''Hey, Amazon! Where Is My Crop?'' How to Resize in The Cloud
If you are familiar with the Nginx extention to crop your images, take a look at how you can get the same result using Amazon AWS.
Join the DZone community and get the full member experience.
Join For Free
Hello everyone, and I am glad to see you reading this text. In practice, we always strive to achieve the best performance and the highest speed for content delivery for our clients. Most of the time, we use the Nginx crop and resize extension called - image_filter for that. But what about fully serverless, automatically scalable out, and extremely fast architecture for the cloud?
Architecture
Amazon can help us out. But first of all, we need to talk about the basis of future architecture. There are four main AWS services we will need:
IAM service. It helps manage the permissions for the other three services, just to obtain access to them.
S3 storage. We use S3 to store our image files. S3 is pretty cheap, unlimited in size and, in my opinion, the most robust storage in the world. By the way, Amazon guarantees 99.999999999% availability.
Amazon CloudFront. It is a very fast and easy-to-use Content Delivery Network (CDN)-based on Amazon Edge Locations used throughout the world.
Lambda Service. It lets you run your code without any kind of server management. Lambda automatically scales it out, so you can run several functions concurrently. You pay only for the resources and the time you spend on your code to complete.
After talking about the services, which are ready to bring our architecture to life, let us speak about the architecture itself. Here is the scheme:
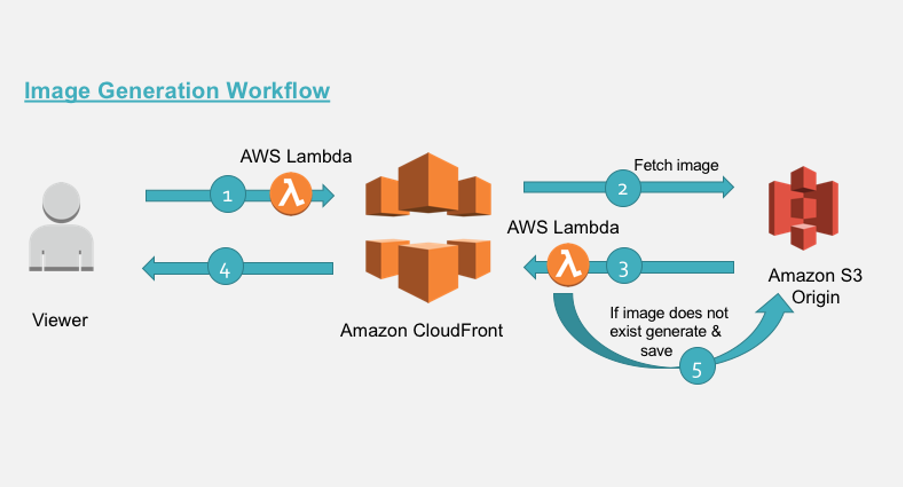
I must tell you that Amazon has issued an article on resizing in the cloud. However, in this article, we will make some steps of this process cheaper and easier, just for faster starting from scratch. So, let’s see how it works. All the life cycle can be described in five simple steps:
- We send a request via CloudFront CDN to grab an existing image. CloudFront receives it and triggers the Lambda function as well as AWS CloudFront called - viewer-request. Lambda changes the request image destination if we have GET parameter named d=widthxheight and transforms it to
[ROOT_FOLDER]/widthxheight/[PATH_TO_IMAGE]/[IMAGE_NAME].[IMAGE_EXTENSION]. - Next, CloudFront inquires if S3 Origin has the image.
- S3 responds to CloudFront and here CloudFront triggers another Lambda function that works with the trigger called - origin-response. Lambda checks that S3 answer status is 403 (not 404. If the file does not exists, it goes back to 403 by default). So, if the status code is really 403 and we don’t have the image on S3, we need to create it.
- If the status is 2xx, we just simply throughput the response back to the user before this CloudFront caches it to improve further requests.
- So, if we get 403 Lambda use the
getObjectfunction of S3 SDK to grab the body of the real image and resize it with the defined dimensions.
We will use a sharp library (Node.js) for resizing. If you work with another programming language, you can simply rewrite the code in your language if needed. Just follow the required steps and remember about the important tips that we have put below in the text.
Steps Involved
So, having cleared out the workflow, let’s speak about each step.
S3
First of all, we need to create the S3 bucket where our file should be stored. Go to the AWS Console, the Storage section, select S3, and create the bucket in any region you want. All buckets are not public by default, so leave them as default.
CloudFront
The next step is creating the CloudFront distribution. Move to the AWS Console, Networking & Content Delivery section, and select CloudFront. Create a New Distribution, select Newly Created S3 bucket as a source, enable Restricted Access and leave other parameters as default, except for one — Query String Forwarding and Caching. Select Forward all, the cache based on the whitelist and put "d" in the text area input. This variable is responsible for the cache and the number of rows that can be unique in the cache and depends on the query string parameters ( GET parameters, like ?d=100x100).
Let’s consider the difference in some examples. CloudFront works only with paths by default, so we can have one row for each unique path in the cache
xxxxxx.cloudfront.net/avatars/1.jpg AND xxxxxx.cloudfront.net/avatars/2.jpg.But in our cases, we use the additional parameter that defines the dimensions of the image. We may want to store different sizes for each real size image in the cache. So, it can be
xxxxxx.cloudfront.net/avatars/1.jpg?d=110x90 OR xxxxxx.cloudfront.net/avatars/1.jpg?d=100x50and others.
And they all will be different images. Therefore, to improve our speed, we can cache them with the all Edge Locations that Amazon can provide.
IAM
After creating a new S3 bucket, we can distribute it to users. Now we are ready to get around to the code part of our architecture. But before moving to the step with Lambda, we need to create the role that will have the required policy permissions to access S3 with the read and write permissions and to store logs to CloudWatch, just for debugging's sake. Go to AWS Console, Security, Identity & Compliance section, select IAM and click on the Roles menu. Create a new role named ResizesLambdaExecutionRole, select S3 for the service that will use this role section and attach AmazonS3FullAccess and CloudFrontFullAccess policies. After that, hit Create the Role and move to the Role Settings, Permissions tab, and add the New Policy. On the new window click Create a new policy and then the JSON tab. Paste the policy below to the input:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": [
"arn:aws:logs:*:*:*"
]
}
]
}and after that click View and Save. Eventually, we get the role with three attached policies.
Lambda
Thus, following all the manipulations, we have all we need to serve or code. As I have said above, we need to create two Lambda functions:
- The first one for the viewer-request trigger;
- The second one for the region-response trigger.
Important Notes
Before starting, you need to know some important things that are necessary to understand:
- CloudFront triggers are available only for region N. Virginia - us-east-1. But unlike the AWS blog article, we can create S3 anywhere, and CloudFront speeds up the missing latency because our Lambda functions will work in the us-east-1 region only.
- All URLs or all the requests in CloudFront triggers always starts with "/." Just note that when making code changes if needed.
- To test the functions updated by you or newly created in another language, you need to visit this page. Here you can find examples of each CloudFront and Edge@Lambda triggers and their event data. Just grab that data and do your own specific tests.
- Edge@Lambda functions can’t have any environment variables.
- All our code works on Node.js 6.10 v. So, if you understand these tips, you won’t have any problems with Lambda on resizing in the cloud.
1st Lambda
Let’s start with the first Lambda. Move to the AWS console, computing section, and select Lambda. Create a new Lambda function named imageRequestViewer and attach an existing role, that was created some time ago for LambdaExecute. Set memory to 128, and timeout to 1 second. The logics of the first function is pretty simple:
- Validate that we have GET parameter named ?d=100x100.
- If it does not exist in the query string, we push the request to callback the function and terminate the Lambda function.
- If the parameter exists, we need to parse the parameter with the x splitting and match the width to the height. If we do this correctly and find new image dimensions, we can move forward. If not, move to the second step.
- Now we have dimensions. Before moving to the required URL transformation step, we need to apply some optimization. We have variables in the code that tells us what dimensions are available to transform and what the default dimensions are. We need these improvements to minimize our charges because every user can access CloudFront URL. We actually have a variance parameter. It is a minimally acceptable deviation in percentage in + and - sides that we can round to the available dimensions.
- After all the validations, we change the request URL and push it to the CloudFront. Just remember that we call our function before the request will process by CloudFront.
You can change all the data before the handler function the way you want. ROOT_DIRECTORY is the variable that defines the name of the prefix folder in the transformed path:
[ROOT_FOLDER]/widthxheight/[PATH_TO_IMAGE]/[IMAGE_NAME].[IMAGE_EXTENSION].You can also change the regular expression if your URL is different. Then
/[PATH_TO_IMAGE]/image.jpgHere is the code:
const querystring = require('querystring');
const $rootFolder = 'resized-images';
const $mainRegex = new RegExp('^\/(.+\/)?([A-Za-z\-\_0-9]+[A-Za-z0-9])\.([a-zA-Z]+)$');
const variables = {
allowedDimension : [
{w:100,h:100}, {w:200,h:200}, {w:300,h:300}, {w:400,h:400}, {w:500,h:500},
{w:600,h:600}, {w:700,h:700}, {w:800,h:800}, {w:900,h:900}, {w:1000,h:1000}
],
defaultDimension : {w:500,h:500},
variance: 20
};
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const headers = request.headers;
console.log(request);
// parse the querystrings key-value pairs. In our case it would be d=100x100
const params = querystring.parse(request.querystring);
// fetch the uri of original image
let fwdUri = request.uri;
// if there is no dimension attribute, just pass the request
if(!params.d || !$mainRegex.test(fwdUri)){
callback(null, request);
return;
}
// read the dimension parameter value = width x height and split it by 'x'
const dimensionMatch = params.d.split("x");
// set the width and height parameters
let width = dimensionMatch[0];
let height = dimensionMatch[1];
// define variable to be set to true if requested dimension is allowed.
let matchFound = false;
// calculate the acceptable variance. If image dimension is 105 and is within acceptable
// range, then in our case, the dimension would be corrected to 100.
let variancePercent = (variables.variance/100);
for (let dimension of variables.allowedDimension) {
let minWidth = dimension.w - (dimension.w * variancePercent);
let maxWidth = dimension.w + (dimension.w * variancePercent);
if((width == dimension.w && height == dimension.h ) || (width >= minWidth && width <= maxWidth)){
width = dimension.w;
height = dimension.h;
matchFound = true;
break;
}
}
console.log("Is Matched ", matchFound);
console.log("Finded %sx%s", width, height);
// if no match is found from allowed dimension with variance then set to default
//dimentions.
if(!matchFound){
width = variables.defaultDimension.w;
height = variables.defaultDimension.h;
}
// parse the prefix, image name and extension from the uri.
// In our case /images/image.jpg
const match = fwdUri.match($mainRegex);
console.log(match);
let prefix = match[1] ? match[1].slice(0, -1) : '' ;
let imageName = match[2];
let extension = match[3];
let url = [];
// build the new uri to be forwarded upstream
url.push($rootFolder);
url.push(width+"x"+height);
if(prefix != ''){ url.push(prefix); }
url.push(imageName+"."+extension);
fwdUri = url.join("/");
// final modified url is of format /ROOT_FOLDER/200x200/path/image.jpg
request.uri = '/' + fwdUri;
callback(null, request);
};After your code is ready, you need to publish a new version of the code and set the CloudFront - viewer-request trigger to it.
2nd Lambda
The second function is a little bit complicated. Move to AWS console, select Lambda menu, and create a new Lambda function originResponseChanger. Set the memory usage to 512 and timeout to 5 seconds. This should be enough. So, before discussing the code, let’s speak about some interesting things:
- If you need to work in multiple environments, you need to have multiple CloudFront distributions. That means that if you want to have dev and prod buckets, you need two CloudFront CDNs.
- Every Lambda function can have many versions. Every version is immutable to changes and can have their own environments and memory set parameters. So, use it to change buckets for dev and prod envs.
- This function needs some node_modules that are not installed on AWS by default. So, you need to upload the code in the zip archive or from S3. The archive will be provided below in the article.
So, now we are ready to start working on the second Lambda.
- You need to configure the bucket which is connected to the current CloudFront distribution.
- Change the regular expression to parse transformed URL if you change it. By default we expects to see
[ROOT_FOLDER]/widthxheight/[PATH_TO_IMAGE]/[IMAGE_NAME].[IMAGE_EXTENSION]-
after the transformation.
- Our logic starts from checking the response from S3. If we receive a 403, that means the image with the transformed path does not exists and we need to create it.
- If the Status Code is 2xx, we will push the request to the next destination by the callback function.
- After all the checks, we parse the transformed URL to define the original image full path (for getObject AWS SDK function).
- Having defined all the directions, we grab the body of the existing image and resize it. Having finished the work on the image and received a new one, we cache it by providing a CacheControl header. Here is the code:
const http = require('http');
const https = require('https');
const querystring = require('querystring');
const AWS = require('aws-sdk');
const S3 = new AWS.S3({
signatureVersion : 'v4',
region : 'eu-central-1'
});
const Sharp = require('sharp');
// set the S3 and API GW endpoints
const BUCKET = '[YOUR BUCKET NAME HERE]';
const $mainRegex = new RegExp('^([a-z\-]+)\/(?:([0-9]{2,4})x([0-9]{2,4}))\/(.+\/)?([A-Za-z\-\_0-9]+[A-Za-z0-9])\.([a-zA-Z]+)$');
exports.handler = (event, context, callback) => {
let response = event.Records[ 0 ].cf.response;
//check if image is not present
if (response.status == 403) {
let request = event.Records[ 0 ].cf.request;
let params = querystring.parse(request.querystring);
// if there is no dimension attribute, just pass the response
if (!params.d) {
callback(null, response);
return;
}
// read the required path. Ex: uri /images/100x100/webp?/image.jpg
let path = request.uri;
// read the S3 key from the path variable.
// Ex: path variable /images/100x100/webp?/image.jpg
let key = path.substring(1);
// parse the prefix, width, height and image name
// Ex: key=images/200x200/webp?/image.jpg
let prefix, originalPath, originalKey, match, width, height, requiredFormat, imageName;
let startIndex;
match = key.match($mainRegex);
prefix = match[ 1 ];
originalPath = match[ 4 ] ? match[ 4 ] : '';
width = parseInt(match[ 2 ], 10);
height = parseInt(match[ 3 ], 10);
// correction for jpg required for 'Sharp'
requiredFormat = match[ 6 ] == "jpg" ? "jpeg" : match[ 6 ];
imageName = match[ 5 ];
originalKey = originalPath + imageName + '.' + match[ 6 ];
console.log("Matched data: %s, %s, %s, %s, %s, %s, %s", prefix, width, height, originalPath, imageName, requiredFormat, originalKey);
// get the source image file
S3.getObject({ Bucket : BUCKET, Key : originalKey }).promise()
// perform the resize operation
.then(data => Sharp(data.Body)
.resize(width, height)
.toFormat(requiredFormat)
.toBuffer()
)
.then(buffer => {
// save the resized object to S3 bucket with appropriate object key.
S3.putObject({
Body : buffer,
Bucket : BUCKET,
ContentType : 'image/' + requiredFormat,
CacheControl : 'max-age=31536000',
Key : key,
StorageClass : 'STANDARD'
}).promise()
// even if there is exception in saving the object we send back the generated
// image back to viewer below
.catch(() => {
console.log("Exception while writing resized image to bucket")
});
// generate a binary response with resized image
response.status = 200;
response.body = buffer.toString('base64');
response.bodyEncoding = 'base64';
response.headers[ 'content-type' ] = [ { key : 'Content-Type', value : 'image/' + requiredFormat } ];
callback(null, response);
})
.catch(err => {
console.log("Exception while reading source image :%j", err);
});
} // end of if block checking response statusCode
else {
// allow the response to pass through
callback(null, response);
}
};After your code has been uploaded and saved, publish the new version of the function and set the CloudFront trigger named - origin-response.
That's it. Now you can grab the resized images:
xxxx.cloudfront.net/avatars/1.jpg?d=100x50For more information, refer to Attract Group.
Opinions expressed by DZone contributors are their own.
Comments