Get Started With GRAKN.AI
GRAKN.AI is a deductive database in the form of a knowledge graph that uses machine reasoning to simplify data processing challenges for AI applications.
Join the DZone community and get the full member experience.
Join For FreeIn this introductory article, I will show how to get up and running with GRAKN.AI. Before we start, though, let’s quickly answer one question...
What Is GRAKN.AI?
GRAKN.AI is a database for AI. It is a deductive database in the form of a knowledge graph that uses machine reasoning to simplify data processing challenges for AI applications. GRAKN.AI is composed of two parts: Grakn (the storage) and Graql (the language).
- Grakn is a database in the form of a knowledge graph that uses an intuitive ontology to model extremely complex datasets. It stores data in a way that allows machines to understand the meaning of information in the complete context of their relationships. Consequently, Grakn allows computers to process complex information more intelligently with less human intervention.
- Graql is a declarative, knowledge-oriented graph query language that uses machine reasoning for retrieving explicitly stored and implicitly derived knowledge from Grakn.
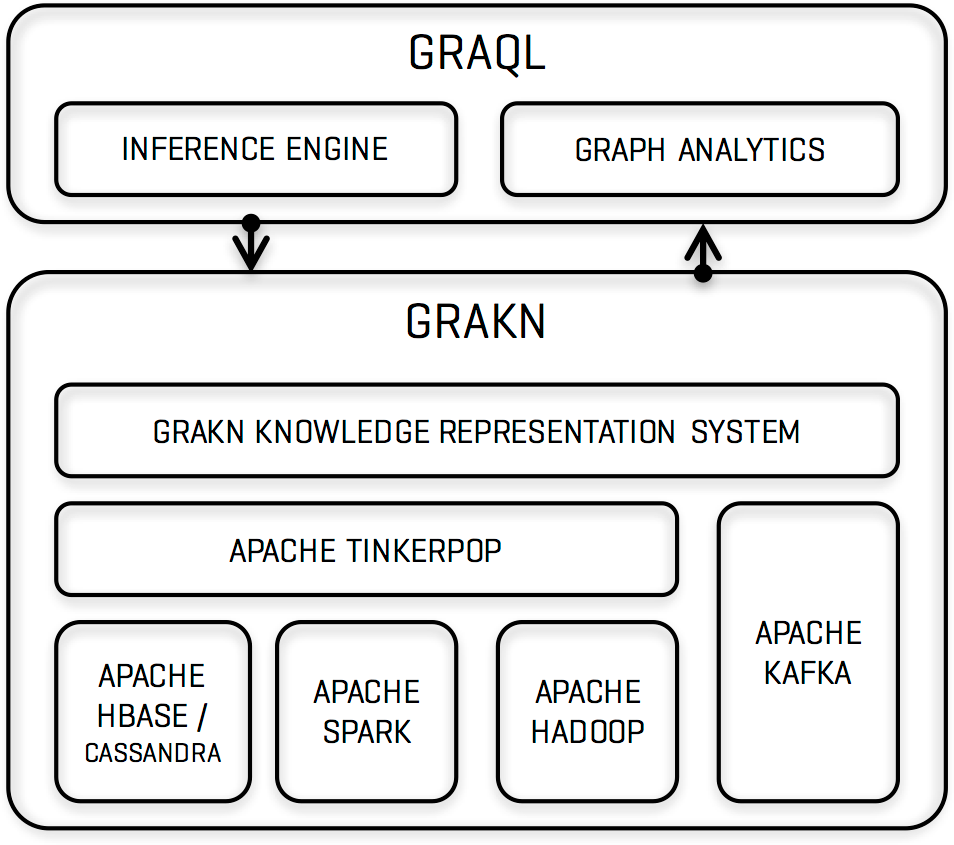
You can find out more on our website, but, for now, let’s assume you want to try it out. This article explains how to get set up, as you can discover a lot about Grakn just from trying it out.
Download GRAKN.AI
GRAKN.AI is supported on Mac OS X or Linux. We do expect to add Windows support in due course. The first thing you need to do is download and install it.
For more information on how to download older versions of GRAKN.AI, compile from source code, or import the Grakn Java API library as a development dependency, please visit our Downloads page.
Prerequisites
GRAKN.AI requires Java 8 (Standard Edition) with the $JAVA_HOME set accordingly. If you don’t already have this installed, you can find it here. If you intend to build Grakn from its source code or develop on top of it, you will also need Maven 3.
Unzip the download into your preferred location and run the following in the terminal to start Grakn:
cd [your Grakn install directory]
./bin/grakn.sh startThis will start:
- An instance of Cassandra, which serves as the supported backend for Grakn.
- Grakn Engine, which is an HTTP server providing batch loading, monitoring and the browser dashboard.
- Apache Kafka.
- Apache Zookeeper.
Grakn Engine is configured by default to use port 4567, but this can be changed, as can settings for Kafka and Zookeeper, in the grakn-engine.properties file found within the /conf directory of the installation.
Useful Commands
To start Grakn, run grakn.sh start.
To stop Grakn, run grakn.sh stop.
To remove all graphs from Grakn, run grakn.sh clean
Test the Graql Shell
To test that the installation is working correctly, we will load a simple ontology and some data from a file and test it in the Graql shell and Grakn Visualiser. The example we are using is part of our genealogy-graph project. You can find out much more from our documentation in which we use the dataset extensively.
The file we will use, basic-genealogy.gql, will be included in the /examples folder of the Grakn installation zip from the release 0.11.0 onwards, and otherwise, you are welcome to clone it from the Grakn repo on GitHub. In the code below, we assume that the file is located in the /examples folder.
From the terminal, type in the following to load the example graph. This starts the Graql shell in non-interactive mode, loading the specified file and exiting after the load is complete.
./bin/graql.sh -f ./examples/basic-genealogy.gqlThen type the following to start the Graql shell in its interactive (REPL) mode, type:
./bin/graql.shThe Graql shell starts and you see a >>> prompt. We will type in a query to check that everything is working.
match $x isa person, has identifier $n;You should see a printout of a number of lines of text, each of which includes a name, such as “William Sanford Titus” or “Elizabeth Niesz.”
If you see the above output then congratulations! You have set up Grakn. If you are having trouble with the setup, please check our FAQ page, and if you have any questions, please ask them on our discussion forum, on Stack Overflow, or on our Slack channel.
Test the Visualizer
The Grakn visualizer provides a graphical tool to inspect and query your graph data. You can open the visualizer by navigating to localhost:4567 in your web browser. The visualizer allows you to make queries or simply browse the knowledge ontology within the graph. The screenshot below shows a basic query (match $x isa person;) typed into the form at the top of the main pane, and visualized by pressing Submit:
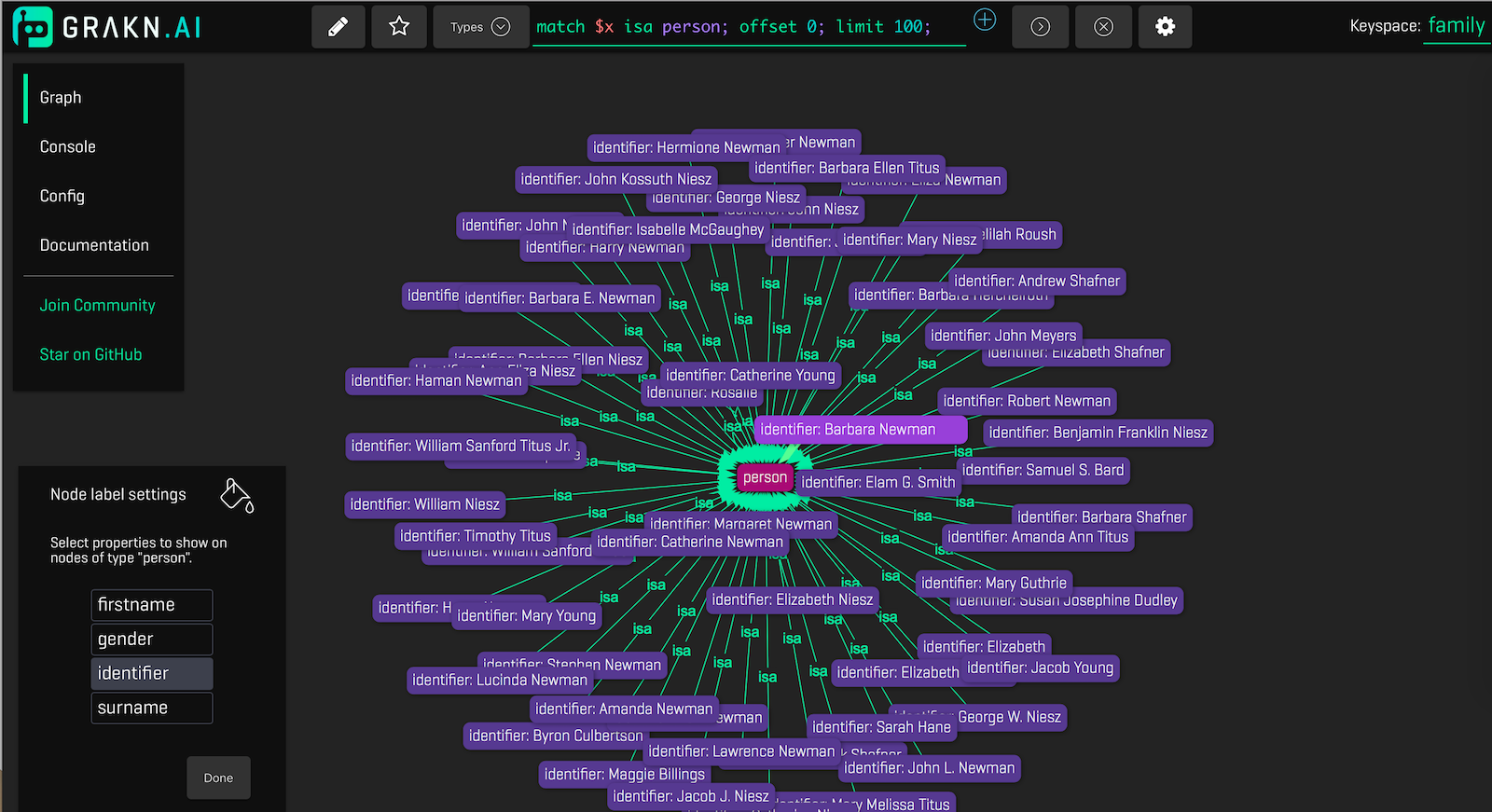
The help tab on the main pane shows a set of key combinations that you can use to further drill into the data. You can zoom the display in and out, and move the nodes around for better visibility. Please see our Grakn visualizer documentation for further details.
The Ontology
You can find out much more about the Grakn ontology in our documentation about the Grakn knowledge model, which states that:
The ontology is a formal specification of all the relevant concepts and their meaningful associations in a given application domain. It allows objects and relationships to be categorised into distinct types, and for generic properties about those types to be expressed.
You can think of the ontology as a schema that describes items of data and defines how they relate to one another. You need to have a basic understanding to make useful queries on the data, so let’s review the chunks of it that are important for this demonstration:
insert
# Entities
person sub entity
plays-role parent
plays-role child
plays-role spouse1
plays-role spouse2
has-resource identifier
has-resource firstname
has-resource surname
has-resource middlename
has-resource picture
has-resource age
has-resource birth-date
has-resource death-date
has-resource gender;
# Resources
identifier sub resource datatype string;
firstname sub resource datatype string;
surname sub resource datatype string;
middlename sub resource datatype string;
picture sub resource datatype string;
age sub resource datatype long;
birth-date sub resource datatype string;
death-date sub resource datatype string;
gender sub resource datatype string;
# Roles and Relations
marriage sub relation
has-role spouse1
has-role spouse2
has-resource picture;
spouse1 sub role;
spouse2 sub role;
parentship sub relation
has-role parent
has-role child;
parent sub role;
child sub role;There are a number of things we can say about ontology shown above:
- There is one entity,
person, which represents a person in the family whose genealogy data we are studying. - The
personentity has a number of resources to describe aspects of them, such as their name, age, dates of birth and death, gender, and a URL to a picture of them (if one exists). Those resources are all expressed as strings, except for the age, which is of datatype long. - There are two relations that a
personcan participate in:marriageandparentship. - The person can play different roles in those relations, as a spouse (
spouse1orspouse2— we aren’t assigning them by gender to be husband or wife) and as aparentorchild(again, we are not assigning a gender such as a mother or father at this point). - The
marriagerelation has a resource, which is a URL to a wedding picture (if one exists).
The Data
We will not reproduce all the data here, but here is a snippet of some of the data that you added to the graph when you loaded the basic-genealogy.gql file. Each statement is adding either a person, a parentship, or a marriageto the graph:
$57472 isa person has firstname "Mary" has identifier "Mary Guthrie" has surname "Guthrie" has gender "female";
$86144 has surname "Dudley" isa person has identifier "Susan Josephine Dudley" has gender "female" has firstname "Susan" has middlename "Josephine";
...
$8304 (parent: $57472, child: $41324624) isa parentship;
$24816 (parent: $81976, child: $41096) isa parentship;
...
$122884216 (spouse2: $57472, spouse1: $41406488) isa marriage;
$40972456 (spouse2: $40964120, spouse1: $8248) isa marriage;
...Don’t worry about the numbers such as $57472. These are variables in Graql and happen to have randomly assigned numbers to make them unique.
Querying the Graph
Let’s make some queries. You can do this in the Graql shell or in the visualiser. First, to find all the people who are married, and list their names:
match (spouse1: $x, spouse2: $y) isa marriage;
$x has identifier $xi; $y has identifier $yi;List parent-child relations with the names of each person:
match (parent: $p, child: $c) isa parentship;
$p has identifier $pi; $c has identifier $ci;Find all the people who are named Elizabeth:
match $x isa person, has identifier $y; $y value contains "Elizabeth";Querying the graph is more fully described in the Graql documentation.
Using Inference
We will move on to discuss the use of GRAKN.AI to infer new information about a dataset. In the ontology, we have dealt only with a person, not a man or woman, and the parentship relations were simply between parentand child roles. We did not directly add information about the nature of the parent and child in each relation — they could be father and son, father and daughter, mother and son or mother and daughter.
However, the person entity does have a gender resource, and we can use Grakn to infer more information about each relationship by using that property. The ontology accommodates the more specific roles of mother, father, daughter and son:
person
plays-role son
plays-role daughter
plays-role mother
plays-role father
parentship sub relation
has-role mother
has-role father
has-role son
has-role daughter;
mother sub parent;
father sub parent;
son sub child;
daughter sub child;Note: You don’t need to reload the basic-genealogy.gql file into Grakn pick up these extra roles. We simply didn’t show this part in our earlier discussion of the ontology, to keep things as simple as possible. Also included in basic-genealogy.gql is a set of Graql rules to instruct Grakn’s reasoner on how to label each parentship relation:
$genderizeParentships1 isa inference-rule
lhs
{(parent: $p, child: $c) isa parentship;
$p has gender "male";
$c has gender "male";
}
rhs
{(father: $p, son: $c) isa parentship;};
$genderizeParentships2 isa inference-rule
lhs
{(parent: $p, child: $c) isa parentship;
$p has gender "male";
$c has gender "female";
}
rhs
{(father: $p, daughter: $c) isa parentship;};
$genderizeParentships3 isa inference-rule
lhs
{(parent: $p, child: $c) isa parentship;
$p has gender "female";
$c has gender "male";
}
rhs
{(mother: $p, son: $c) isa parentship;};
$genderizeParentships4 isa inference-rule
lhs
{(parent: $p, child: $c) isa parentship;
$p has gender "female";
$c has gender "female";
}
rhs
{(mother: $p, daughter: $c) isa parentship;};If you’re unfamiliar with the syntax of rules, don’t worry too much about it just now. It is sufficient to know that for each parentship relation, Graql checks whether the pattern in the first block (left-hand side or lhs) can be verified and, if it can, infers the statement in the second block (right-hand side or rhs) to be true, so inserts a relation between gendered parents and children.
Let’s test it out!
First, try making a match query to find parentship relations between fathers and sons in the Graql shell:
match (father: $p, son: $c) isa parentship;
$p has identifier $n1; $c has identifier $n2;Did you get any results? Probably not, because reasoning is not enabled by default at present, although as Grakn develops, we expect that to change. If you didn’t see any results, you need to exit the Graql shell and restart it, passing -n and -m flags to switch on reasoning (see our documentation for more information about flags supported by the Graql shell).
./bin/graql.sh -n -mTry the query again:
match (father: $p, son: $c) isa parentship;
$p has identifier $n1; $c has identifier $n2;There may be a pause, and then you should see a stream of results as Grakn infers the parentships between male parent and child entities. It is, in effect, building new information about the family which was not explicit in the dataset.
You may want to take a look at the results of this query in the Grakn visualizer and, as for the shell, you will need to activate inference before you see any results. Browse to the visualiser at localhost:4567 and open the Config settings on the left-hand side of the screen. When the page opens you will see the Activate Inference checkbox. Check it and try submitting the query above or a variation of it for mothers and sons, fathers and daughters, etc. Or, you can even go one step further and find out fathers who have the same name as their sons:
match (father: $p, son: $c) isa parentship;
$p has firstname $n; $c has firstname $n;If you want to find out more about the Graql reasoner, we have a detailed example that uses a slightly different version of the genealogy dataset. An additional discussion on the same topic can be found in our “Family Matters” blog post.
Data Migration
In this example, we loaded data from basic-genealogy.gql directly into a graph. However, data isn’t often conveniently stored in GQL files and, indeed, this data was originally in CSV format. Our CSV migration example explains in detail the steps we took to migrate the CSV data into Grakn.
Migrating data in formats such as CSV, SQL, OWL, and JSON into Grakn is a key use case. More information about each of these can be found in our migration documentation.
Where Next?
This post was a very high-level overview of some of the key use cases for Grakn, and has hardly touched the surface or gone into detail. The rest of our developer documentation and examples are more in-depth and should answer any questions that you may have, but if you need extra information, please get in touch.
A good place to start is to explore our additional example code and the documentation for:
- The Grakn knowledge model.
- Graql, including reasoning.
- Migration.
- Analytics.
- Grakn’s Java APIs.
Published at DZone with permission of Jo Stichbury. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments