Hot Data: Where Real-Time Insight Begins
Processing hot data has significant value in the modern age, as it enables businesses to make instant decisions with low-latency, fault-tolerant, real-time systems.
Join the DZone community and get the full member experience.
Join For FreeHot data means the data currently being created, accessed, and queried in real-time or near real-time. The latest and most time-critical data, such as live events, user interactions, sensor measurements, or transaction streams, often require the processing to be right away and latency to be low.
Hot (or warm for Gradient Data) has the greatest short-term value, so it is often kept in fast or streaming systems that are designed to process and return data very rapidly to provide instant insights and make lightning decisions.
Hot data is so important in stream processing pipelines because it contains the most recent, high-value information you need to make real-time decisions. Hot data processing allows organizations to approximate, in real time, how systems are behaving so they can identify anomalies and react when conditions change by sounding the alarm, personalizing customer experiences, or optimizing operations. Stream processing systems specialize in keeping this data in motion, making sure the data is fresh, accurate, and has an immediate business impact.
Typical Challenges in Hot Data Processing
Low-Latency Requirements
For hot data, there is not much time for reprocessing in milliseconds or even seconds. Quick processing is key for hot data because its value drops fast over time. If you don't handle it, real-time insights can become useless or even cause problems. Hot data helps make fast choices, trigger automatic actions, and respond to users right away. This includes spotting fraud, keeping an eye on systems, suggesting things, or updating live dashboards.
When there's a delay, decisions rely on old info, feedback loops get shaky, and users find the system slow or unreliable. Speedy processing makes sure the data is used while it still matters. This leads to accurate, timely decisions and keeps real-time systems running as expected.
High Data Velocity
Streams can arrive at a very high rate, and it is non-trivial to scale the processing without sacrificing data or facing backpressure. Fast data flow is key for handling hot data because it comes in non-stop, often in big chunks.
The system needs to keep pace with this incoming stream to stay useful. When data pops up — think user actions, sensor readings, or transaction events — any slowdown in taking it in and working with it can cause backlogs, delays, and lost information. Keeping up with high-speed data makes sure the system can deal with events as they happen, keep things in the right order and context, and give a real-time view. This allows for quick choices and actions based on the newest info.
State Management
It is hard to keep an up-to-date, consistent state (windows, aggregates, and joins) in real time, especially at scale. State management needs to play a key role in hot data processing. This is because real-time choices often rely on more than just single events. They also depend on how these events relate to the recent past and the current setting.
Hot data tasks need to keep track of things like user sessions, ongoing totals, counters, time frames, or system states. All of these must receive quick, accurate updates as new events arrive. When state management is not reliable, it can result in mixed-up, outdated, or incorrect data, leading to poor decision-making and unstable behavior in real-time systems. Effective state management ensures that data remains consistent, accurate, and resilient, thereby enabling high-performance data processing systems to maintain an up-to-date perspective of the present moment, even when handling substantial loads and continuous fluctuations.
Fault Tolerance
Systems should recover rapidly from failures and not lose or duplicate events. The environment for hot data processing often contains a high level of fault tolerance, owing to the need for real-time processing and the time-critical nature of the processed data. When a real-time system fails, immediate loss of data occurs with substantial costs related to that failure. Numerous real-time systems are exposed to possible hardware or network failure, as well as software crashes, resulting in loss of data, inconsistencies in the system state, and missed events that cannot be timely recovered without fault tolerance.
Use of fault-tolerant mechanisms, such as replication, checkpointing, and automatic recovery, is necessary to ensure continued processing with minimum impact on the correctness of data and the reliability of the system. Because of this, systems for hot data processing will be able to keep operating consistently and to make accurate real-time decisions even if the system has incurred faults.
Data Consistency and Ordering
Correctness and late/out-of-order/repeated events are difficult to manage. In hot data processing, data consistency and ordering play a very critical role because decisions and actions are often made in real time based on continuously arriving events. As long as the data is consistent, every system component has a shared, reliable view of the current state, which eventually prevents contradictory results such as double-counting, missed updates, or incorrect alerts.
Proper ordering is too important as it ensures that events are processed in the sequence they actually occurred, which is essential for accurately tracking state changes, detecting patterns, and enforcing business rules like thresholds or time windows. Hot data pipelines can produce misleading insights and trigger incorrect automated actions when there is no strong consistency or correct ordering.
Maintaining data consistency and ordering in hot data processing is especially challenging as data arrives at high velocity from distributed sources that operate independently and often across different networks and time zones. Besides, there are multiple factors like network latency, retries, or system failures that might cause the events to be delayed, duplicated, or arrive out of order, and eventually make it difficult to maintain a single, accurate view of state in real time. In order to maintain low-latency requirements, systems often process data in parallel, which further complicates the coordination and sequencing across multiple streams.
Operational Complexity
In real-time data pipelines, it is harder to monitor, debug, and tune due to their continuous nature than batch systems. There is an operational complexity in hot data processing because the systems involved in the entire processing must ingest, process, and respond to data in real time by maintaining high availability, low latency, and strong consistency guarantees. Unlike batch or cold data workloads, hot data pipelines operate continuously and leave little space for failure, making monitoring, scaling, and fault recovery significantly more challenging, and that makes the entire architecture more challenging.
Proper coordination is absolutely necessary among engineers, architects, etc., who are responsible for maintenance/managing distributed components such as streaming platforms, in-memory stores, and real-time analytics engines. Handling data spikes, schema changes, and strict SLAs are additional challenges.
The need for rapid decision-making, constant optimization, and robust observability across these tightly coupled systems increases the operational burden and makes hot data processing inherently complex to manage.
Final Thoughts
In real-time data pipelines, it is harder to monitor, debug, and tune due to their continuous nature than batch systems
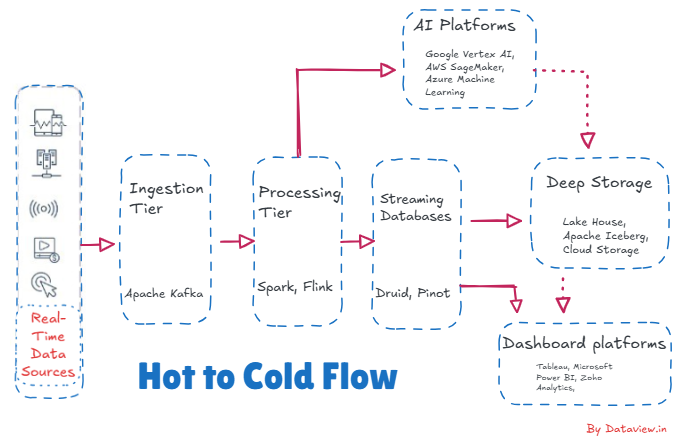
When data’s business value and accessibility have passed its convenience, warm data cools off. Newly created data in a data lifecycle is “hot,” meaning it needs to be immediate and served up for real-time decisions, alerts, and operational responses. Over time, that same data is used less frequently and no longer needs to be processed at low-latency, so it moves to colder storage and processing layers.
In application, such a transition is determined by time, usage, and processing stages. Hot data is first treated in streaming systems (such as Flink or Spark Streaming) and may be enriched or aggregated. After it serves its original purpose, it is compressed, abbreviated, or archived and sent to cost-effective storage, like data lakes, object storage, or warehouses. That cold data is then put to historic analysis, reporting, compliance, or model training, not real-time actions.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments