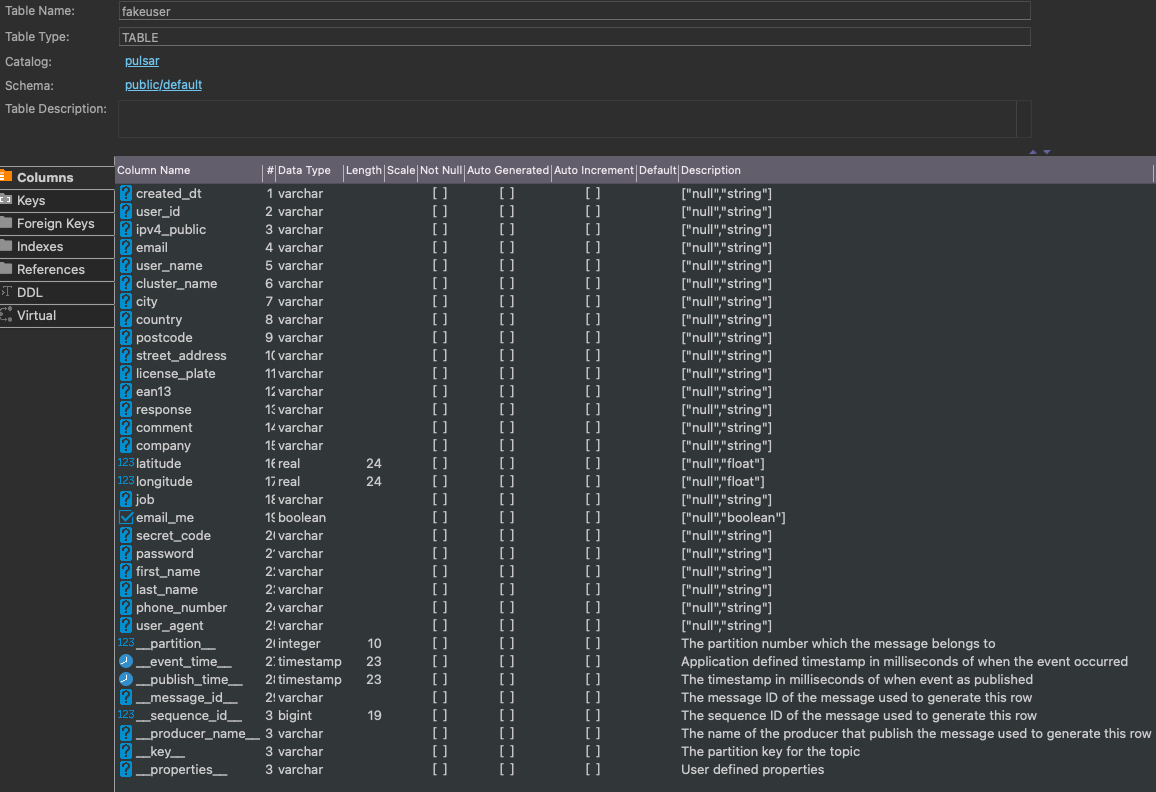
Create or Import Your Schema to model your data and have consistent data in your Pulsar topic for consumers to consume.
# Pulsar Message Schema
class PulsarUser (Record):
created_dt = String()
user_id = String()
ipv4_public = String()
email = String()
user_name = String()
cluster_name = String()
city = String()
country = String()
postcode = String()
street_address = String()
license_plate = String()
ean13 = String()
response = String()
comment = String()
company = String()
latitude = Float()
longitude = Float()
job = String()
email_me = Boolean()
secret_code = String()
password = String()
first_name = String()
last_name = String()
phone_number = String()
user_agent = String()Step 3:
Connect to your cluster and build a producer.
client = pulsar.Client('pulsar://pulsar1:6650')
producer = client.create_producer(topic='persistent://public/default/fakeuser',
schema=JsonSchema(PulsarUser),
properties={"producer-name": "fake-py-sensor","producer-id": "fake-user" })Step 4:
Create records (you can do this in a finite or infinite loop).
userRecord = PulsarUser()
uuid_key = '{0}_{1}'.format(strftime("%Y%m%d%H%M%S",gmtime()),uuid.uuid4())
userRecord.created_dt = fake.date()
userRecord.user_id = uuid_key
userRecord.ipv4_public = fake.ipv4_public()Step 5:
Send record:
producer.send(userRecord,partition_key=str(uuid_key))An example row of produced JSON data is as follows:
{
'created_dt': '1974-01-07',
'user_id': '20220304192446_045a2724-6f9e-4968-ae19-a5a1a095e57b',
'ipv4_public': '207.116.194.88',
'email': '[email protected]',
'user_name': 'qpearson',
'cluster_name': 'memory-story-see',
'city': 'Elizabethview',
'country': 'Mauritius',
'postcode': '01045',
'street_address': '352 Rodriguez Rue',
'license_plate': '6-79707I',
'ean13': '3151191404713',
'response': 'Quality-focused logistical conglomeration',
'comment': 'implement value-added relationships',
'company': 'Harper LLC',
'latitude': 88.5392145, 'longitude': -7.466258,
'job': 'Development worker, community',
'email_me': None,
'secret_code': '28b5519f4bb38cd9fc52aa9bb7bca1aa',
'password': '+5u&%TTkHt',
'first_name': 'Johnny',
'last_name': 'Hoffman',
'phone_number': '9669534677',
'user_agent': 'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.2; Trident/3.1)'
}We can check that our schema is loaded for the topic with the following command.
bin/pulsar-admin schemas get persistent://public/default/fakeuser
We can consume the test messagges with a command line consumer.
bin/pulsar-client consume "persistent://public/default/fakeuser" -s fakeuser-consumer -n 0
We can query the topic like a table via Pulsar SQL.
Source
Opinions expressed by DZone contributors are their own.
Comments