Google: Polling Like It's the 90s
A technical review of the live score feature in Google search results, delivered with some surprisingly old-school tech from the 90s.
Join the DZone community and get the full member experience.
Join For Free
Ably recently had the pleasure of delivering real-time scoring and commentary updates to fans of the Laver Cup tennis championship, on behalf of Tennis Australia, for the third year in a row. During the event, I saw that Google embeds live score updates within search results, which is pretty nifty. It seems this first appeared in results sometime in 2016 and received an update for the .

Being the curious engineer and realtime geek I am, I jumped into my browser dev console and started reverse-engineering the Google magic. Given the sheer scale of everything Google does, I was anticipating some off-the-wall micro-optimization work to squeeze out every last byte to minimize bandwidth and energy consumption. After all, Google has been pioneering the “light web” for years now, with initiatives like AMP, so I expected nothing less
So what did I find? Literally, a technology from the 90s.
In this blog post, I dive into why Google’s design choices are surprisingly bad in terms of bandwidth demand, energy consumption (battery life and unnecessary contribution to global warming), and ultimately sluggish user experience. At Google’s scale, I expected to see the use of common shared primitives such as an efficient streaming pub/sub API, or dogfooding of their own products.
Problem One: Overhead With a Bad Protocol Choice
Websockets, SSE (Server-sent Events) or XHR streaming are all good protocol choices for streaming updates in a browser. They provide a relatively low overhead transport to push updates as-they-happen from server to client. In addition, they are all supported in pretty much every browser used today.
Google strangely chose HTTP Polling. Don’t confuse this with HTTP long polling where HTTP requests are held open (stalled) until there is an update from the server. Google is literally dumb polling their servers every 10 seconds on the off chance there’s an update. This is about as blunt a tool as you can imagine.
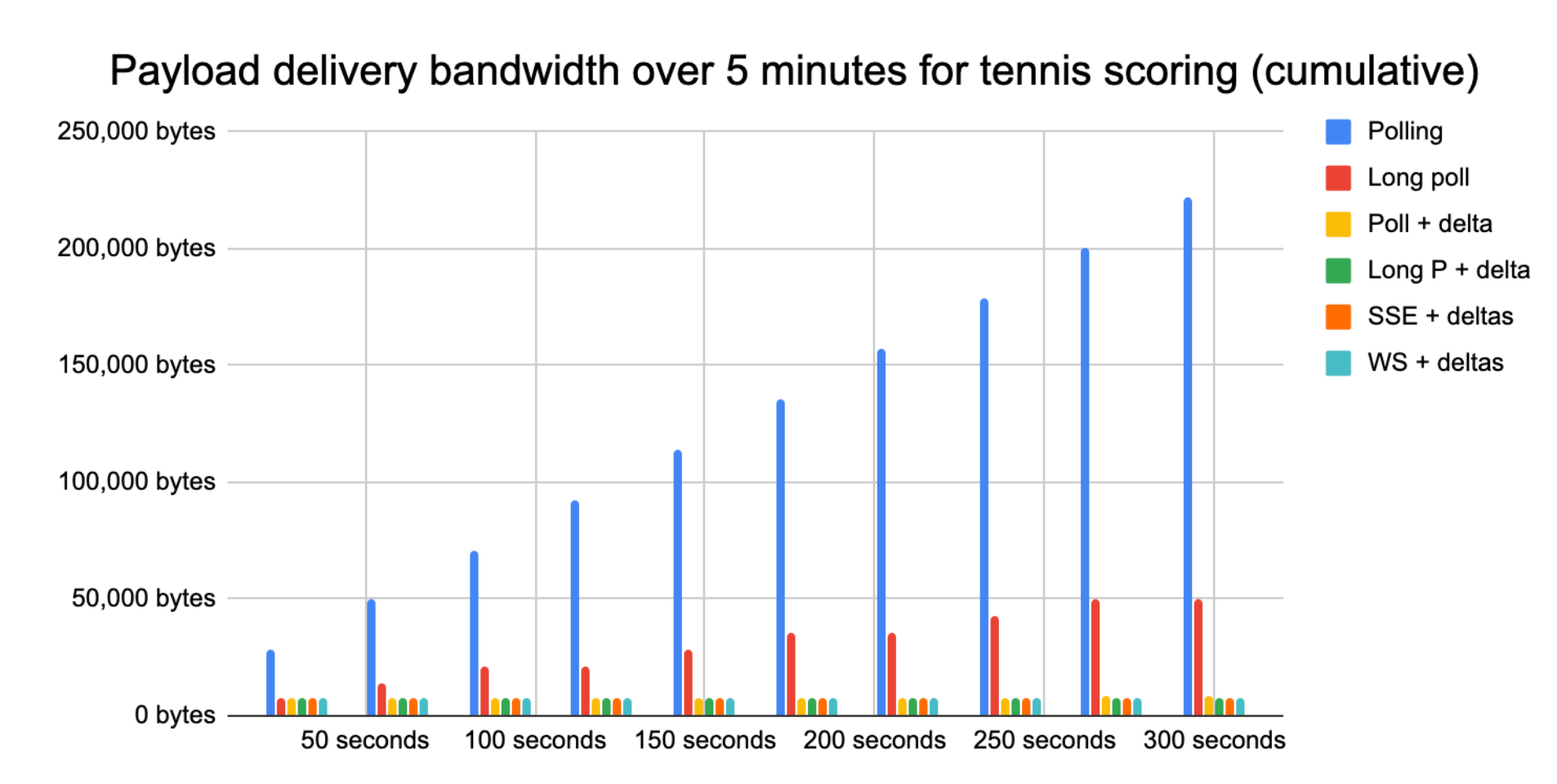
In the graph below, over a five-minute window, you can see the bandwidth overhead of Google’s polling approach versus other more suitable protocols.

Google’s HTTP polling is 80x less efficient than a raw WebSocket solution. Over a five minute window, the total overhead uncompressed is 68KiB vs 16KiB for long polling and a measly 852 bytes for Websockets. See the spreadsheet used to generate this graph and the raw Gist with the protocol overhead details.
Let’s look at what is responsible for an 80x increase in overhead with Google’s HTTP polling:
- A request is made every 10s because there is no persistent connection to push updates to the browser. As HTTP is stateless in this context, there is little room for optimization, and each request carries unnecessary requests and response overhead.
- The request overhead for the client is circa 1,650 bytes. Of this, almost half is cookie overhead, which is entirely unnecessary given these updates are not personalized in any way (the same scoring updates go to all users). See the example request.
- The response overhead is circa 600 bytes. See the example response.
Over 5 minutes, therefore, there are 30 requests made, each carrying 2.3KiB of overhead, resulting in 68KiB of total overhead.
Compare that with a long polling approach and the total overhead reduces to 16KiB, smaller by a factor of 4 (score updates come once every 45 seconds on average), and the user experience is better with significantly lower latencies as updates are pushed immediately.
Websockets and other protocols designed for streaming shift the dial much further. This is because the overhead needed per frame is a handful of bytes, and the only bandwidth overhead needed is in setting up the connection (upgrading from HTTP to Websockets). Over a five minute window, delivering on average 6.6 score updates, the overhead goes down to 846 bytes using 80x less bandwidth than polling. See an example WebSocket request.
Problem Two: High Variable Latencies and Diminished User Experience
If you look at the video capture of the live scoring above, you will notice that the progress indicator flashes every ten seconds, in response to a new polling request being sent to Google. Given scores update on average every 45 seconds, latency for score updates ranges from 200ms at best to around ten seconds at worst.
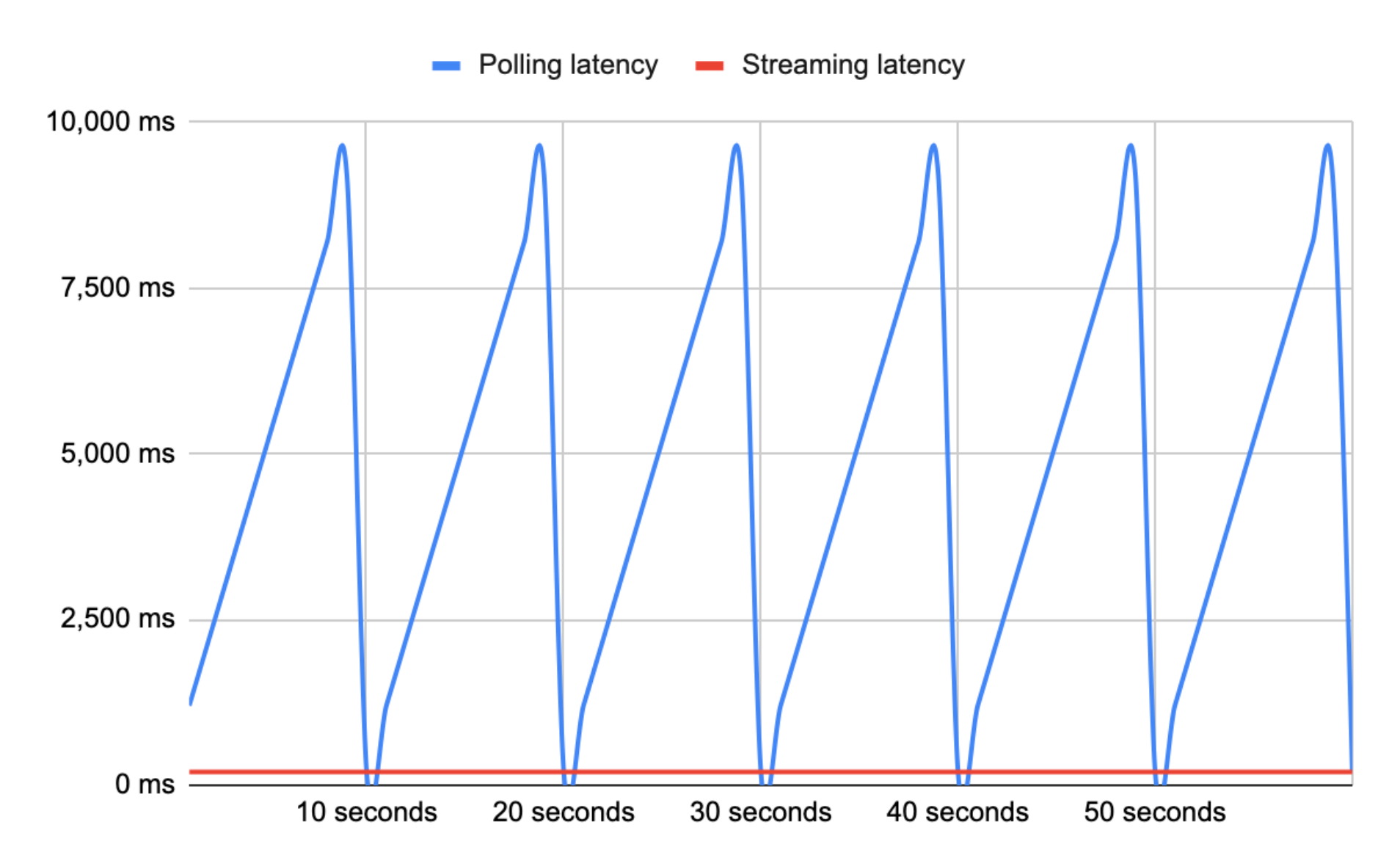
Websockets, SSE, XHR Streaming, and even long polling to a large degree, are all streaming transports and can thus offer a relatively fixed latency overhead of a few hundred milliseconds globally. The average latency for Google’s long polling solution is roughly 25x slower than any streaming transport that could have been used (5,000ms vs 200ms).
Problem Three: Inefficient Scoring Synchronization and Increased Bandwidth
In order to set up the scoreboard, Google requests the scoreboard state from Google’s servers over HTTP. Whilst there is a lot of unnecessary noise in this initial state object, at roughly 8KiB this is arguably acceptable as a one-off cost required to set up the state for the scoreboard.
Given that polling is used and a request is made every ten seconds, I expected to see Google use some form of data synchronization protocol to deliver only the changes for each request. Google has in the past invested a huge amount in synchronization protocols, such as Operational Transformation with Wave, so they are no stranger to solving the incredibly hard problems of synchronizing state.
Instead what I saw once again shocked me right back to the 90s. Every request, every ten seconds, sends the entire state object. When averaged over a game, only ten bytes are changed every 45 seconds. To put that in context, 32KiB of unnecessary data is sent to every browser for each point scored instead of the ten bytes that have changed, representing a synchronization (or lack of) overhead of more than 3,200x the delta.
As we’ve invested a lot of time this year in introducing native delta support to the Ably platform, I was intrigued to see how deltas would perform in this real-world use case. We originally looked at using JSON patch as an obvious choice to get something out the door quickly, but decided against it due to inefficiencies and, of course, it only works for JSON.
Instead, we wanted to find an algorithm that was portable and efficient both from a compression and performance perspective (CPU cost generating deltas needed to be directly in line with the payload size). We found Xdelta to be the best fit along with VCDiff as our delta encoding algorithm.
As you can see in the graphs above, when applying deltas to polling, long polling, SSE or Websocket transports, we get practically no ongoing overhead to deliver scoring updates. Over a five-minute window, once the initial state is set up, Google’s polling solution consumes 282KiB of data from the Google servers, whereas using Xdelta (encoded with base-64) over a WebSocket transport, only 426 bytes are needed. That represents 677x less bandwidth needed over a five-minute window, and 30x less bandwidth when including the initial state set up.
You can see working examples using Xdelta on the Ably platform below:
- Ably Server-Sent Event (SSE) stream without an Ably message envelope.
- Ably Websocket stream with an Ably message envelope (we do not currently support unenveloped Websocket streams in our production APIs)
If you would like to see the calculations for the graphs above, see this spreadsheet.
Wrapping This All Up
It’s hard to know why Google’s engineering teams haven’t invested in optimizing this aspect of their search results. Including the overhead and data synchronization inefficiencies, their approach requires 38x more bandwidth than a Websocket + delta solution, and delivers latencies that are 25x higher on average. Any company not operating at such scale would be forced to design and implement a more efficient method simply due to bandwidth costs.
I have a few theories on this:
- Realtime is a hard engineering problem at scale. Without a pub/sub, primitive Google’s engineering teams can rely on at Internet scale, perhaps it’s just easier to keep it simple, poll like it’s the 90s, and forget that customers are suffering from these bandwidth inefficiencies. Please note that I realize Google has products like Firebase for this use case. Firebase explicitly limits the service to 200k concurrent connections per database, which perhaps makes it unsuitable for real-time scores.
- Front-end engineering at Google is not considered important. Google is without a doubt an amazing company with incredible engineering talent. However, it’s quite plausible that the best engineers are deployed on core systems and infrastructure, and front-end engineering is treated as a second-class citizen.
- Google’s opting to optimize later. Premature optimization is rarely a good idea. Perhaps optimizing this part of the system, once it’s gained enough traction and support from the product team, is Google’s preferred option, and the bandwidth costs for Google and Google customers is just not material for them. It just seems an unusual choice given Google is constantly telling everyone else that speed and bandwidth optimization matters, and they'll prioritize search results based on this: https://developers.google.com/speed.
Either way, it’s encouraging to see the internet becoming more realtime, and I applaud Google nonetheless for supporting ‘real-time’ scores in search results. I look forward to reviewing the optimization work they do in future iterations of this feature.
About the Author
I’m Matt, the CEO, and co-founder of Ably. I am very interested in realtime problems, realtime engineering, and where the industry is headed. That’s the reason I co-founded Ably, which provides cloud infrastructure and APIs to help developers simplify complex real-time engineering. Organizations build with Ably because we make it easy to power and scale realtime features in apps, or distribute data streams to third-party developers as realtime APIs.
If you’re interested in chatting to me about realtime problems, distributed systems, or this article, please do reach out to me at @mattheworiordan or @ablyrealtimeon Twitter.
Caveats When Reading This Article:
- TCP overhead has not been factored in. Given all transports are over TCP (or QUIC), the underlying networking protocol overhead will remain relatively constant.
- Compression at an HTTP (gzip, deflate, brotley) or Websocket (frame compression) level is not factored in. All transports support compression, so compression has been ignored.
- Overhead of dependencies to use various transports or provide delta encoding capabilities has not been included. There are numerous ways to approach this problem and as such the permutations of dependencies are endless. Given most CDNs now support dependencies that are cached and idempotent (i.e. can be cached near indefinitely) we feel this is not relevant to this experiment either.
- The Websocket calculations are based on a raw Websocket streaming connection, something Ably does not officially support in production. Our “normal” Websocket connections additionally carry an envelope that provides richer functionality such as knowing a message ID, being able to resume from a point in time, automatic generic encoding and decoding based on an encoding field.
Published at DZone with permission of Kieran Kilbride-Singh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments