Golden Paths for AI Workloads - Standardizing Deployment, Observability, and Trust
Golden Paths enable scalable AI by standardizing deployment, observability, drift detection, and governance as built-in platform defaults.
Join the DZone community and get the full member experience.
Join For FreeAs AI workloads mature from experimental prototypes into business-critical systems, organizations are discovering a familiar problem: inconsistency at scale. Each team deploys models differently, observability varies widely, and operational maturity depends heavily on individual expertise.
This is where Golden Paths become essential.
Golden Paths are opinionated, reusable, and automated workflows that define the recommended way to build, deploy, and operate workloads. For AI systems, Golden Paths go beyond deployment and must embed observability, reliability, and governance as first-class concerns.
This article explains how to design and implement Golden Paths for AI workloads, the architectural principles behind them, and the advantages they deliver to both developers and platform teams.
Why AI Workloads Need Standardization
Traditional application workloads fail loudly: pods crash, services time out, alerts fire. AI workloads, however, often fail silently:
- Model accuracy degrades without infrastructure failures
- Input distributions change over time
- Performance depends on data characteristics, not just CPU or memory
- Governance and audit requirements extend beyond uptime
Without a standardized approach, teams independently solve the same problems, creating:
- Custom deployment patterns
- Inconsistent metrics
- Ad hoc drift detection
- Manual operational processes
Golden Paths address these challenges by codifying best practices into the platform itself.
What Is a Golden Path in the Context of AI?
A Golden Path is an opinionated, reusable pattern provided by the platform team that defines how workloads should be built, deployed, observed, and governed. For AI workloads, a Golden Path typically includes:
- Standardized model deployment
- Mandatory observability and metrics
- Model health and drift detection
- Built-in guardrails and governance hooks
Developers still retain flexibility — but they start from a foundation that is production-ready by design.
Consuming Golden Paths for AI Workloads
How Platform Teams Enable Golden Paths
Platform teams own the Golden Path lifecycle, not individual workloads. Their responsibilities include:
- Packaging Golden Paths as reusable modules or Helm charts
- Defining opinionated defaults for observability and drift detection
- Maintaining versioned releases
- Continuously improving the path based on operational feedback
How AI Teams Consume Golden Paths
From an AI developer’s perspective, the experience is simple:
- Select the AI Golden Path
- Configure a small set of parameters (model name, thresholds, resources)
- Deploy
Everything else — monitoring, dashboards, alerts, and governance — is inherited automatically. This reduces cognitive load, platform dependency knowledge, and operational risk. Developers stay focused on models and data, not infrastructure complexity.
Reference Architecture for an AI Golden Path
A practical Golden Path for AI workloads is usually structured in layers.
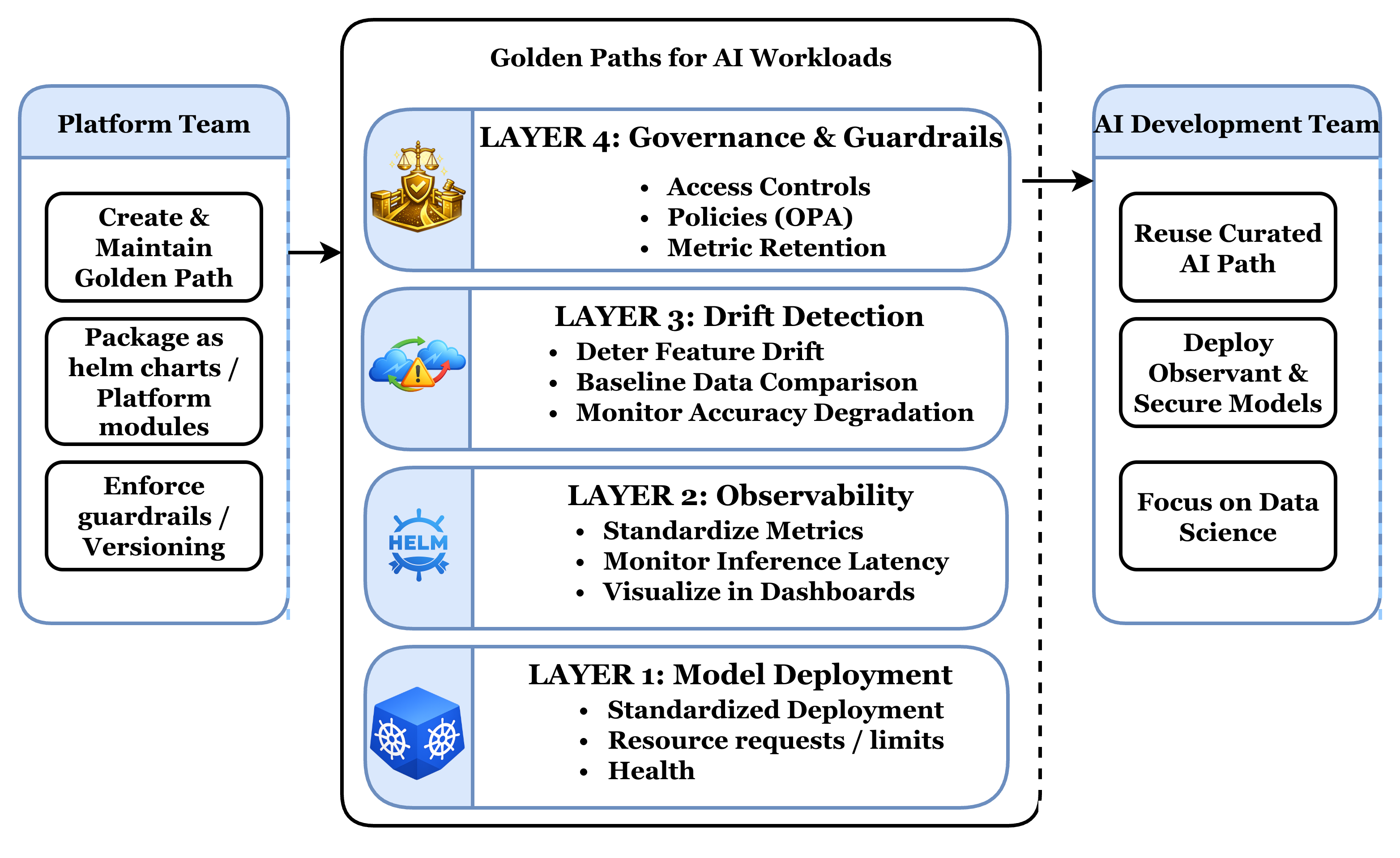
Layer 1: Model Deployment
This layer standardizes how models are packaged and deployed:
- Containerized inference services
- Health probes and readiness checks
- Resource requests and limits
- Deployment on Kubernetes
This ensures every model behaves like a well-formed cloud-native workload.
Layer 2: Model Observability
Observability must be opinionated and mandatory, not optional. Golden Paths typically include:
- Request and inference latency metrics
- Throughput and error rates
- Model-specific signals (e.g., token counts, confidence scores)
- Structured inference logs
This layer is commonly implemented using:
- Prometheus for metrics collection
- Grafana for dashboards and alerts
By default, every deployed model becomes observable the moment it goes live.
Layer 3: Drift Detection and Model Health
AI systems fail differently. A healthy service can still produce bad predictions. Golden Paths therefore integrate:
- Statistical drift detection
- Feature distribution monitoring
- Baseline vs. live data comparison
- Automated alerts on confidence or accuracy decay
This layer shifts AI operations from reactive firefighting to proactive model governance.
Layer 4: Governance and Guardrails by Design
This is the control-plane layer of the AI Golden Path and applies horizontally across all lower layers. Golden Paths typically include:
- Policy enforcement for deployments, metrics, and drift thresholds
- Access control and role separation (platform vs. AI teams)
- Metric retention and auditability requirements
- Compliance with organizational and regulatory standards
Governance should not be bolted on after deployment. By embedding guardrails directly into the Golden Path, organizations ensure that every AI workload is compliant by default — without slowing down teams.
Golden Path for AI Workloads: Hands-On Tutorial Overview
The repository demonstrates how platform engineering principles can be applied to model deployment, observability, drift detection, and governance — by default. Instructions to run this Golden Path are listed in the README.md file.
This Golden Path covers:
- Standardized Model Deployment – The
llm_apimodule defines a clean inference service boundary, separating API runtime (main.py) from model initialization (model_loader.py). This ensures consistent deployment behavior across environments and simplifies model upgrades without changing the service contract. - Built-In Model Observability – The
observabilitymodule instruments embedding and inference behavior, enabling AI-specific telemetry rather than relying solely on infrastructure metrics. This provides visibility into how models behave under real workloads. - Drift Detection as a First-Class Capability – The
drift_detectionmodule introduces reusable detectors that compare baseline and live inference signals, allowing teams to identify drift early — before it impacts downstream business decisions. - Golden Path Packaging with Helm – The Helm chart acts as the delivery mechanism for the Golden Path, wiring together deployment, observability, and drift detection with opinionated defaults. This enables repeatable installs and enforces consistency across teams.
- Governance and Guardrails by Design – Governance is applied implicitly through standardized configuration, controlled Helm values, and enforced integration of observability and drift checks — making compliance a built-in platform feature rather than an afterthought.
Platform Engineer Flow: Developing and Validating the Golden Path
From a platform engineering perspective, the Golden Path is developed and validated locally first before being promoted as a reusable, opinionated, installable artifact for AI teams. Running the inference service locally and validating drift behavior establishes confidence that the Golden Path is functionally complete before Kubernetes or Helm packaging is introduced.
Once local validation is complete, the platform engineer shifts focus to configuration and packaging. Helm values are updated to reflect platform-approved defaults, ensuring observability, drift detection, and deployment characteristics are consistently applied across environments. The container image is then built and published into a controlled environment, reinforcing reproducibility and versioned delivery.
The final step is end-to-end validation using Helm on a Kubernetes cluster. At this point, the Golden Path is ready for consumption, shifting ownership from platform engineering to AI development teams.
Platform engineer owns:
- Runbooks and automation
- Dockerfile correctness (exec-form CMD)
- Helm charts and templates
- CI build, push, and chart packaging
- Golden defaults and guardrails (resource requests/limits, probes, security context)
- Versioning and release notes
This is a sample implementation, and additional capabilities can be added as required.
Running the Golden Path Using Helm
Developers consume the AI Golden Path through a Helm command, abstracting away deployment complexity while enforcing platform standards. From the developer’s perspective, deploying an AI workload becomes a configuration exercise rather than an infrastructure task — demonstrating the core value of Golden Paths.
Developer owns:
- Prompts and test cases
- Environment overrides (values files)
- Selecting approved image tags or models from the platform catalog
Advantages of Golden Paths for AI Workloads
The advantages of Golden Paths for AI workloads include:
- Reduced cognitive load – AI engineers no longer design observability or reliability from scratch. The platform embeds best practices automatically.
- Consistent operational posture – Every model exposes the same health and performance signals, making fleet-level monitoring and comparison possible.
- Faster time to production – Teams move from notebook to production faster because the deployment path is already paved.
- Built-in governance – Auditability and policy enforcement are platform features — not afterthoughts.
- Scalable trust in AI systems – Standardized drift detection builds long-term confidence.
Conclusion
“AI systems do not fail loudly. Golden Paths ensure they don’t fail silently.”
By standardizing deployment, observability, and trust mechanisms, Golden Paths transform AI workloads from isolated experiments into reliable, governed, and scalable platform services.
Opinions expressed by DZone contributors are their own.
Comments