Hot-Cold Data Separation: What, Why, and How?
Hot data is the frequently accessed data, while cold data is the one you seldom visit but still need. Separating them is for higher efficiency in computation and storage.
Join the DZone community and get the full member experience.
Join For FreeApparently, hot-cold data separation is hot now. But first of all:
What Is Hot/Cold Data?
In simple terms, hot data is the frequently accessed data, while cold data is the one you seldom visit but still need. Normally in data analytics, data is "hot" when it is new and gets "colder" and "colder" as time goes by.
For example, orders from the past six months are "hot," and logs from years ago are "cold." But no matter how cold the logs are, you still need them to be somewhere you can find.
Why Separate Hot and Cold Data?
Hot-Cold Data Separation is an idea often seen in real life: You put your favorite book on your bedside table, your Christmas ornament in the attic, and your childhood art project in the garage or a cheap self-storage space on the other side of town. The purpose is a tidy and efficient life.
Similarly, companies separate hot and cold data for more efficient computation and more cost-effective storage because storage that allows quick read/write is always expensive, like SSD. On the other hand, HDD is cheaper but slower. So it is more sensible to put hot data on SSD and cold data on HDD. If you are looking for an even lower-cost option, you can go for object storage.
In data analytics, hot-cold data separation is implemented by a tiered storage mechanism in the database. For example, Apache Doris supports three-tiered storage: SSD, HDD, and object storage. For newly ingested data, after a specified cooldown period, it will turn from hot data into cold data and be moved to object storage. In addition, object storage only preserves one copy of data, which further cuts down storage costs and the relevant computation/network overheads.
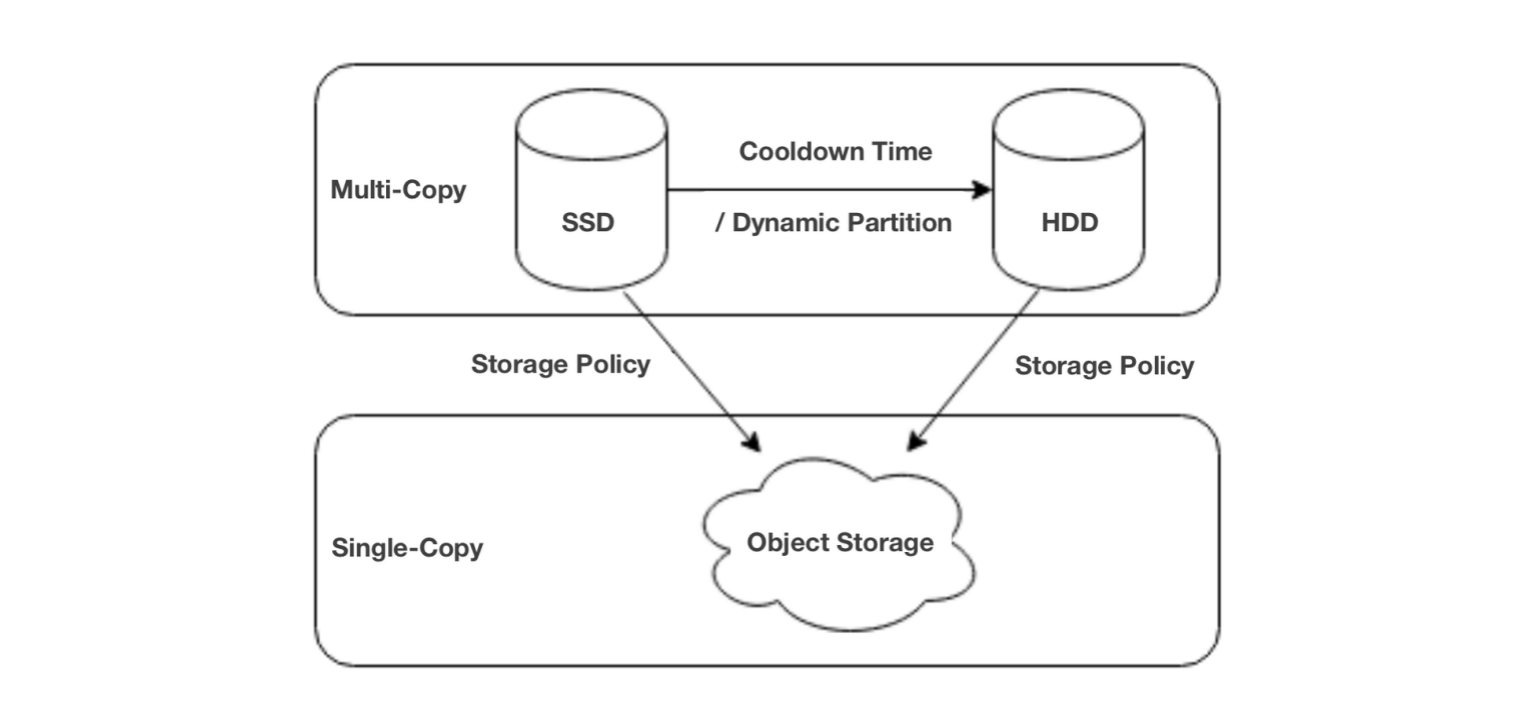
How much can you save by hot-cold data separation? Here is some math.
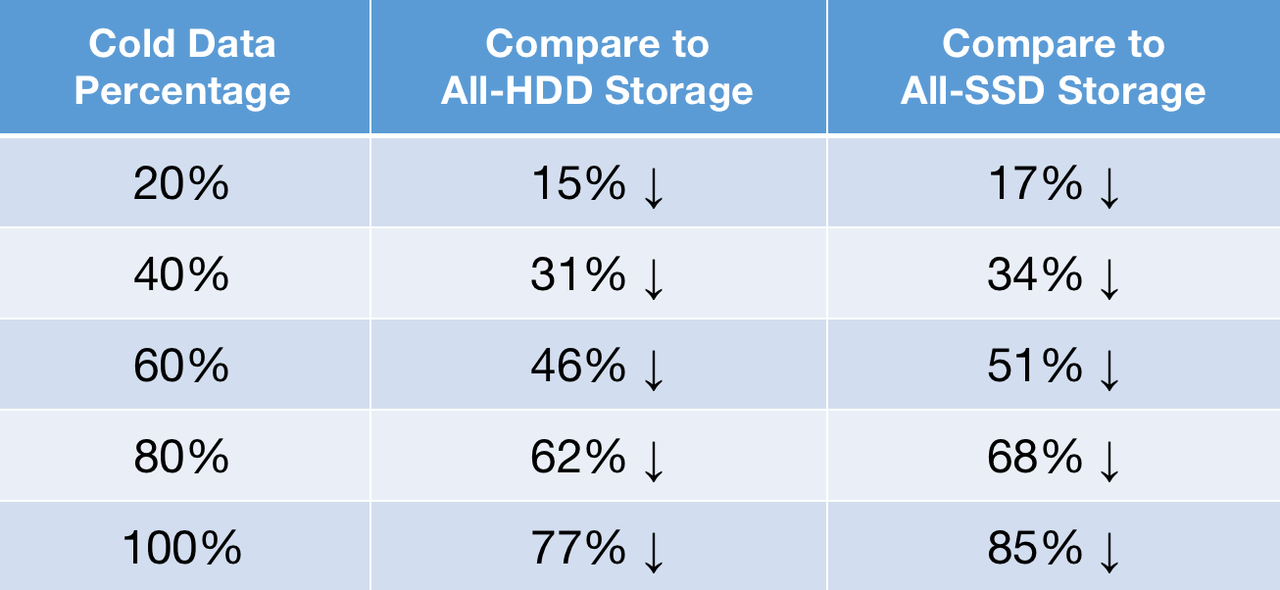
In public cloud services, cloud disks generally cost 5~10 times as much as object storage. If 80% of your data asset is cold data and you put it in object storage instead of cloud disks, you can expect a cost reduction of around 70%.
Let the percentage of cold data be "rate," the price of object storage be "OS," and the price of cloud disk be "CloudDisk," this is how much you can save by hot-cold data separation instead of putting all your data on cloud disks:
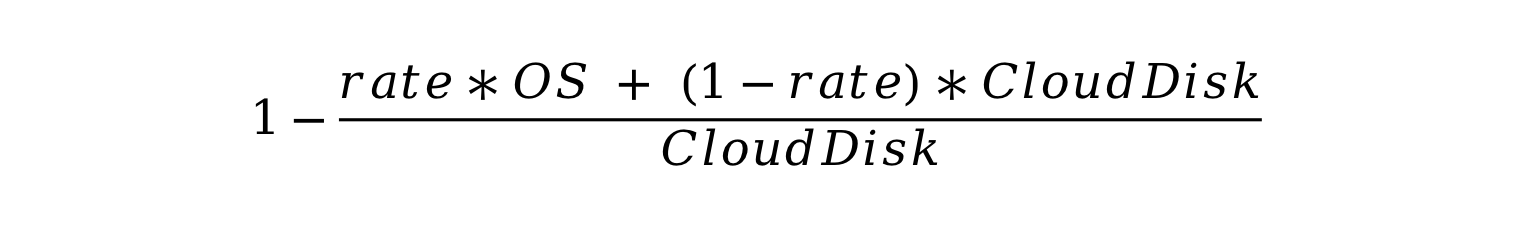
Now let's put real-world numbers in this formula:
AWS pricing, US East (Ohio):
- S3 Standard Storage: 23 USD per TB per month
- Throughput Optimized HDD (st 1): 102 USD per TB per month
- General Purpose SSD (gp2): 158 USD per TB per month
How Is Hot-Cold Separation Implemented?
Till now, hot-cold separation sounds nice, but the biggest concern is: how can we implement it without compromising query performance? This can be broken down into three questions:
- How to enable quick reading of cold data?
- How to ensure the high availability of data?
- How to reduce I/O and CPU overheads?
In what follows, I will show you how Apache Doris addresses them one by one.
Quick Reading of Cold Data
Accessing cold data from object storage will indeed be slow. One solution is to cache cold data in local disks for use in queries. In Apache Doris 2.0, when a query requests cold data, only the first-time access will entail a full network I/O operation from object storage. Subsequent queries will be able to read data directly from the local cache.
The granularity of caching matters, too. A coarse granularity might lead to a waste of cache space, but a fine granularity could be the reason for low I/O efficiency. Apache Doris bases its caching on data blocks. It downloads cold data blocks from object storage onto the local Block Cache. This is the "pre-heating" process. With cold data fully pre-heated, queries on tables with hot-cold data separation will be basically as fast as those on tablets without. We drew this conclusion from test results on Apache Doris:
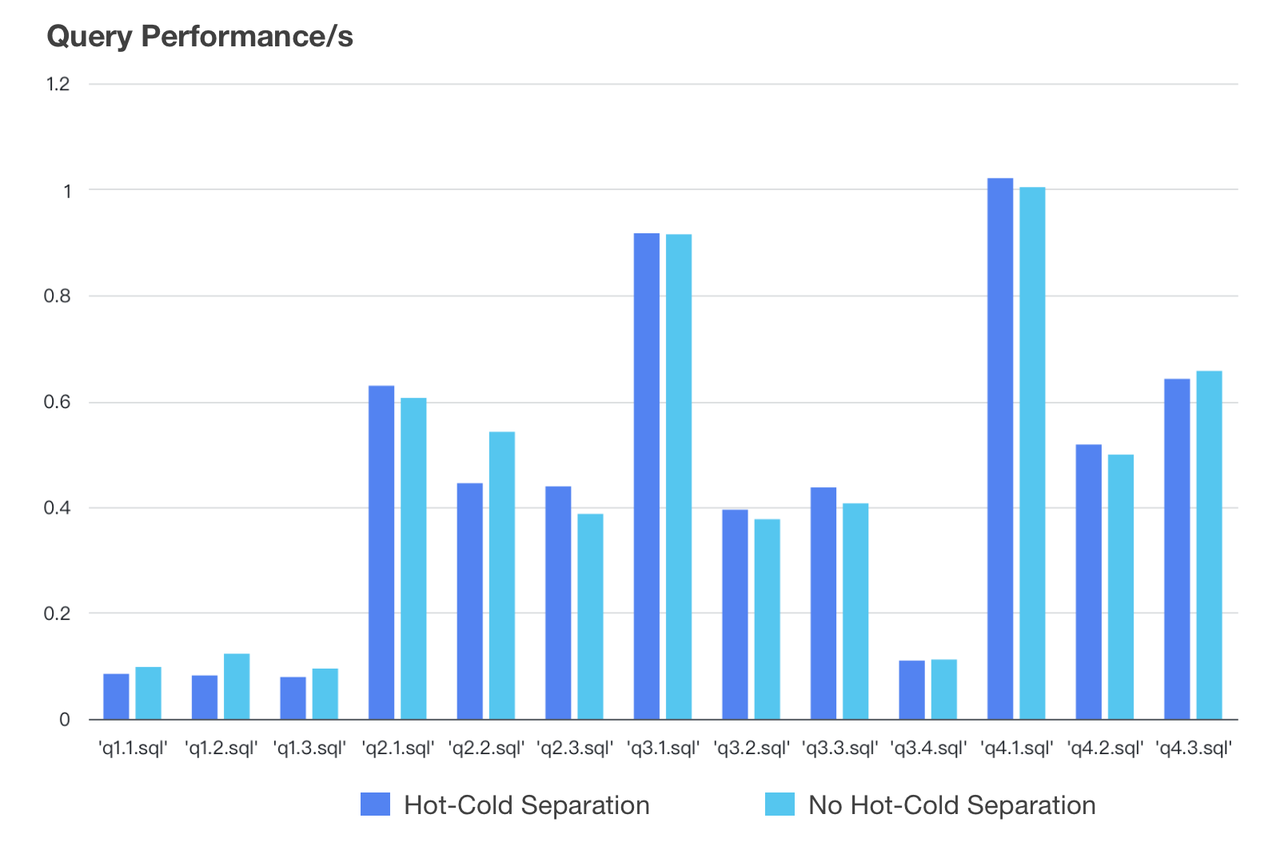
- Test Data: SSB SF100 dataset
- Configuration: 3 × 16C 64G, a cluster of 1 frontend and 3 backends
P.S. Block Cache adopts the LRU algorithm, so the more frequently accessed data will stay in Block Cache for longer.
High Availability of Data
In object storage, only one copy of cold data is preserved. Within Apache Doris, hot data and metadata are put in the backend nodes, and there are multiple replicas of them across different backend nodes in order to ensure high data availability. These replicas are called "local replicas." The metadata of cold data is synchronized to all local replicas so that Doris can ensure the high availability of cold data without using too much storage space.
Implementation-wise, the Doris front end picks a local replica as the Leader. Updates to the Leader will be synchronized to all other local replicas via a regular report mechanism. Also, as the Leader uploads data to object storage, the relevant metadata will be updated to other local replicas, too.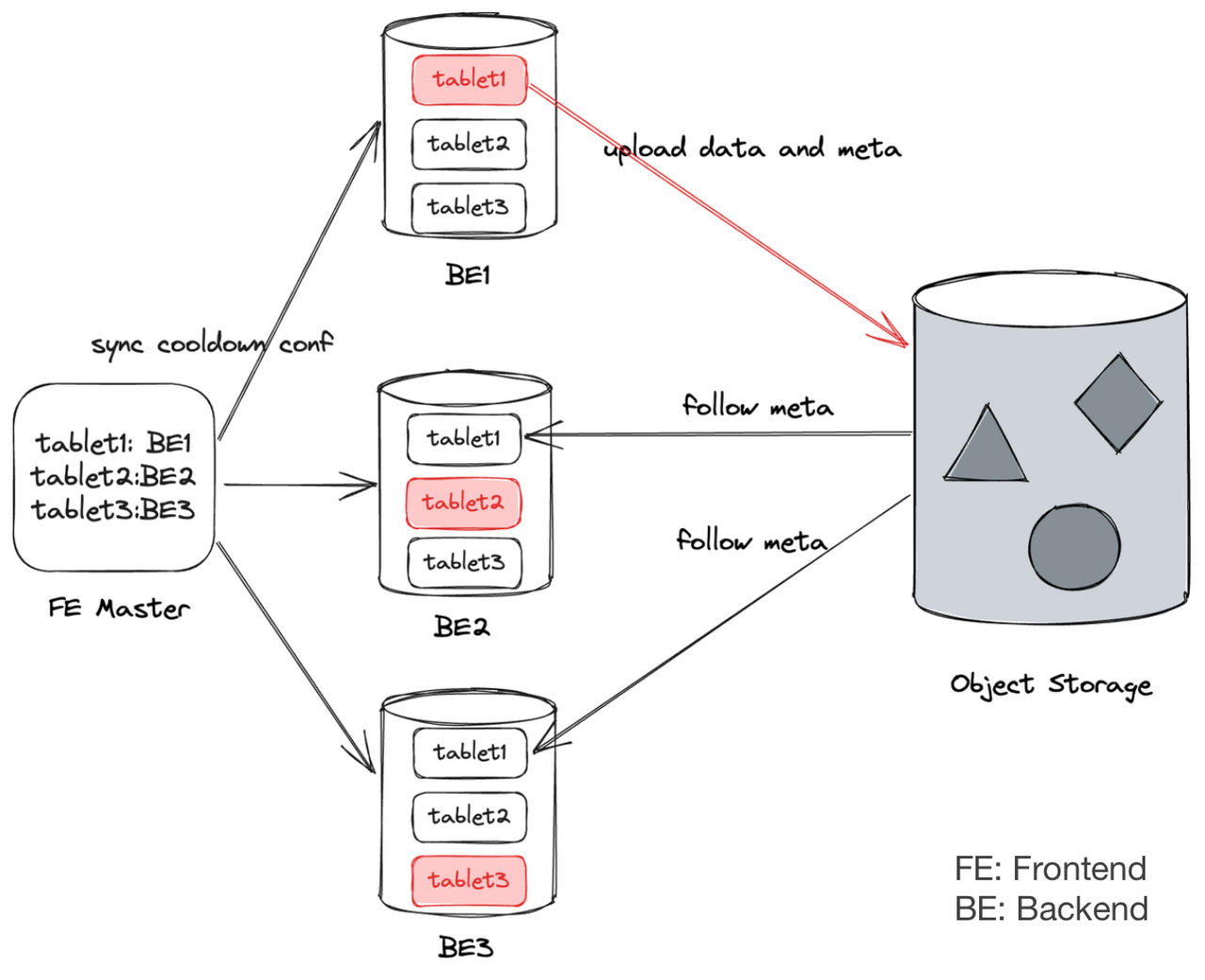
Reduced I/O and CPU Overhead
This is realized by cold data compaction. Some scenarios require large-scale updates of historical data. In this case, part of the cold data in object storage should be deleted. Apache Doris 2.0 supports cold data compaction, which ensures that the updated cold data will be reorganized and compacted so that it will take up storage space.
A thread in Doris' backend will regularly pick N tablets from the cold data and start compaction. Every tablet has a CooldownReplica, and only the CooldownReplica will execute cold data compaction for the tablet. Every time 5MB of data is compacted, it will be uploaded to object storage to clear up space locally. Once the compaction is done, CooldownReplica will update the new metadata to object storage. Other replicas only need to synchronize the metadata from object storage. This is how I/O and CPU overheads are reduced.
Conclusion
Separating hot and cold data in storage is a huge cost saver, and there have been ways to ensure the same fast query performance. Executing hot-cold data separation is a simple six-step process, so you can find out how it works yourself.
Published at DZone with permission of Shirley H.. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments