The Future of Rollouts: From Big Bang to Smart and Secure Approach to Web Application Deployments
This article proposes a new way of using AWS to roll out updates safely to targeted user groups, reducing risk and improving user experience.
Join the DZone community and get the full member experience.
Join For FreeThe evolution of web application deployment demands efficient canary release strategies. In the realm of canary releases, various solutions exist. Traditional "big bang" deployments for web applications pose significant risks, hindering rapid innovation and introducing potential disruption. Canary deployments offer a controlled release mechanism, minimizing these risks. However, existing solutions for web applications often involve complex tooling and server-side infrastructure expertise. This paper introduces a novel canary deployment architecture leveraging readily available Amazon Web Services (AWS) tools – CloudFront and S3 – to achieve simple, secure, and cost-effective canary deployments for web applications. The integration of AWS CloudFront, S3, and Lambda@Edge not only simplifies deployment intricacies but also ensures robust monitoring capabilities.
In today's dynamic web application landscape, rapid feature updates and enhancements are crucial for competitiveness and user experience. Yet, traditional "big bang" deployments pose significant risks:
- Potential regressions: Unexpected issues introduced by new features can disrupt the entire user base.
- Delayed feedback: Early identification of problems becomes challenging, slowing down improvement cycles.
- User dissatisfaction: Negative experiences from a failed update can damage user trust and adoption.
Canary deployments address these challenges by gradually rolling out updates to a controlled subset of users, typically based on specific criteria like device type, location, or user group. This controlled approach enables:
- Early feedback: Issues are identified and addressed quickly, minimizing impact on the broader user base.
- Reduced risk: Rollbacks or adjustments can be made without affecting the entire population.
- Improved confidence: Data-driven insights gathered from the canary group inform optimization and broader deployment decisions.
While widely adopted for service updates, implementing canary deployments for web applications traditionally requires:
- Complex tooling: Feature flags, server-side routing mechanisms, and custom caching strategies can be intricate and time-consuming to implement.
- Infrastructure expertise: A deep understanding of server-side infrastructure and configuration is often necessary.
These requirements can often be prohibitive for smaller teams or projects with limited resources. In this guide, we will uncover a streamlined approach to canary deployments using AWS CloudFront and S3, demystifying complexities and ensuring a user-friendly experience.
Proposed Architecture
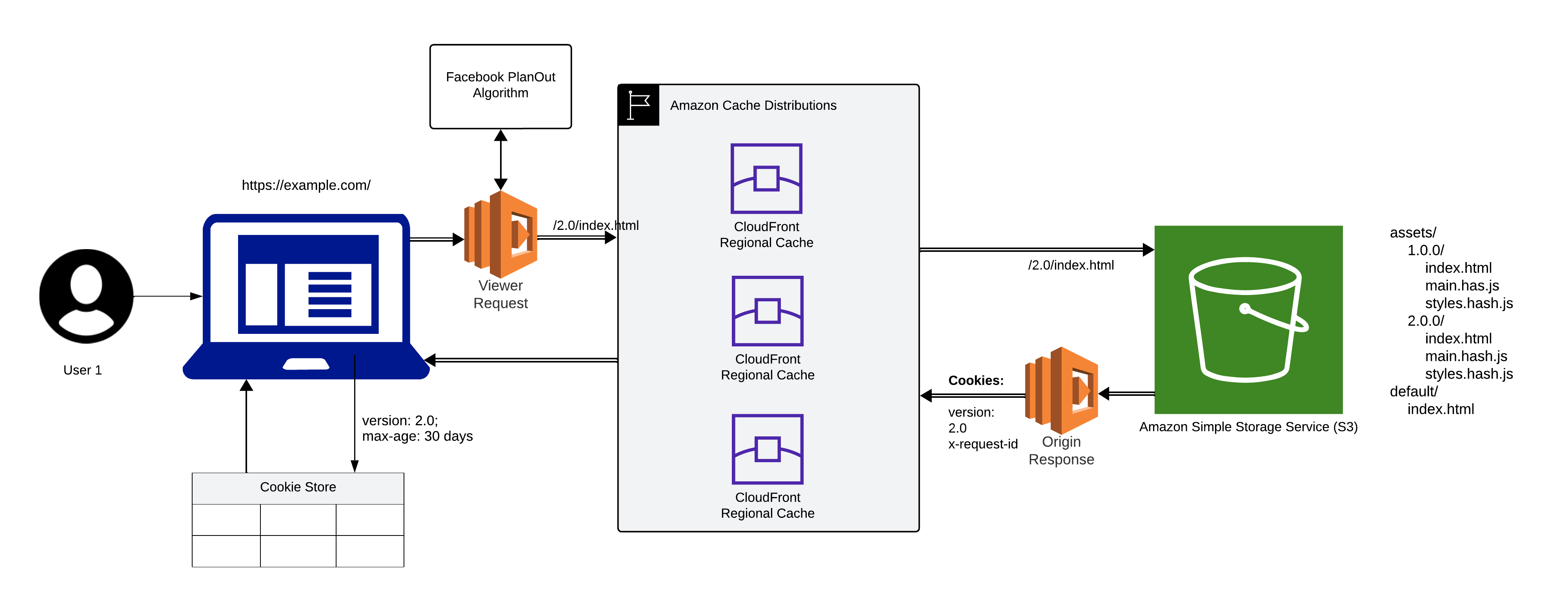
This paper presents a novel canary deployment architecture for web applications that leverages the readily available capabilities of AWS CloudFront and S3, overcoming the aforementioned challenges and enabling a simple, secure, and cost-effective approach.
Key Components
- AWS CloudFront: Acts as a content delivery network (CDN) for the web application, caching static content and routing requests based on predefined behaviors.
- AWS S3: Provides object storage for the web application's build artifacts, including individual version directories and a default directory containing fallback resources.
- Lambda@Edge: Lambda@Edge functions execute custom logic processing for requests on the edge of the CloudFront network, before they reach the origin server. They house and execute the Facebook PlanOut algorithm in this architecture.
- Versioning: Each web application version has its own directory within the S3 bucket, containing all required assets. The default directory holds fallback resources like a generic "index.html" for unforeseen scenarios.
Understanding AWS CloudFront: Your Global Content Delivery Ally
What Is CloudFront?
AWS CloudFront is not just a content delivery network (CDN); it's a global network of servers strategically positioned to cache and serve your web application's static assets. By reducing latency and enhancing overall performance, CloudFront acts as a reliable intermediary between your users and your application.
AWS Lambda@Edge
Lambda@Edge extends the capabilities of AWS Lambda, enabling the execution of custom code at edge locations within the CloudFront network. This service offers several advantages for canary deployments:
- Low Latency: By executing functions closer to the end user, Lambda@Edge significantly reduces latency compared to traditional server-side logic. This results in faster response times and a more responsive user experience.
- Reduced Origin Server Load: Offloading request and response processing to the edge network minimizes the load on the origin server, improving its overall performance and scalability.
- Custom Request and Response Handling: Lambda@Edge functions can be used to tailor request routing, content modification, and response generation, enabling granular control over the deployment process and user experience.
Lambda@Edge supports four types of functions; each triggered at specific points in the request-response cycle:
1. Viewer Request: Executes when CloudFront receives a request from a viewer (user). It allows for:
- Modifying request headers and routing.
- Performing authentication and authorization.
- Implementing user segmentation and targeting logic.
- Gathering user information
- Dynamically selecting content based on conditions.
2. Origin Request: Executes before CloudFront forwards a request to the origin server. It's useful for:
- Transforming requests before reaching the origin.
- Optimizing requests for specific origins.
- Add or modify headers for origin communication.
3. Origin Response: Executes after CloudFront receives a response from the origin server but before it's cached or returned to the viewer. It enables:
- Modifying response headers and content.
- Implementing caching logic
- Redirecting or rewriting responses.
- Collecting metrics and logging data
- Handling errors and fallback scenarios
4. Viewer Response: Executes before CloudFront returns the response to the viewer, allowing for:
- Final content modifications
- Personalizing responses based on viewer information
- Implementing security measures
- Optimizing content for different devices or networks
Behaviors of CloudFront: A Strategic Hierarchy
Before we embark on our canary deployment journey, let's explore CloudFront's behaviors - rules that dictate how different types of requests are handled. Custom behaviors are defined within CloudFront to handle different types of requests, focusing primarily on assets and the default behavior for index.html:
- Assets Behavior: Requests for static assets like images, scripts, fonts, and CSS (/assets/*) trigger custom caching headers for longer expiration times. "index.html" paths reference version-specific directories for these assets (e.g., /assets/1.0.0/main.js).
- Default Behavior: The catch-all behavior executed when requests don't match specific patterns. It provisions two Lambda functions, orchestrating dynamic decisions at the edge:
- Viewer Request Function:
- Retrieves the user's device ID (stored in cookies or other mechanisms).
- Calls the Facebook PlanOut API, providing the device ID and other relevant targeting criteria.
- Receives the targeted version from Facebook PlanOut (e.g., "2.0.0").
- If a targeted version is returned:
- Modifies the request path to point to that version's index.html (e.g., /assets/2.0.0/index.html).
- Removes any version cookies (preventing unnecessary cache busting).
- If targeting fails or no previous version cookie exists:
- Serves the default index.html from the default directory.
- Origin Response Function
- Viewer Request Function:
Adds a cookie to the response with the served version as the "last known good" version for fallback scenarios. This ensures that if subsequent requests encounter issues, the user can be reverted to a previously successful version.
3. Deployment Flow
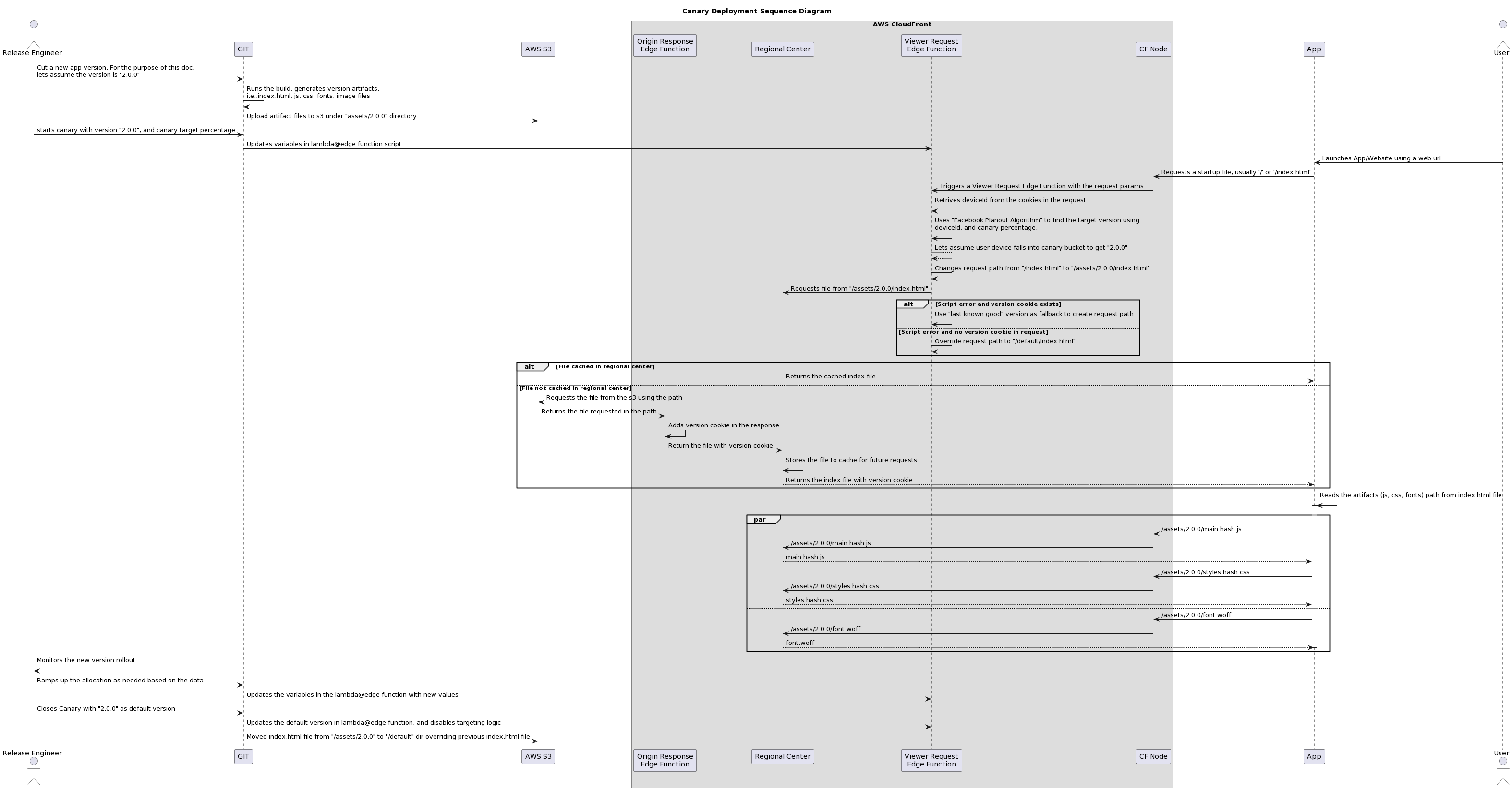
Initiation
- Release Engineer Cuts New Version: The release engineer initiates the process by creating a new version of the web application (e.g., "2.0.0") in the Git repository.
- Build and Artifact Generation: The build process generates the version's artifacts, including index.html, JavaScript, CSS, font, and image files.
- Artifact Upload to S3: The generated artifacts are uploaded to the designated version directory within the S3 bucket (e.g., /assets/2.0.0).
- Canary Start: The release engineer initiates the canary deployment by specifying the target version ("2.0.0") and the desired canary percentage (e.g., 10%).
- Lambda@Edge Function Update: The script for the Viewer Request Lambda@Edge function is updated with the new version information and canary percentage.
User Request
- User Launches Application: The user accesses the application's URL, triggering a request for the startup file (usually /index.html).
- CloudFront Triggers Viewer Request Function: CloudFront intercepts the request and activates the Viewer Request Lambda@Edge function.
- Device ID Retrieval: The function retrieves the user's device ID from cookies or other mechanisms.
- Facebook PlanOut Targeting: The function calls the Facebook PlanOut API to determine the target version based on the device ID, canary percentage, and other criteria.
- Version Targeting: If the user falls within the canary bucket (e.g., 10% probability), the function modifies the request path to point to the new version's index.html (e.g., /assets/2.0.0/index.html).
- Fallback for Errors: If a script error occurs and a version cookie exists, the function uses the "last known good" version as a fallback. If no cookie exists, it defaults to the generic index.html.
File Retrieval
- CloudFront Caching: If the requested index.html is cached in the regional center, CloudFront returns it directly.
- S3 Fetch: If not cached, CloudFront retrieves the file from S3 and passes it through the Origin Response Lambda@Edge function.
Origin Response Function
- Version Cookie Addition: The Origin Response function adds a version cookie to the response, indicating the served version for potential fallback.
- Caching: CloudFront caches the file in the regional center for future requests.
Asset Retrieval
- Reading Artifact Paths: The user's browser reads the paths for additional assets (JavaScript, CSS, fonts) from the index.html file.
- Asset Requests: The browser sends separate requests for each asset, following the version-specific paths.
- CloudFront Handling: CloudFront caches and serves assets as needed, similar to the index.html process.
Monitoring and Ramp-Up
- Deployment Monitoring: The release engineer monitors the new version's performance and user feedback.
- Canary Expansion: If successful, the canary is expanded to a larger user group by updating the variables in the Lambda@Edge function.
Closure and Default Rollout
- Canary Closure: When confident in the new version, the release engineer closes the canary and makes it the default.
- Function Updates: The Lambda@Edge functions are updated to serve the new version as the default and disable targeting logic.
- Default Directory Update: The index.html file from the new version is moved to the /default directory in S3, ensuring all future requests receive the latest version.
By leveraging readily available AWS tools and integrating with Facebook PlanOut, this paper proposes a novel approach to canary deployments, contributing to the field by simplifying implementation and democratizing access to this essential practice. This architecture paves the way for developers and organizations to confidently embrace iterative updates and deliver enhanced user experiences while minimizing exposure to potential regressions.
Note: While this paper specifically demonstrates integration with Facebook PlanOut, the proposed architecture is designed to be flexible and can be adapted to work with various experimentation tools and user segmentation mechanisms available within your organization. This empowers developers and organizations to leverage their existing infrastructure and preferred tools to implement this canary deployment approach effectively.
Opinions expressed by DZone contributors are their own.
Comments