Testing Strategies for Web Development Code Generated by LLMs
LLMs can quickly generate web application code, but AI-written code may contain security vulnerabilities. This article reviews testing methods for LLM systems.
Join the DZone community and get the full member experience.
Join For FreeLarge Language Models (LLMs) can automate the development process by producing a substantial amount of web application code in just a few minutes. Nonetheless, it is important to bear in mind that these models are pattern-based and not deterministic.
Work in the domain of AI programming assistants shows that AI-based code often exhibits security vulnerabilities in real-world testing. A study on GitHub's features showed that approximately 40% of the generated code was susceptible to security issues, emphasizing the need for careful testing and scrutiny.
In other words, programmers and engineers employ a particular mode of working rooted in software methodology, which enables them to tackle this problem straightforwardly and continually incorporate AI-produced code as it is generated.
However, AI speed tends to result in errors being overlooked every now and then. In some instances, project managers allocate more rigorous testing because they have to ensure that what people often call correct code" has become "perfect, functional, and secure code."
Every code that is deemed complete has to go through a number of tests, from simple static checkups and unit tests to more sophisticated integration tests, end-to-end tests, automated checks for security breaches, capacity checks, and manual code reviews, to ensure that the delivered software is functionally good enough and meets the security requirements.
This article presents different testing methods for LLM systems that create HTML code intended for use on the web. Node.js and React are examples of relevant development frameworks used in such software. As an aid to merging the code branches, a pre-merge checklist is also included, along with recommendations on testing the triggers themselves to ensure that the material does not put the security of the system at risk, as far as it is included in the final body of code.
Why AI-Generated Web Code Requires Extra Scrutiny
It is commonly agreed that traditional bugs are caused by human error. Humans are the source of bugs, especially if they are involved in the development processes. This is different in the case of AI-generated bugs. AI generates bugs that are meant to fit in the missing context somehow by the problem model, leading to code that may appear to work on certain testing conditions; hence, it may bypass, but when the conditions change, the code does not.
This lack of logic will mostly be observed at the borders, including the most sensitive parts, such as authentication mechanisms, actions upon ridiculous requests, handling many things simultaneously, reloading, differences in application versions, or vulnerabilities that were enabled due to an incorrect setting of the security defaults.
Security is not just a legal obligation. One study used GitHub Copilot to build the most dangerous code by design without any errors in judgment. The study revealed a non-negligible number of insecure code recommendations, with the wording and context of the instructions playing a significant role in these recommendations. Another study utilizing a more sophisticated methodology with current versions of the software confirmed the drawbacks of generating AI-written code.
This highlights the significance of the efforts made by individuals using LLMs to develop web features, emphasizing the need for substantial changes from the existing methods to move away from the 'it works on my machine' mentality. Harmonization initiatives should mainly focus on the inputs and outputs of the code, emphasizing important factors such as code execution across various test scenarios that simulate real-world conditions, as well as sharing knowledge with the machine.
Testing Layers for LLM-Written Code
The main idea is not to rely on a single test format but to use multiple forms, each targeting different types of 'AI errors.'
To detect fundamental problems, static assessments such as linting and type verification can be performed, which can help identify certain issues early on. It is crucial that these issues are identified and addressed promptly, as they are expected to be easy to detect and fix quickly. A good tool that can be used for this is ESLint, as it detects the code patterns in JavaScript, which is also well or very well adaptable to the best coding conventions of your organization.
npm init @eslint/config@latest
npx eslint src/According to the official documentation of the ESLint tool, it is preferable to execute the following sequence of commands: npm init @eslint/config@latest and then npx eslint on the required files and folders.
It is also worth considering that the ruleset should include those designed for heightened security. For example, there is a security plug-in called eslint-plugin-security that is specifically created to monitor the presence of known security problems in JavaScript and Node.js code. Although there may be instances of information misuse, eslint-plugin-security provides good support for developers.
npm i -D eslint-plugin-securityOnce completed, turn on the appropriate rules in your ESLint configuration, noting that different ESLint setups may require slightly different setup techniques.
During testing, attention should be paid to the more elusive aspects of the program, such as logic algorithms, edge cases, and consistency testing of the generated results. One of the strategies that is readily comprehensible and offered by Jest is to write tests and use the expect() construct that includes tools and the toBe mechanism to confirm the results as desired.
How-to (Node/JS + Jest):
// utils/sanitizeSlug.js
export const sanitizeSlug = (s) => s.trim().toLowerCase().replace(/\s+/g, "-");
// utils/sanitizeSlug.test.js
import { sanitizeSlug } from "./sanitizeSlug";
test("sanitizes slugs", () => {
expect(sanitizeSlug(" Hello World ")).toBe("hello-world");
});A helpful routine for improving an LLM model is to consider assumptions about the input. If the model handles input in the form of “slugs being space-separated”, it must be stated in the code, or there is a danger that this code will lead to bugs during real practice tests.
Component Tests: Test React Like a User, Not Like a Compiler
React Testing Library's emphasis on usability testing is well recognized because such tests help build confidence in the application's functionality. The guide written for React provides no reassurance based solely on best practices and forces the use of React Testing Library for testing instead.
How-to (React + React Testing Library + Jest):
// LoginButton.jsx
export function LoginButton({ onLogin }) {
return <button onClick={onLogin}>Log in</button>;
}
// LoginButton.test.jsx
import { render, screen, fireEvent } from "@testing-library/react";
import { LoginButton } from "./LoginButton";
test("calls onLogin when clicked", () => {
const onLogin = jest.fn();
render(<LoginButton onLogin={onLogin} />);
fireEvent.click(screen.getByText("Log in"));
expect(onLogin).toHaveBeenCalledTimes(1);
});Integration Tests: Verify Contracts Between Modules and Services
Usually, AI-generated code fails to pass the integration testing. This is because the AI model was imprecise in defining the contract, such as response structures, status codes, operation of authentication middleware, database connection procedures, and similar details.
When it comes to Node.js applications, many developers would opt for Supertest, which is an extension and support of SuperAgent, which provides HTTP assertion support for testing Node HTTP servers.
How-to (Express + Supertest):
import request from "supertest";
import app from "../app";
test("GET /health returns ok", async () => {
await request(app)
.get("/health")
.expect(200);
});E2E Tests: Make the Browser Prove the Feature Works
E2E tests are capable of uncovering defects when described types do not: navigation, live view, data storage, HTTP cookies, access restrictions, and, what is colloquially known as, “working when a user just does whatever.”
Cypress strives to be more than just a solution for end-to-end testing. Its documentation contains examples that help you write an end-to-end test from scratch. In contrast, action + assertion chains are more important from the perspective of the playwright, with additional functions for waiting inside elements, which greatly alleviates the necessity to use sleep states only for checks.
How-to (install Cypress):
npm install cypress --save-dev
npx cypress openThose commands are straight from Cypress installation docs.
How-to (Playwright E2E test snippet):
import { test, expect } from "@playwright/test";
test("login redirects to dashboard", async ({ page }) => {
await page.goto("/login");
await page.getByLabel("Email").fill("[email protected]");
await page.getByLabel("Password").fill("password123");
await page.getByRole("button", { name: "Log in" }).click();
await expect(page).toHaveURL(/dashboard/);
});Playwright documents this general “do actions, then assert the state” structure, and notes its auto-waiting behavior.
Security Testing: Treat “Generated Code” as a Risk Multiplier
Use dependency scanning and static analysis to improve the security of web applications.
When it comes to reviewing the endpoints and UI flows (auth, access control, injection, etc.) that are generated by the AI model, one may refer to the list of the OWASP Top 10 guidelines as a checklist.
Dependency Scanning (Snyk + npm audit):
Snyk test checks for open-source vulnerabilities and license issues.
npm audit exits non-zero on found vulnerabilities (ideal for CI gates).
How-to (Snyk):
Copy
snyk testHow-to (Snyk Code SAST):
Copy
snyk code testSnyk code test, called Snyk, performs Static Application Security Testing against the source code.
Although not required, it is advised to activate the CodeQL extension in GitHub Actions in order to conduct code scanning.
Performance Testing: “It Works” Is Not “It Survives Traffic”
AI-scripted functionalities are also known to cause performance detriment, either through the introduction of additional DB access calls or multiple N+1 queries; thus, it is advisable to smoke load test critical routes. k6 has proper documentation on how to write and execute such tests.
How-to (k6 smoke test):
import http from "k6/http";
import { check, sleep } from "k6";
export default function () {
const res = http.get("https://example.com/api/health");
check(res, { "status is 200": (r) => r.status === 200 });
sleep(1);
}Both k6 and Artillery are equipped with documentation on how to formulate HTTP requests and set up tests. Artillery can be installed either through npm or npx to execute tests.
Snapshot and Golden Master Testing: Use Sparingly, Review Aggressively
Creating snapshot tests is useful for monitoring changes in different versions of the app that should not be changed quietly (such as HTML email templates, stable fragments of the user interface, etc.). The Jest snapshot file requires verification of snapshot outputs alongside code modifications, which are then reviewed to prevent misunderstandings; Jest compares future runs with past snapshots and reports errors if discrepancies are found.
How-to (Jest snapshot):
import renderer from "react-test-renderer";
import { Banner } from "./Banner";
test("banner matches snapshot", () => {
const tree = renderer.create(<Banner />).toJSON();
expect(tree).toMatchSnapshot();
});The Ultimate Golden Master Hack for LLM Code
Code Review: The Essential Human Layer
Among other things, code review is an important step, as it allows for the asking of questions such as “Is this approach valid?” or even “Is this in line with the architecture?” The Secure Software Development Framework (SSDF) by the National Institute of Standards and Technology (NIST) exists because most Software Development Life Cycles (SDLCs) tend to ignore security at the source.
It promotes the incorporation of safe behavioural patterns into the existing cycle of activities. Such mechanisms as code review and other process controls remain significant as they are aimed at human beings and not machines.
For AI-generated PRs, code review should explicitly check:
- authz/authn boundaries
- input validation and encoding
- error handling and logging
- dependency choices
- “magic” regexes and crypto (danger zone)
Testing the Prompt and Validating LLM Outputs
A great number of teams skip over the small fact that the prompt is itself a code construct. Since the wording of the prompt can generate particular behavior, it is imperative that it is put to the test, as is done for APIs.
Workflow:
- Define prompt contract: Templates with stack, versions, constraints, and testing requirements.
- Request tests: Generate and run unit/integration tests before trusting features.
- Create regression suite: Store prompts, invariants, and run tests/scripts.
- Use checklists: Keep prompts as review checklists for each PR.
Before merging AI-generated code, require:
- lint/type checks pass (ESLint)
- unit + integration pass (Jest + Supertest patterns)
- at least one E2E flow passes (Cypress/Playwright)
- dependency scan passes or is triaged (Snyk / npm audit)
Tool Comparisons and When to Use What
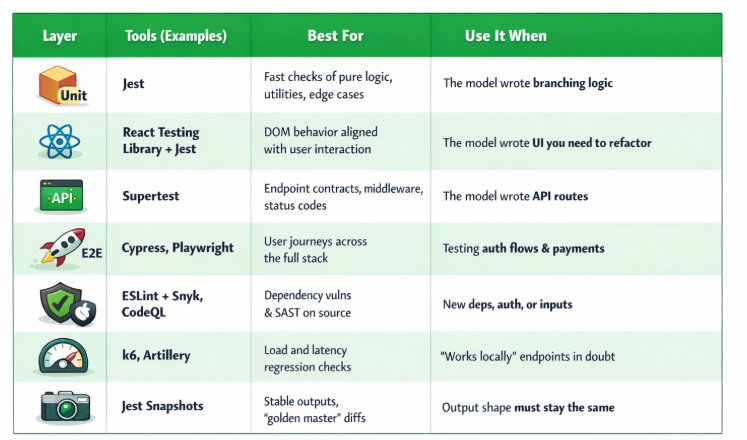
No tool here is used inappropriately since Jest is designed for unit testing; React Testing Library, for testing those aspects of unit that show nuances to end users; Supertest – for HTTP server testing; Cypress alongside Playwright – for E2E testing; Snyk and SAST are used for scanning dependencies; GitHub CodeQL along with k6 and Artillery are used for scanning and testing codes as well as for load testing, respectively.
Commonly Used Commands
- ESLint:
npm init @eslint/config@latest then npx eslint src/ - Cypress:
npm install cypress --save-dev then npx cypress open - Snyk Dependency Scan: snyk test
- Snyk SAST: snyk code test
- npm Dependency Audit: npm audit
- k6: Write a script, then run with k6
- Artillery:
npm install -g artillery@latest (or npx artillery@latest), then artillery run my-test.yml
CI automation with test gates
The main purpose of the layers is to verify that they are genuine and feasible. GitHub Actions are automation scripts written in YAML syntax that can contain steps and jobs. According to the instructions provided in the official guide for Node.js Actions by GitHub, the following three standard procedures must be followed: installing Node, injecting dependencies into the environment, and testing.
Minimal GitHub Actions workflow example
name: CI
on:
pull_request:
push:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 22
cache: npm
- run: npm ci
- name: Lint
run: npx eslint .
- name: Unit + integration
run: npm test
- name: Dependency scan
run: |
npm audit
snyk test
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}
- name: SAST scan (optional but strong)
run: snyk code test
env:
SNYK_TOKEN: ${{ secrets.SNYK_TOKEN }}The actions/setup-node install and cache the Node in workflows. The playwright furnishes CI hints and assists in creating GitHub Actions workflows. GitHub documentation goes into depth on how CodeQL operates within GitHub actions workflow.
Before You Merge: Checklist, Pitfalls, and Mitigations
Pre-merge checklist for AI-generated web code
- Lint passes: Ensure lint passes and security lint is reviewed.
- Unit tests: Cover model assumptions (edge cases, input shapes).
- Integration tests: Confirm API contracts (status codes, auth, schema).
- E2E tests: Cover at least one critical user journey (e.g., login).
- Dependency scan: Run Snyk or npm audit and triage findings.
- SAST: Run Snyk code test or CodeQL for risky changes.
- Snapshot diffs: Review snapshot diffs like code; no auto-updates.
- CI checks: Require CI checks before merge; no exceptions.
Common Pitfalls (and How to Avoid Them)
- Passing tests: Test real user behavior, as React Testing Library suggests.
- Over-mocking: Avoid mocking everything—use a real test DB.
- Flaky E2E tests: Use Playwright to reduce timing issues.
- Snapshot testing: Don’t auto-update snapshots; review them.
- Skipping security scanning: Include security checks for all PRs, big or small.
Closing thought
The most important responsibility assigned to an AI for web generation is to ensure that validation becomes unobtrusive and a straightforward activity. Individuals tend to trust processes that are uniform and happen repeatedly.
Although LLMs streamline the process of generating the coding, it is the exhaustive examination that makes the process of its correctness more efficient. Those who achieve the desired outcomes are the ones who do all the above: set up CI-enforced gates, apply testing at different levels, and treat prompts as part of the design.
Opinions expressed by DZone contributors are their own.
Comments