Generative Engine Optimization: How to Make Your Content Visible to AI
Generative engine optimization (GEO) helps content get cited by AI tools like ChatGPT and Perplexity using structure, authority, and semantic clarity.
Join the DZone community and get the full member experience.
Join For FreeThere was a time when SEO meant stuffing keywords into meta tags to be noticed by Google's crawler. That changed over time, and the approach was refined with structured data, backlinks, page authority, and semantic search.
Now the rules are changing again. People are no longer just typing queries into a search engine and browsing the blue links. They ask ChatGPT, Perplexity, Claude, or Gemini, and they get a direct answer. If an AI answers the question, your carefully optimized page is invisible, even if it ranks #1 on Google.
This is the challenge that generative engine optimization (GEO) is designed to solve. The question is no longer just "how do I rank for this keyword?" It is "How is my page referred to and cited by an AI?"
What Is GEO?
Generative engine optimization is the practice of structuring, framing, and distributing the content so that large language models and AI-powered answer engines are more likely to surface, summarize, and cite it in their responses.
Traditional SEO optimizes for crawlers and ranking algorithms. GEO optimizes for the way language models synthesize information. These are fundamentally different problems, and the signals that drive each are not the same. A search engine ranks pages, while a language model generates answers.
Research by Aggarwal, Pranjal, et al. (2024) found that certain content strategies measurably improved citation rates in AI-generated responses. This includes citing authoritative sources, using statistics, and structuring content with clear authoritative statements. That paper arguably gave GEO its name as a formal discipline.
How AI Answer Engines Select Content
To optimize for AI, you need to understand how AI engines work at a high level. Systems like Perplexity and ChatGPT that use web browsing employ a retrieval-augmented generation (RAG) pipeline. They retrieve candidate content from the web or a corpus, rank it by relevance and authority, and then use a language model to synthesize a response from the top results.
What this means for content creators is that two filters must be passed. First, the retrieval layer must pull your content as a candidate. This still depends on indexability, authority, and relevance. Second, the synthesis layer must prefer your content as a source. This depends on clarity, structure, specificity, and trustworthiness signals within the text itself.
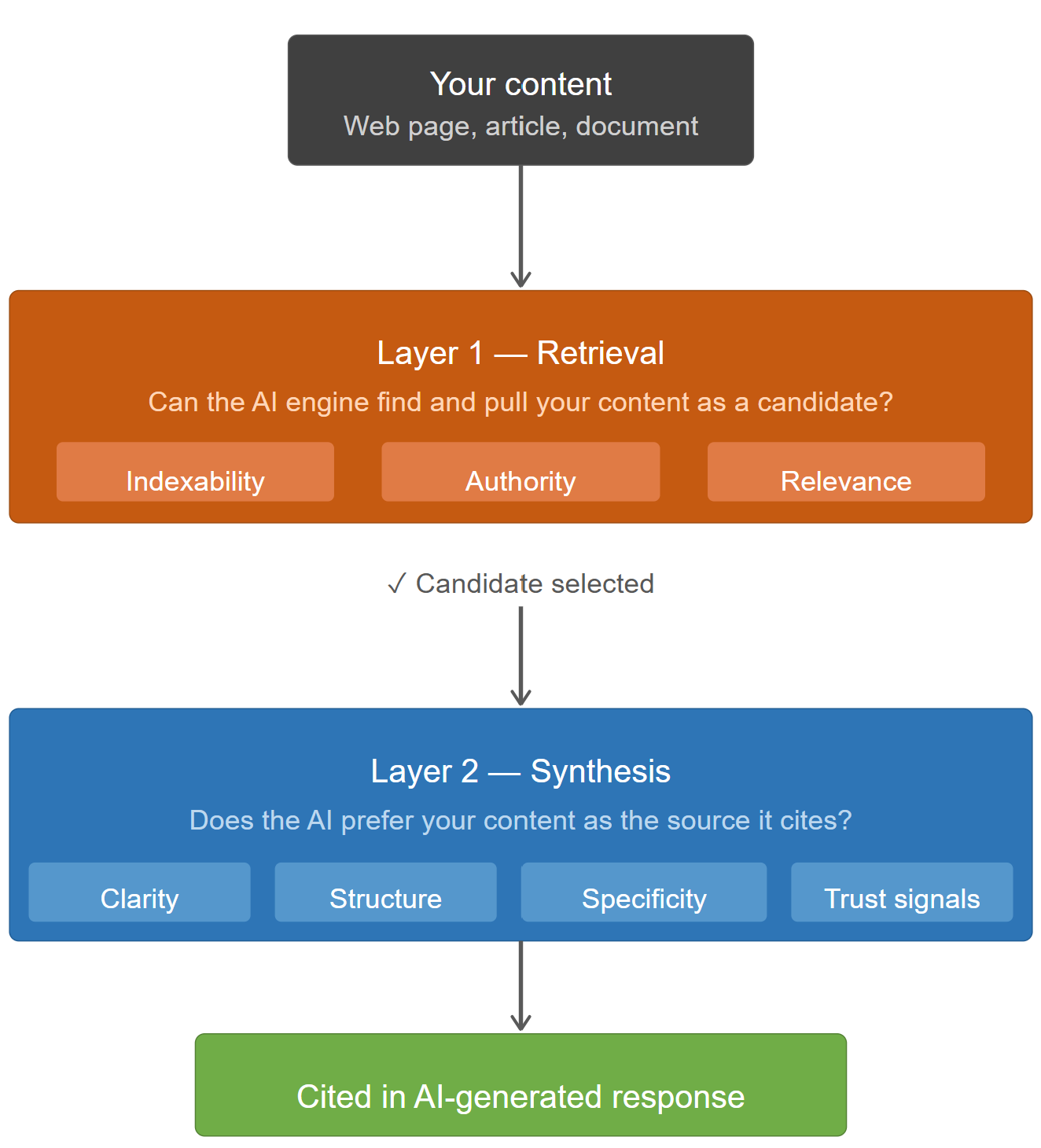
The Core Principles of GEO
- Inverted pyramid style structures: Language models respond well to content that directly answers a question before elaborating. The inverted pyramid style, which leads with the conclusion and supports with detail, performs better than narrative-first writing in AI retrieval. If someone asks "what is transfer learning?", the best-optimized content starts with a precise one or two-sentence definition, not a historical introduction to neural networks.
- Authoritative and statistical language: Vague claims do not get cited. The statements should be specific and verifiable. For example, "Studies show that transformer models outperform RNNs on long-range dependencies in NLP benchmarks" is more likely to be surfaced than "transformers are very powerful". Name your sources inline and include statistics with context.
- Structure for semantic clarity: Clear section headers, short paragraphs, and distinct topic boundaries help the retrieval layer understand what each section of your content is about. Long, undivided prose is harder for embedding-based retrieval to segment meaningfully.
- Building topical authority, not just page authority: A single high-quality article is less effective than a cluster of well-linked content that covers a topic comprehensively. AI systems trained on or retrieving from the web reward entities that are consistently associated with a domain.
- Schema markup and structured data: FAQ Pages and how-to articles signal to crawlers that your content is structured for direct answers. This is exactly what AI answer engines want.
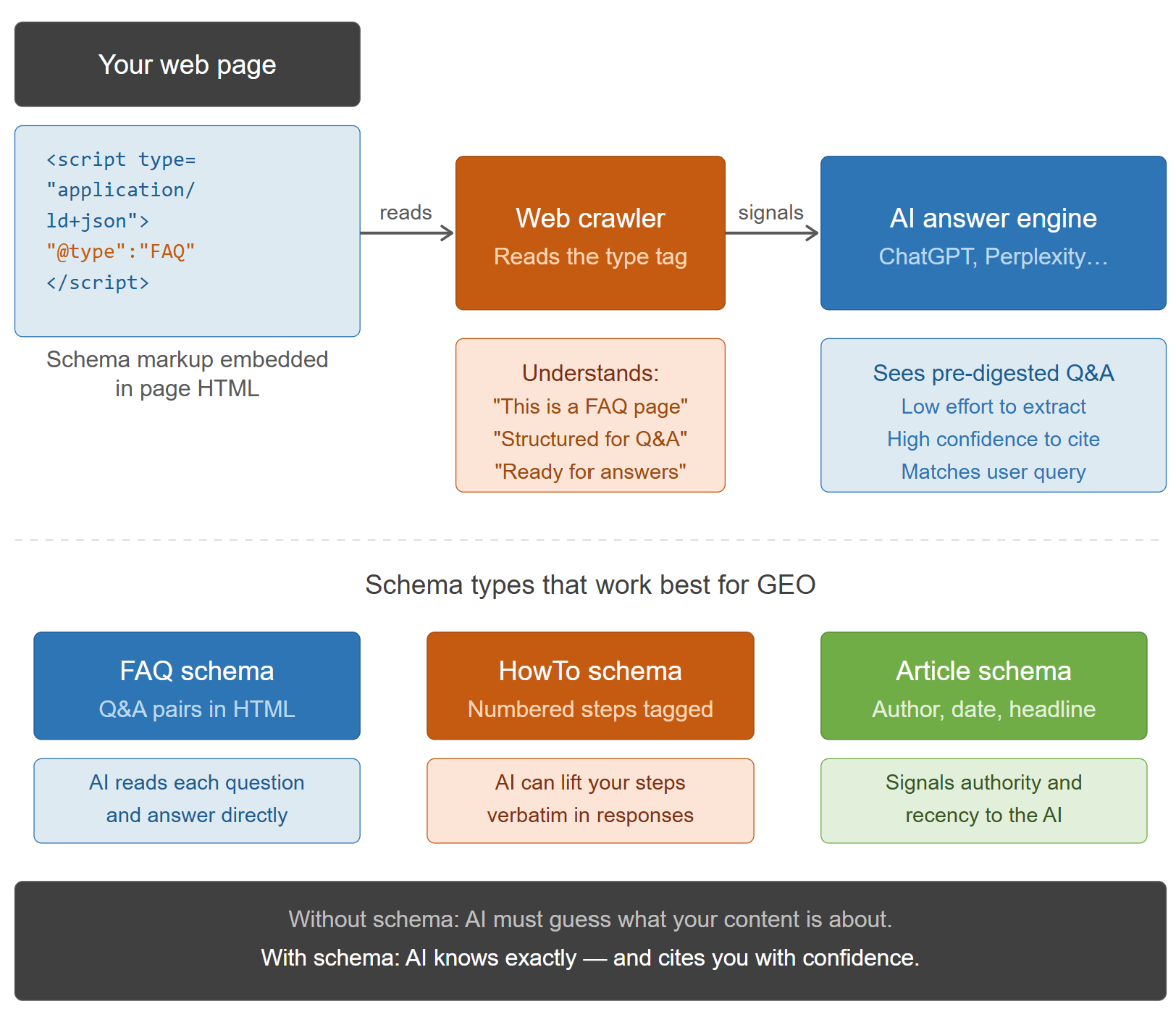
Optimizing a Technical Article for GEO
Let us take a concrete example. Suppose you are publishing a technical guide on vector databases for an engineering audience on DZone. Here is how a standard article might look versus a GEO-optimized version.
Standard Version (Traditional SEO Focus)
Vector databases have become increasingly popular in recent years.
Many companies are exploring ways to use them for AI applications.
In this article, we will explore what vector databases are, why they matter, and how you can get started with
one.This opens with vague trend language. It has no direct answer. It does not cite anything. An AI retrieving content to answer "what is a vector database?" would likely skip this paragraph entirely.
GEO-Optimized Version
A vector database stores data as high-dimensional numerical vectors rather than rows and columns. It is
designed for similarity search. That includes finding records that are semantically close to a query, even when there is
no exact keyword match. Pinecone, Weaviate, and Chroma are three widely used options in production AI pipelines.
According to the 2024 State of Vector Databases report by Gradient Flow, 62% of enterprise AI teams now use a
dedicated vector store as part of their RAG architecture. The primary use cases are semantic search,
recommendation systems, and retrieval augmented generation for large language models.This version answers the question immediately and names specific tools. It includes a concrete statistic with a named source. It also uses clear and specific language throughout. An AI synthesizing an answer about vector databases has something concrete and citable here.
A Practical GEO Checklist You Can Apply Today
Before you publish any technical article, run through these checks.
- Does the first paragraph directly answer the primary question the article targets? If not, rewrite the opening. The synthesis layer reads the top of your content first.
- Does each major section have a standalone answer within the first two sentences? Section headers alone are not enough. Each section should be self-contained enough that it could be excerpted and still make sense.
- Have you named tools, frameworks, or platforms specifically? Vague references to "popular libraries" or "modern tools" do not get cited. Mention the libraries and version. For example, "LangChain v0.2 with a Chroma vector store".
- Have you included at least one quantitative claim with a named source? Even a single specific statistic increases the perceived authority of the surrounding content.
- Is your content marked up with appropriate schema? For technical how-to content, the HowTo schema is appropriate. For FAQ-style content, FAQPage schema. Adding this improves structured retrieval.
- Is your content internally linked within a topic cluster? A single isolated article is harder to surface than one that is part of a well-connected knowledge base on your site.
Audit Your Own Content for GEO Signals
You can build a lightweight audit tool using Python and the OpenAI or Anthropic API to score your draft content against GEO heuristics before publishing.
Each dimension is scored on a 1–10 scale with a clear definition of what each band means:
- Answer-first structure measures whether the content leads with a direct, extractable answer before elaborating. A score of 1–3 means the opening buries the answer in background context. A score of 4–6 means the answer appears mid-paragraph, readable but not retrieval-friendly. A score of 7–10 means the first one or two sentences directly answer the target question that makes the paragraph independently citable.
- Specificity measures whether tools, frameworks, platforms, and methods are named concretely rather than referenced generically. A low score signals phrases like "popular libraries" or "modern approaches". A high score means the content names Pinecone, LangChain, FastAPI, or whichever tool is actually relevant, with enough context that a reader — or a language model — can act on the reference.
- Statistical authority measures the presence of quantitative claims tied to named sources. A score below 4 means all claims are qualitative and unverified. A score of 7 or above means the content includes at least one specific data point — a percentage, a benchmark figure, a survey result — with a named source that an AI can attribute when synthesizing an answer.
- Semantic clarity measures how cleanly each section or paragraph covers a single topic. Low scores reflect prose that mixes multiple concepts without clear boundaries, making it harder for embedding-based retrieval to segment relevant chunks. High scores reflect tight, single-topic paragraphs with clear headers that scope each section.
- Citability is the composite signal — would an AI synthesis engine actually excerpt this content in a generated answer? It combines the above four dimensions with an overall judgment on trustworthiness, precision, and completeness of the individual claim units within the text.
import anthropic
import json
# Score band definitions used by the auditor and displayed in output
SCORE_DEFINITIONS = {
"answer_first": {
"description": "Does the content lead with a direct, extractable answer before elaborating?",
"bands": {
"1-3": "Answer is buried — content opens with background, history, or context instead of a direct response.",
"4-6": "Answer appears mid-paragraph. Readable, but not optimally positioned for AI retrieval.",
"7-10": "First 1–2 sentences directly answer the target question. The paragraph is independently citable."
}
},
"specificity": {
"description": "Are tools, platforms, frameworks, and methods named concretely rather than generically?",
"bands": {
"1-3": "Relies on vague language: 'popular libraries', 'modern tools', 'various approaches'.",
"4-6": "Names some tools but mixes in generic references. Partially actionable.",
"7-10": "Every relevant tool, framework, or platform is named with enough context to act on."
}
},
"statistical_authority": {
"description": "Are specific data points cited with named, attributable sources?",
"bands": {
"1-3": "All claims are qualitative. No numbers, no named sources.",
"4-6": "Some statistics present but lacking source attribution or precision.",
"7-10": "At least one specific quantitative claim with a named, attributable source."
}
},
"semantic_clarity": {
"description": "Does each paragraph or section cover a single, well-scoped topic?",
"bands": {
"1-3": "Prose mixes multiple concepts without clear boundaries. Hard to chunk for retrieval.",
"4-6": "Mostly clear but some paragraphs blend topics or lack focused headers.",
"7-10": "Each paragraph is a tight, single-topic unit. Section headers precisely scope the content."
}
},
"citability": {
"description": "Would an AI synthesis engine likely excerpt this content in a generated answer?",
"bands": {
"1-3": "Content is too vague, derivative, or unstructured to surface in AI-generated answers.",
"4-6": "Partially citable. Some sections are strong; others would be skipped.",
"7-10": "Precise, trustworthy, and self-contained. High probability of AI citation."
}
}
}
def audit_content_for_geo(article_text: str) -> dict:
"""
Sends article content to Claude and returns a structured GEO signal audit.
Scores each dimension 1–10 with a concrete recommendation.
"""
client = anthropic.Anthropic()
prompt = f"""
You are a content strategist specializing in Generative Engine Optimization (GEO).
Analyze the following article excerpt and score it on these five dimensions (1–10 each):
1. answer_first — Does the content lead with a direct, extractable answer before elaborating?
Score 1–3 if the answer is buried in background. Score 7–10 if the first 1–2 sentences
directly answer the question and are independently citable.
2. specificity — Are tools, platforms, and frameworks named concretely?
Score 1–3 for vague language like "popular libraries." Score 7–10 if every relevant
tool is named with enough context to act on.
3. statistical_authority — Are specific data points cited with named sources?
Score 1–3 if all claims are qualitative. Score 7–10 if at least one quantitative
claim has a named, attributable source.
4. semantic_clarity — Does each paragraph cover a single, well-scoped topic?
Score 1–3 if prose blends multiple concepts. Score 7–10 if each paragraph is a
tight single-topic unit with clear section headers.
5. citability — Would an AI synthesis engine likely excerpt this content?
Score 1–3 if too vague or generic. Score 7–10 if precise, trustworthy,
self-contained, and highly likely to be cited.
For each dimension, provide a score (integer 1–10) and a one-sentence,
actionable recommendation for improvement.
Article:
{article_text}
Respond in this exact JSON format with no preamble or markdown:
{{
"answer_first": {{"score": 0, "recommendation": ""}},
"specificity": {{"score": 0, "recommendation": ""}},
"statistical_authority": {{"score": 0, "recommendation": ""}},
"semantic_clarity": {{"score": 0, "recommendation": ""}},
"citability": {{"score": 0, "recommendation": ""}},
"overall_geo_score": 0,
"top_priority_action": ""
}}
"""
message = client.messages.create(
model="claude-opus-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return json.loads(message.content[0].text)
def get_band_label(score: int) -> str:
"""Returns the score band key for a given integer score."""
if score <= 3:
return "1-3"
elif score <= 6:
return "4-6"
return "7-10"
def print_audit_report(result: dict) -> None:
"""Prints a formatted audit report with definitions, scores, bands, and recommendations."""
print("\n" + "=" * 60)
print(" GEO CONTENT AUDIT REPORT")
print("=" * 60)
dimension_keys = ["answer_first", "specificity", "statistical_authority",
"semantic_clarity", "citability"]
for key in dimension_keys:
if key not in result:
continue
dimension = result[key]
definition = SCORE_DEFINITIONS[key]
score = dimension["score"]
band = get_band_label(score)
band_text = definition["bands"][band]
print(f"\n{'─' * 60}")
print(f" {key.upper().replace('_', ' ')}")
print(f" Definition : {definition['description']}")
print(f" Score : {score}/10 [{band} band]")
print(f" Band Meaning: {band_text}")
print(f" Action : {dimension['recommendation']}")
print(f"\n{'═' * 60}")
print(f" OVERALL GEO SCORE : {result.get('overall_geo_score', 'N/A')}/10")
print(f" TOP PRIORITY ACTION : {result.get('top_priority_action', 'N/A')}")
print("=" * 60 + "\n")
# ── Example: a well-optimized excerpt ─────────────────────────────────────────
strong_sample = """
A vector database stores data as high-dimensional numerical vectors rather than rows
and columns. It is designed for similarity search — finding records that are semantically
close to a query even when there is no exact keyword match.
Pinecone, Weaviate, and Chroma are three widely used options in production AI pipelines.
According to the 2024 State of Vector Databases report by Gradient Flow, 62% of enterprise
AI teams now use a dedicated vector store as part of their RAG architecture.
Each query returns the top-k nearest neighbors from billions of vectors in under 100ms
at production scale using approximate nearest neighbor (ANN) algorithms such as HNSW.
"""
print("AUDITING: Well-optimized excerpt")
result = audit_content_for_geo(strong_sample)
print_audit_report(result)
# ── Example: a weak excerpt that needs improvement ────────────────────────────
weak_sample = """
Vector databases have become very popular lately. Many companies are now exploring ways
to use them in their AI projects. There are several good options available on the market
that teams can choose from. These tools are generally fast and reliable. Getting started
is not too difficult if you follow the documentation.
"""
print("AUDITING: Weak excerpt needing improvement")
result = audit_content_for_geo(weak_sample)
print_audit_report(result)Running the strong excerpt through the auditor produces output like this:
============================================================
GEO CONTENT AUDIT REPORT
============================================================
────────────────────────────────────────────────────────────
ANSWER FIRST
Definition : Does the content lead with a direct, extractable answer?
Score : 9/10 [7-10 band]
Band Meaning: First 1–2 sentences directly answer the target question.
Action : Strong. Consider adding a one-line TL;DR before the definition for skimmability.
────────────────────────────────────────────────────────────
SPECIFICITY
Definition : Are tools, platforms, and frameworks named concretely?
Score : 9/10 [7-10 band]
Band Meaning: Every relevant tool is named with enough context to act on.
Action : Excellent tool coverage. Consider naming the ANN algorithm variant in use.
────────────────────────────────────────────────────────────
STATISTICAL AUTHORITY
Definition : Are specific data points cited with named, attributable sources?
Score : 8/10 [7-10 band]
Band Meaning: At least one specific quantitative claim with a named, attributable source.
Action : Strong. Add the report URL inline for direct verifiability.
────────────────────────────────────────────────────────────
SEMANTIC CLARITY
Definition : Does each paragraph cover a single, well-scoped topic?
Score : 8/10 [7-10 band]
Band Meaning: Each paragraph is a tight, single-topic unit with clear section headers.
Action : Well scoped. A subheading before the benchmark paragraph would help retrieval.
────────────────────────────────────────────────────────────
CITABILITY
Definition : Would an AI synthesis engine likely excerpt this content?
Score : 9/10 [7-10 band]
Band Meaning: Precise, trustworthy, self-contained. High probability of AI citation.
Action : Near publication-ready. Add schema markup to amplify structured retrieval.
============================================================
OVERALL GEO SCORE : 8.6/10
TOP PRIORITY ACTION : Add inline source URL for the Gradient Flow statistic.
============================================================The weak excerpt scores in the 2–3 range across all dimensions, with the top priority action flagging the absence of any specific tool names or data points. These are the signals you need before hitting publish.
The Road Ahead
We are in the early phases of the AI-native web, and the conventions for what makes content discoverable are still being written. The AI search engines are evolving their retrieval and citation logic. The specifics will shift, but the underlying principle will not. If an AI cannot efficiently extract a precise and trustworthy answer from your content, it will not be cited. Your content is the moat. If it is genuinely useful and you structure it well, GEO amplifies the reach. If your content is generic and you apply GEO patterns on top, you are polishing something that will not hold up under the weight of retrieval competition.
The practitioners who figure this out now and who build content strategies designed for both human readers and AI synthesizers will have a compounding advantage over the next three to five years.
Reference
Aggarwal, Pranjal, et al. "Geo: Generative engine optimization." Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 2024.
Opinions expressed by DZone contributors are their own.
Comments