Supervised Fine-Tuning (SFT) on VLMs: From Pre-trained Checkpoints To Tuned Models
Generate QA pairs with a VLM, filter them using another VLM as a judge, then fine-tune your model on the cleaned data. No human labels needed.
Join the DZone community and get the full member experience.
Join For FreeVision-Language Models (VLMs) like LLaMA are becoming increasingly powerful at understanding and generating text grounded in visual content. They excel at tasks like image captioning, visual question answering (VQA), and multimodal reasoning—making them highly useful in a wide range of real-world applications.
But while these models perform impressively out of the box, domain-specific or task-specific use cases often demand additional tuning. This is where Supervised Fine-Tuning (SFT) comes in. By fine-tuning a pre-trained VLM on curated image–question–answer (QA) pairs, we can significantly improve its performance for specific applications.
The catch? Collecting these QA pairs manually is time-consuming and expensive.
To get around this bottleneck, we turn to synthetic data generation. By using a powerful VLM to generate QA pairs and a second model to filter (or “judge”) the quality of the outputs, we can scale dataset creation without needing human annotators. This technique unlocks scalable fine-tuning for teams without access to large, labeled datasets or annotation pipelines.
Creating Synthetic Data for Fine-Tuning
Our pipeline consists of two core components:
1. A large vision-language model to generate QA pairs
2. A separate VLM to evaluate and filter those pairs
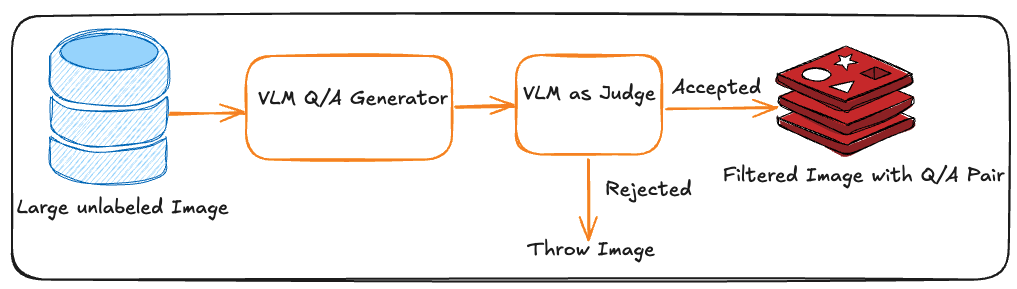
In this setup:
- Teacher model: [meta-llama/Llama-3.2-90B-Vision-Instruct] – We use a powerful 90B parameter instruction-tuned vision-language model (VLM) to generate high-quality question-answer (QA) data. Leveraging a large-scale model for QA generation is critical, as it typically produces more coherent, contextually grounded, and instruction-following outputs. However, for the evaluation phase, it is equally important to use a separate, comparatively smaller model to serve as the Judge. This separation of roles ensures an unbiased assessment of the generated content. Using the same model family or even the same model instance for both generation and evaluation can lead to overfitting-like behavior, inflated scores, or biased judgments. Therefore, maintaining model diversity between the generator and the evaluator is a recommended best practice in multimodal QA pipelines.
- Judge model: [Qwen/Qwen2.5-VL-7B-Instruct] – a 7B parameter vision-language model used to assess both the relevance and correctness of each QA pair. Importantly, this evaluator belongs to a different model family than the generator, which helps reduce bias and is widely regarded as a best practice for more objective and robust quality evaluation.
- Optional: Human-in-the-Loop (HITL) Verification – While automated judgment using a smaller, distinct VLM is efficient and scalable, incorporating a human-in-the-loop adds an additional layer of quality assurance. In practice, this means randomly sampling a subset of the model-judged QA pairs and having human annotators review their relevance, correctness, and overall clarity. This not only validates the accuracy of the Judge model’s assessments but also helps calibrate or fine-tune its scoring thresholds over time. In high-stakes or production-grade systems, occasional human review ensures that edge cases or nuanced content—where even strong models may falter—are caught and corrected. Though optional, HITL is a valuable tool for maintaining long-term trust and reliability in the QA evaluation pipeline.
Step 1: Load the QA Generator Model
from transformers import AutoTokenizer, AutoProcessor, AutoModelForCausalLM
import torch
llama_gen_id = "meta-llama/Llama-3.2-90B-Vision-Instruct"
llama_tokenizer = AutoTokenizer.from_pretrained(llama_gen_id)
llama_processor = AutoProcessor.from_pretrained(llama_gen_id)
llama_model = AutoModelForCausalLM.from_pretrained(
llama_gen_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)We’ll use this model to generate synthetic QA data. Here’s the core function:
from PIL import Image
def generate_qa(image: Image.Image):
prompt = (
"You are an AI that sees the image and explains it to a human.\n"
"Generate a meaningful question someone might ask about this image, and provide an accurate answer.\n"
"Respond in the format:\nQuestion: ...\nAnswer: ..."
)
inputs = llama_processor(text=prompt, images=image, return_tensors="pt").to(llama_model.device)
outputs = llama_model.generate(**inputs, max_new_tokens=150)
output_text = llama_processor.batch_decode(outputs, skip_special_tokens=True)[0]
return output_textStep 2: Load the VLM Judge Model
We now load a smaller model to act as a “judge” that filters out low-quality QA pairs.
from transformers import AutoModelForVision2Seq
qwen_id = "Qwen/Qwen2.5-VL-7B-Instruct"
qwen_processor = AutoProcessor.from_pretrained(qwen_id)
qwen_model = AutoModelForVision2Seq.from_pretrained(
qwen_id,
device_map="auto",
torch_dtype=torch.bfloat16
)The judge evaluates whether the generated answer correctly addresses the question in context of the image:
def judge_qwen(image: Image.Image, question: str, answer: str):
judge_prompt = (
f"<img>\nYou are an expert evaluator. Assess if the answer is correct and relevant to the question.\n"
f"Question: {question}\nAnswer: {answer}\n\n"
f"Reply with only 'yes' or 'no'."
)
inputs = qwen_processor(text=judge_prompt, images=image, return_tensors="pt").to(qwen_model.device)
output = qwen_model.generate(**inputs, max_new_tokens=10)
response = qwen_processor.batch_decode(output, skip_special_tokens=True)[0].lower()
return "yes" in responsePrompt Tuning:
In both generate_qa() and judge_qwen(), the prompt is the quiet driver behind output quality. In generate_qa(), the instruction to “generate a meaningful question… and provide an accurate answer” guides the model toward thoughtful, grounded outputs. Changing that phrasing—even slightly—can lead to less relevant or overly generic QA pairs. In judge_qwen(), the prompt explicitly asks for a simple “yes” or “no” on correctness and relevance. Without this clear instruction, the model might generate vague or verbose responses that derail automated evaluation. These examples show how critical prompt tuning is. The model may be powerful, but without clear, task-aligned prompts, the pipeline won’t behave as expected. Small wording changes can make or break consistency—so tuning prompts is as essential as picking the right models.
import os
from PIL import Image
image_folder = "/path/to/images"
accepted_data = []
def parse_qa(text):
if "Question:" in text and "Answer:" in text:
q = text.split("Question:")[1].split("Answer:")[0].strip()
a = text.split("Answer:")[1].strip()
return q, a
return None, None
for file in os.listdir(image_folder):
if not file.lower().endswith((".png", ".jpg", ".jpeg")):
continue
image_path = os.path.join(image_folder, file)
image = Image.open(image_path).convert("RGB")
try:
qa_text = generate_qa(image)
question, answer = parse_qa(qa_text)
if not question or not answer:
continue
if judge_qwen(image, question, answer):
accepted_data.append({
"image_path": image_path,
"question": question,
"answer": answer
})
except Exception as e:
print(f"Error processing {file}: {e}")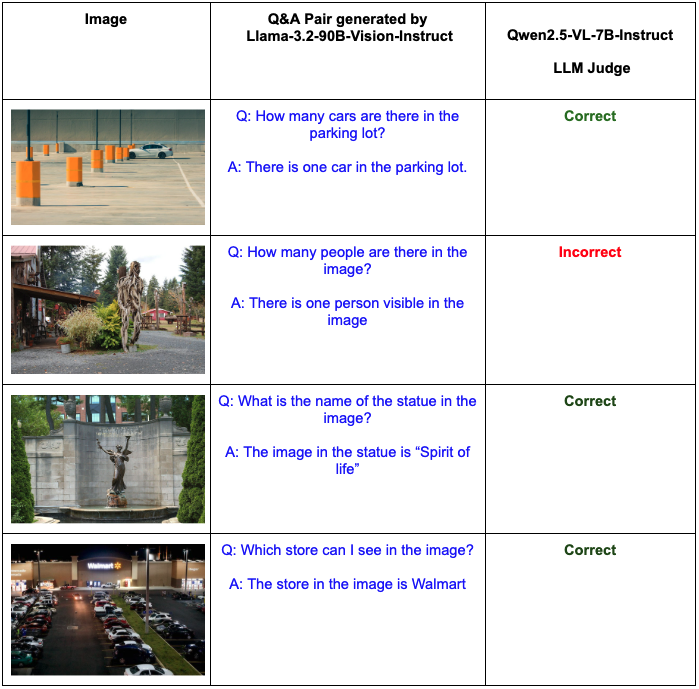
Conclusion
Fine-tuning Vision-Language Models no longer requires massive investments in human-annotated data. By combining a high-quality generator (LLaMA-3.2-90B-Vision-Instruct) with a competent evaluator (Qwen2.5-VL-7B-Instruct), we can produce large-scale, high-quality QA datasets fully automatically.
This cleaned and validated synthetic dataset can then be used to fine-tune a smaller model—like LLaMA-3.2-11B-Vision—to inherit task-specific capabilities with lower training cost and faster inference.
This teacher–judge–student paradigm opens the door to scalable model customization, making it possible to adapt powerful VLMs for specialized domains like medical imaging, robotics, or enterprise knowledge systems—without needing armies of annotators or proprietary data.
Have a really great day!
Opinions expressed by DZone contributors are their own.
Comments