Getting Started With OpenEBS and Cloud-Native Distributed SQL
In this article, take a look at how to get started with OpenEBS and cloud-native distributed SQL.
Join the DZone community and get the full member experience.
Join For FreeOpenEBS is a CNCF project that provides cloud-native, open source container attached storage (CAS). OpenEBS delivers persistent block storage and other capabilities such as integrated back-up, management of local and cloud disks, and more. For enterprise cloud-native applications, OpenEBS provides storage functionality that is idiomatic with cloud-native development environments, with granular storage policies and isolation that enable cloud developers and architects to optimize storage for specific workloads.
Because YugabyteDB is a cloud-native, distributed SQL database that runs in Kubernetes environments, it can interoperate with OpenEBS and many other CNCF projects.
What’s YugabyteDB? It is an Open Source, and high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. Yugabyte’s SQL API (YSQL) is PostgreSQL wire compatible.
Why OpenEBS and YugabyteDB?
YugabyteDB is deployed as a StatefulSet on Kubernetes and requires persistent storage. OpenEBS can be used for backing YugabyteDB local disks, allowing the provisioning of large-scale persistent volumes. Here are a few of the advantages of using OpenEBS in conjunction with a YugabyteDB database cluster:
- There’s no need to manage the local disks as OpenEBS manages them
- OpenEBS and YugabyteDB can provision large size persistent volumes
- With OpenEBS persistent volumes, capacity can be thin provisioned, and disks can be added to OpenEBS on the fly without disruption of service. When this capability is combined with YugabyteDB, which already supports multi-TB data density per node, this can prove to be massive cost savings on storage.
- Both OpenEBS and YugabyteDB support multi-cloud deployments helping organizations avoid cloud lock-in
- Both OpenEBS and YugabyteDB integrate with another CNCF project, Prometheus. This makes it easy to monitor both storage and the database from a single system
Additionally, OpenEBS can do synchronous replication inside a geographic region. In a scenario where YugabyteDB is deployed across regions, and a node in any one region fails, YugaByteDB would have to rebuild this node with data from another region. This would incur cross-region traffic, which is more expensive and lower in performance.
But, with OpenEBS, this rebuilding of a node can be done seamlessly because OpenEBS is replicating locally inside the region. This means YugabyteDB does not end up having to copy data from another region, which ends up being less expensive and higher in performance. In this deployment setup, only if the entire region failed, YugabyteDB would need to do a cross-region node rebuild.
Additional detailed descriptions of OpenEBS enabled use cases can be found here.
Prerequisites
Below is the environment which we’ll use to run a YugabyteDB cluster on top of a Google Kubernetes cluster integrated with OpenEBS CAS.
- YugabyteDB — Version 2.0.10
- OpenEBS — Version 1.6.
- A Google Cloud Platform account
- A MayaData account
MayaData is an enterprise-grade OpenEBS platform that makes it easier to run stateful applications on Kubernetes by helping get your workloads provisioned, backed-up, monitored, logged, managed, tested, and even migrated across clusters and clouds.
Setting Up a Kubernetes Cluster on Google Cloud Platform
To deploy YugabyteDB on the Google Cloud Platform (GCP), we first have to set up a cluster using Ubuntu as our base node image. Please note that GKE Container-Optimized OS does not come with an iSCSI client pre-installed and does not allow the installation of an iSCSI client. Therefore, OpenEBS does not work on Kubernetes clusters, which are running the GKE Container-Optimized OS version of the image on the worker nodes.
Go to Kubernetes Engine> Clusters > Create Cluster.
Create a Standard cluster using the default options.
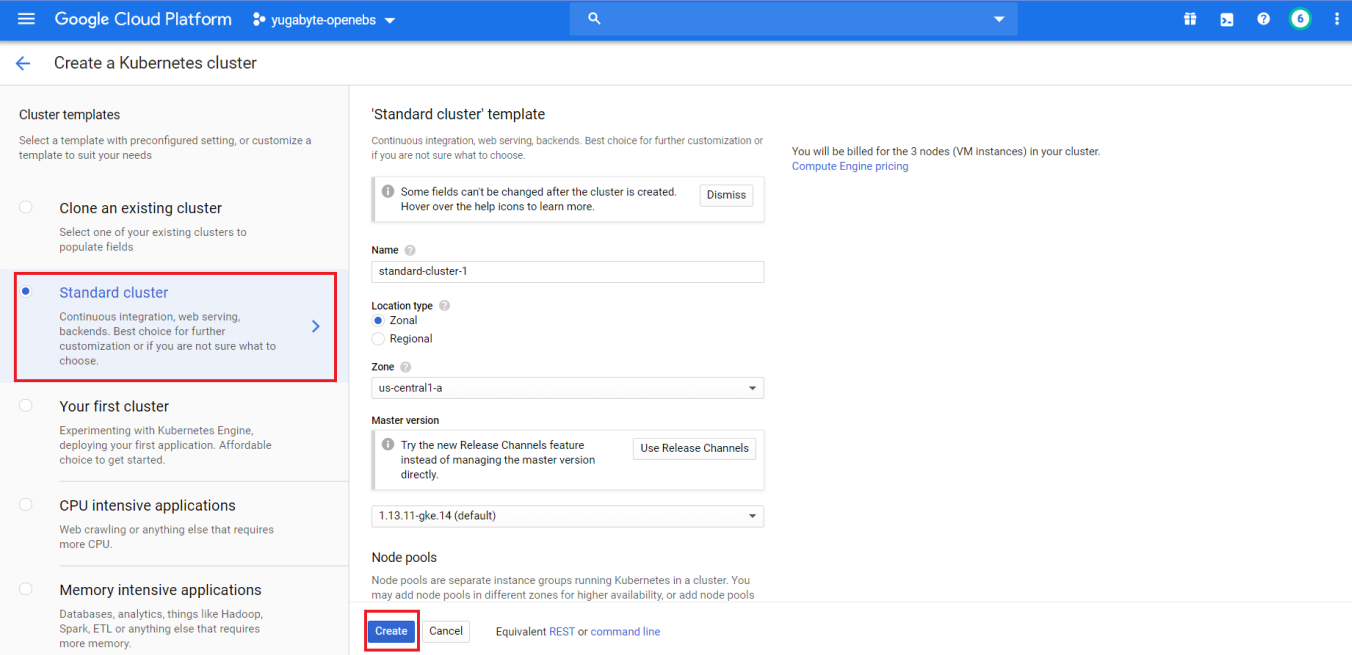
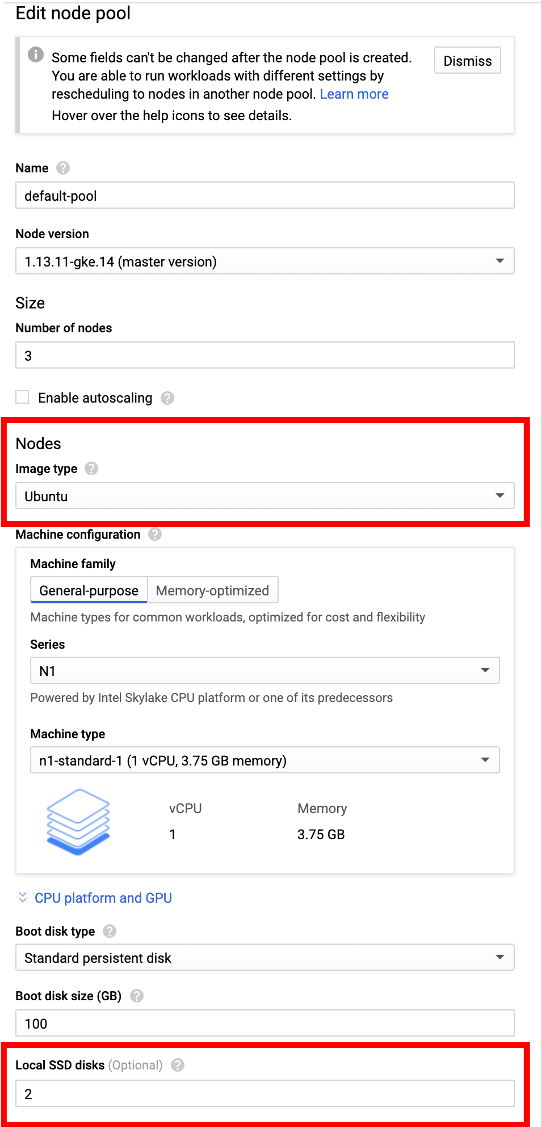
Make sure to select the More options button under Node pools to specify the Ubuntu base image and 2 local SSD disks.
Connect to the Google Cloud Shell and verify that the nodes are set up and running by using the command:
> gcloud container clusters list

Installing OpenEBS on the GKE Cluster
To install OpenEBS on the GKE cluster, complete the steps found here.
A summary of the required steps include:
- Verify if iSCSI client is running
- Unmount local persistent disks to use for your storage pool
- Set Kubernetes admin context and RBAC
- Installation using helm chart (or), kubectl yaml spec file
Currently, GKE’s Ubuntu instances do not come with the iSCSI client service started. You can check this by logging into each node via SSH and running:
xxxxxxxxxx
systemctl status iscsid
If the iSCSI service status is showing as inactive, then you may have to enable and start the iscsid service using the following command:
xxxxxxxxxx
sudo systemctl enable iscsid && sudo systemctl start iscsid
While logged into your Kubernetes node, ensure that any local disks are not mounted or formatted. For example, on a GKE node:
xxxxxxxxxx
sudo ls /mnt/disks
ssd0 ssd1
sudo umount /mnt/disks/ssd0
sudo umount /mnt/disks/ssd1
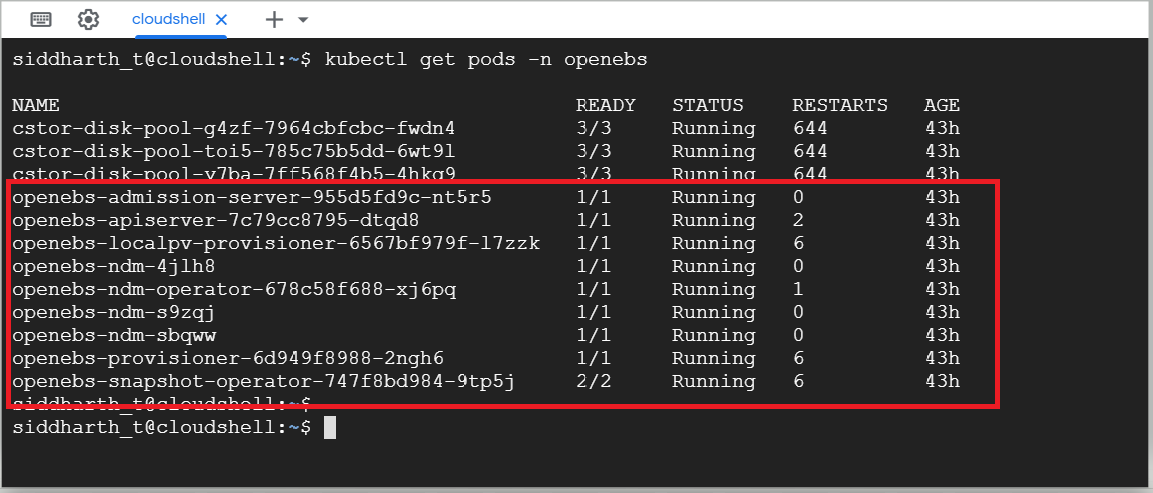
Once the above steps are complete, you can verify that OpenEBS is installed and running on the GKE cluster by running the command:
xxxxxxxxxx
> kubectl get pods -n openebs
Configure cStor Pool and Create Storage Class
After the OpenEBS installation, the cStor Pool has to be configured. If cStor Pool is not configured in your OpenEBS cluster, this can be done with the instructions here. First, identify your local block devices by running:
xxxxxxxxxx
kubectl get blockdevice -n openebs
NAME NODENAME SIZE CLAIMSTATE STATUS AGE
blockdevice-11a54a76e84dd32328e4de732b90cc70 gke-yb-ebs-demo-default-pool-e3222e18-hk09 402653184000 Unclaimed Active 4m
blockdevice-212662daececcdcd5976b5caeab4c950 gke-yb-ebs-demo-default-pool-e3222e18-hk09 402653184000 Unclaimed Active 4m
blockdevice-388b9664ca802b287fd14f5f31ab8f71 gke-yb-ebs-demo-default-pool-e3222e18-trqx 402653184000 Unclaimed Active 4m
Now create your storage pool using those specific block devices. For example:
xxxxxxxxxx
#Use the following YAML to create a cStor Storage Pool.
apiVersion: openebs.io/v1alpha1
kind: StoragePoolClaim
metadata:
name: cstor-disk-pool
annotations:
cas.openebs.io/config: |
- name: PoolResourceRequests
value: |-
memory: 2Gi
- name: PoolResourceLimits
value: |-
memory: 4Gi
spec:
name: cstor-disk-pool
type: disk
poolSpec:
poolType: striped
blockDevices:
blockDeviceList:
# Use the blockdevices that are available to your kubernetes nodes
# - blockdevice-11a54a76e84dd32328e4de732b90cc70
# - blockdevice-212662daececcdcd5976b5caeab4c950
# - blockdevice-388b9664ca802b287fd14f5f31ab8f71
---
You must also configure a StorageClass to provision a cStor volume on a given cStor pool. StorageClass is the interface through which most of the OpenEBS storage policies are defined. In this solution, we are using a StorageClass to consume the cStor Pool, which is created using external disks attached to the Nodes. Since YugabyteDB is a StatefulSet application, it requires only one replication at the storage level. So, the cStor volume replicaCount should be set to 1. For example:
xxxxxxxxxx
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-sc-rep1
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk-pool"
- name: ReplicaCount
value: "1"
provisioner: openebs.io/provisioner-iscsi
Installing YugabyteDB on the GKE Cluster Using Helm
The next step is to install YugabyteDB on the cluster. This can be done by completing the steps here.
A basic summary of the steps include:
- Verifying the prerequisites
- Creating the YugabyteDB cluster via Helm
To ensure you are using the latest Helm chart available from the Yugabyte repo, run:
xxxxxxxxxx
helm search repo yugabytedb/yugabyte
NAME CHART VERSION APP VERSION DESCRIPTION
yugabytedb/yugabyte 2.0.9 2.0.9.0-b13 YugaByte Database is the high-performance distr...
We will use the latest available version in our helm install command. Also, note that the default storageclass will need to be overridden by setting that option when installing the Helm chart. For example:
xxxxxxxxxx
helm install yb-demo yugabytedb/yugabyte --namespace yb-demo --version 2.0.9 --wait --set storage.master.storageClass=openebs-sc-rep1,storage.tserver.storageClass=openebs-sc-rep1
To verify that YugabyteDB has been successfully installed on GKE, use the following command:
xxxxxxxxxx
> helm status yb-demo
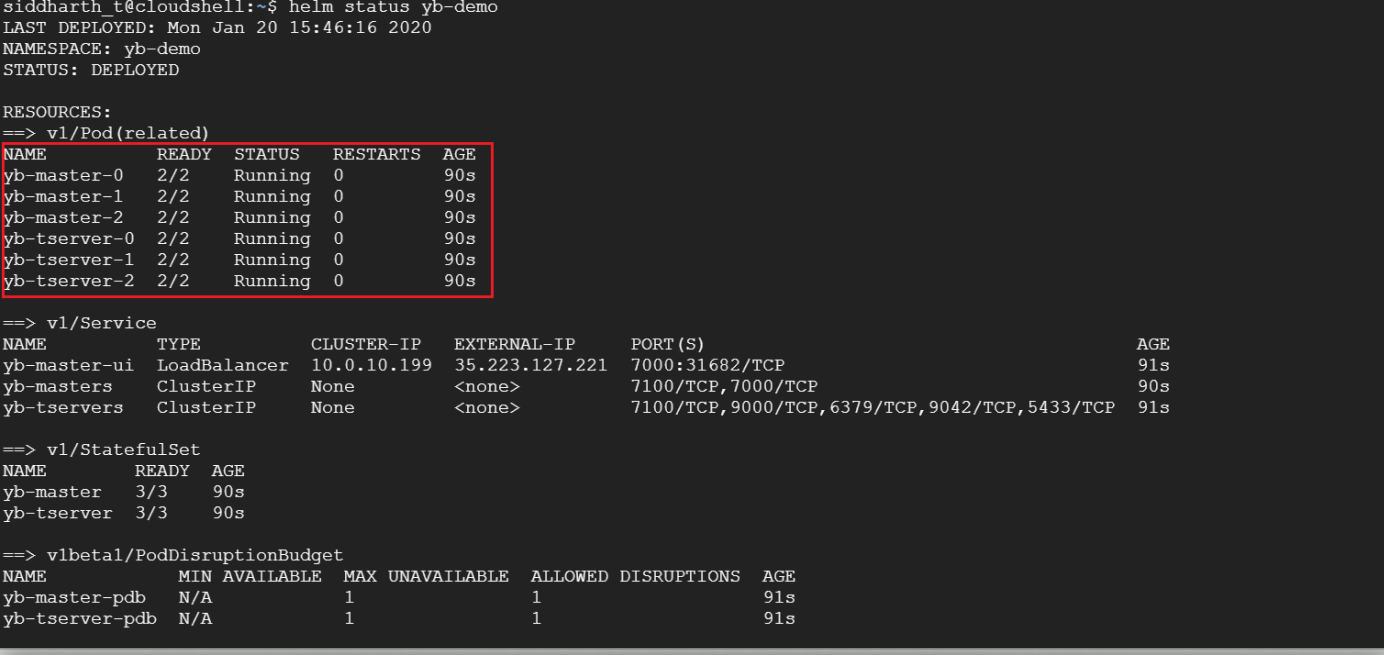
That’s it! You now have YugabyteDB running on GKE with OpenEBS storage. Stay tuned for an upcoming blog where we’ll look at how to connect a YugabyteDB + OpenEBS cluster to OpenEBS Director. This SaaS service makes managing and monitoring the cluster easier with Prometheus metrics, logs, and topology view of OpenEBS volumes via an intuitive UI.
Next Steps
- Learn more about OpenEBS by visiting the GitHub and official Docs pages.
- Learn more about YugabyteDB by visiting the GitHub and official Docs pages.
Published at DZone with permission of Jimmy Guerrero. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments