Data Pipeline Techniques in Action
Take a deep dive into the architectural concepts of data pipelines along with a hands-on tutorial for implementation, demonstrating the concepts in action.
Join the DZone community and get the full member experience.
Join For FreeThe topics covered are:
- Data pipeline architecture
- High-scale data ingestion
- Data transformation and processing
- Data storage
- Staging data delivery
- Operational data
- Hands-on exercise
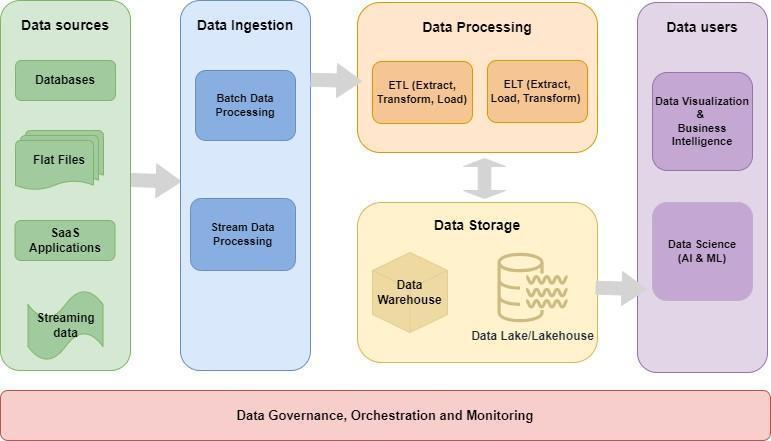
Data Pipeline Architecture
A data pipeline architecture consists of components and systems that provide services at every layer of the end-to-end data flow. The phases are data ingestion, data transformation and processing, data storage, data delivery, and data consumption for applications and operational data stores.
The data flow starts with an arbitrary data source which can be a database, flat files, enterprise applications, real-time streaming data, etc.
High Scale Data Ingestion
Data ingestion is the process of acquiring, mapping, and validating the received data and moving the data to the data processing phase. Architecture facets associated with the data ingestion process for the modern data pipeline architecture are as follows:
- Data mapping: This is the process of mapping the data structure to the pipeline format. Map the data using configuration or flatten the data on the fly. A schema-agnostic approach is elastic. Any format such as JSON, XML, or CSV can be flattened to an unstructured format that the pipeline processes.
- Data elasticity: Unflatten the unstructured pipeline data into a structured format for analysis.
- High-scale ingestion: Ability to handle the volume and velocity of data being generated
- Batch-based ingestion: Pulls data from the source on a scheduled basis
- On-time ingestion: Receives data as a real-time stream
- Ordering: A data event is ordered based on the timestamp of the receipt.
- Data consistency: No duplicates and no data loss; same data event but still one copy; once received saved in a log
Data Transformation and Processing
This phase results in the cleaning and transformation of data for the downstream system, followed by processing for the next data storage phase.
Architecture facets associated with the data transformation/processing phase for the modern data pipeline architecture:
- Cleaning: Make the data relevant.
- Transformation: Change values for relevance to the use case.
- Processing at scale: Add many parallel data pipelines. Data should stay consistent.
- Processing with accuracy: No duplicates on repetitive data events; the source dataset must match the destination dataset.
Data Storage
This phase persists the processed data into a storage system like a data warehouse or a datalake. The data stored in these systems can be used for many use cases such as analytics, training AI models, bridging data silos between enterprise applications, business intelligence, etc.
Architecture facets associated with the data storage process are as follows:
- Storing data: Store data for future retrieval, and analysis, or any other use case.
- Organizing data: Organizing data optimized for query performance
- Security and compliance: Data lifecycle for retention and regulatory compliance if applicable
Staging Data Delivery
This phase is where data pipelines can differ in their implementations. Some may call the previous data storage phase the final destination. Some provide this phase to deliver processed data to individual storage systems used for operational systems. However, that results in two phases: staging the data followed by an automated process or a manual process to make the data operational. They also differ in what storage systems they support out of the box. These systems are standard systems like relational databases, NoSQL, real-time search systems, etc.
Architecture facets associated with the staging data delivery phase include:
- Parallel, or serial: Data processing can be parallel, as one route stores data to a datalake or data warehouse, and another delivers data for staging. Parallel is efficient and faster.
- Data connector support: A data pipeline implementation will provide support for standard storage systems like MongoDB, MySQL, ElasticSearch, Snowflake, etc.
- Data connector framework: It may also provide a data connector framework to connect to custom storage systems.
Supporting this phase with a data pipeline has the following advantages:
- Enterprise data silos: Connect multiple storage systems within your enterprise to keep them in sync in real-time with data consistency.
- Supporting external data partners: Deliver data to multiple external storage systems.
Operational Data Phase
This is also a phase where data pipelines can differ in their implementation. This is the phase that processes staged data in operational systems and makes it live data.
Architecture facets associated with the operational data phase are:
- Automated and real-time: A data pipeline can provide a data integration framework that can invoke custom logic to process staged data and make it live data as part of the data flow process.
- Batch or manual: In this case, an organization can use a background process or manually process the staged data to make it live data.
Hand-On Exercise
This hands-on exercise will involve implementing an end-to-end data pipeline. The implementation will involve the data flow that will cover the following phases:
- Data ingestion
- Data transformation and processing
- Data storage
- Staging data delivery
It uses the open-source Braineous data platform (download here). Ignore the "Too big to load" message and click on the Download button.
- This tutorial is located under braineous-1.0.0-cr3/tutorials/get-started.
Installation
Note that Braineous has the following service dependencies:
The latest release, CR3, requires adjusting these services to your localhost setup for these services. The next release, CR4, will streamline the localhost service detection and a Kubernetes container out of the box.
Here are the localhost instructions for each service before running Braineous on localhost:
Zookeeper
Modify braineous-1.0.0-cr3/bin/start_zookeeper.sh script from:
~/mumma/braineous/infrastructure/kafka_2.13-3.5.0/bin/zookeeper-server-start.sh
/Users/babyboy/mumma/braineous/infrastructure/kafka_2.13-3.5.0/config/zookeeper.properties. . . to your local Zookeeper bin and config directories.
Kafka
Modify braineous-1.0.0-cr3/bin/start_kafka.sh script from:
~/mumma/braineous/infrastructure/kafka_2.13-3.5.0/bin/kafka-server-start.sh
/Users/babyboy/mumma/braineous/infrastructure/kafka_2.13-3.5.0/config/server.properties. . . to your local Kafka bin and config directories.
Flink
Modify braineous-1.0.0-cr3/bin/start_flink.sh script from:
~/mumma/braineous/infrastructure/flink-1.18.1/bin/start-cluster.sh. . . to your local Flink bin directory.
Hive Metastore
Modify braineous-1.0.0-cr3/bin/start_metastore.sh script from:
export HADOOP_HOME=~/mumma/braineous/infrastructure/hadoop-3.3.6
export HIVE_HOME=~/mumma/braineous/infrastructure/apache-hive-3.1.3-bin
export HADOOP_CLASSPATH=$HIVE_HOME/conf:$HIVE_HOME/lib
~/mumma/braineous/infrastructure/apache-hive-3.1.3-bin/bin/hive --service metastore. . . to your respective Hadoop/Hive local installations. In addition, change the following property in the local_hive_installation/conf/hive-site.xml file from my localhost file system location to yours.
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/Users/babyboy/data_warehouse/hive</value>
<description>location of default database for the warehouse</description>
</property>
<property>Braineous
- Modify braineous-1.0.0-cr3/conf/braineous.config:
#hive
hive_conf_directory=/Users/babyboy/mumma/braineous/infrastructure/apache-hive-3.1.3-bin/conf
table_directory=file:///Users/babyboy/datalake/- Modify the
hive_conf_directoryandtable_directoryproperties to point to directories on your localhost filesystem. - CR4 will make the localhost out-of-the-box experience optimal, and also provide a Kubernetes Container.
Once your localhost services and configuration for Zookeeper, Kafka, Flink, and Hive Metastore are set up, follow the rest of the steps for the hands-on exercise to create the data pipeline.
Step 1: Install MongoDB
brew tap mongodb/brewbrew updatebrew install [email protected]Step 2: Start Zookeeper
cd braineous-1.0.0-cr3/bin./start_zookeper.shStep 3: Start Kafka
cd braineous-1.0.0-cr3/bin./start_kafka.shStep 4: Start Flink
cd braineous-1.0.0-cr3/bin./start_flink.shStep 5: Start Hive Metastore
cd braineous-1.0.0-cr3/bin./start_metastore.shStep 6: Start Braineous
cd braineous-1.0.0-cr3/bin./start_braineous.shStep 7: Check Braineous Installation Instance Success
cd braineous-1.0.0-cr3/bin./test_installation.shStep 8: Create a Tenant with an API Key and Secret
cd braineous-1.0.0-cr3/bin./pipemon.shPlease use this API key and API secret for the tutorial. More instructions in the data ingestion section to follow.
Data Pipeline Registration
Register a data pipe with the data ingestion engine:
{
"pipeId": "yyya",
"entity": "abc",
"configuration": [
{
"stagingStore" : "com.appgallabs.dataplatform.targetSystem.core.driver.MongoDBStagingStore",
"name": "yyya",
"config": {
"connectionString": "mongodb://localhost:27017",
"database": "yyya",
"collection": "data",
"jsonpathExpressions": []
}
}
]
}For details about the pipe configuration please refer to the Developer Documentation Guide.
Source Data
[
{
"id" : 1,
"name": "name_1",
"age": 46,
"addr": {
"email": "[email protected]",
"phone": "123"
}
},
{
"id": "2",
"name": "name_2",
"age": 55,
"addr": {
"email": "[email protected]",
"phone": "1234"
}
}
]A dataset can be loaded from any data source such as a database, legacy production data store, live data feed, third-party data source, Kafka stream, etc. In this example, the dataset is loaded from a classpath resource located at src/main/resources/dataset/data.json.
Data Ingestion
Data Ingestion Client Implementation
DataPlatformService dataPlatformService = DataPlatformService.getInstance();
String apiKey = "ffb2969c-5182-454f-9a0b-f3f2fb0ebf75";
String apiSecret = "5960253b-6645-41bf-b520-eede5754196e";
String datasetLocation = "dataset/data.json";
String json = Util.loadResource(datasetLocation);
JsonElement datasetElement = JsonUtil.validateJson(json);
System.out.println("*****DATA_SET******");
JsonUtil.printStdOut(datasetElement);
String configLocation = "pipe_config/pipe_config.json";
String pipeConfigJson = Util.loadResource(configLocation);
JsonObject configJson = JsonUtil.validateJson(pipeConfigJson).getAsJsonObject();
String pipeId = configJson.get("pipeId").getAsString();
String entity = configJson.get("entity").getAsString();
System.out.println("*****PIPE_CONFIGURATION******");
JsonUtil.printStdOut(configJson);
//configure the DataPipeline Client
Configuration configuration = new Configuration().
ingestionHostUrl("http://localhost:8080/").
apiKey(apiKey).
apiSecret(apiSecret).
streamSizeInObjects(0);
dataPlatformService.configure(configuration);
//register pipe
dataPlatformService.registerPipe(configJson);
System.out.println("*****PIPE_REGISTRATION_SUCCESS******");
//send source data through the pipeline
dataPlatformService.sendData(pipeId, entity,datasetElement.toString());
System.out.println("*****DATA_INGESTION_SUCCESS******");Please use the API key and API secret generated in Step 8 of the Installation section for the variables:
apiKeyapiSecret
Data Ingestion Client Output
Expected output from the ingestion client:
[INFO] ------------------------------------------------------------------------
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
*****DATA_SET******
******ARRAY_SIZE: 2**********
[
{
"id": 1,
"name": "name_1",
"age": 46,
"addr": {
"email": "[email protected]",
"phone": "123"
}
},
{
"id": "2",
"name": "name_2",
"age": 55,
"addr": {
"email": "[email protected]",
"phone": "1234"
}
}
]
**********************
*****PIPE_CONFIGURATION******
{
"pipeId": "yyya",
"entity": "abc",
"configuration": [
{
"stagingStore": "com.appgallabs.dataplatform.targetSystem.core.driver.MongoDBStagingStore",
"name": "yyya",
"config": {
"connectionString": "mongodb://localhost:27017",
"database": "yyya",
"collection": "data",
"jsonpathExpressions": []
}
}
]
}
**********************
*****PIPE_REGISTRATION_SUCCESS******
***SENDING_DATA_START*****
*****DATA_INGESTION_SUCCESS******Data Pipeline Server Output
Expected output on the data pipeline server:
2024-08-05 19:06:09,071 INFO [org.ehc.siz.imp.JvmInformation] (pool-7-thread-1) Detected JVM data model settings of: 64-Bit OpenJDK JVM with Compressed OOPs
2024-08-05 19:06:09,178 INFO [org.ehc.siz.imp.AgentLoader] (pool-7-thread-1) Failed to attach to VM and load the agent: class java.io.IOException: Can not attach to current VM
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.ehcache.sizeof.ObjectGraphWalker (file:/Users/babyboy/mumma/braineous/data_platform/cr3/braineous_dataplatform/releases/braineous-1.0.0-cr3/bin/dataplatform-1.0.0-cr3-runner.jar) to field java.util.LinkedList.first
WARNING: Please consider reporting this to the maintainers of org.ehcache.sizeof.ObjectGraphWalker
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future releaseMONGODB: DATA_STORED_SUCCESSFULLY
2024-08-05 19:06:16,562 INFO [org.apa.had.hiv.con.HiveConf] (pool-7-thread-1) Found configuration file null
2024-08-05 19:06:17,398 WARN [org.apa.had.uti.NativeCodeLoader] (pool-7-thread-1) Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2024-08-05 19:06:17,492 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-7-thread-1) Setting hive conf dir as /Users/babyboy/mumma/braineous/infrastructure/apache-hive-3.1.3-bin/conf
2024-08-05 19:06:17,791 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-7-thread-1) Created HiveCatalog 'ffbaaaacaaaaaaaaafaaaabafafafbaebfaa'
2024-08-05 19:06:17,871 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-7-thread-1) Trying to connect to metastore with URI thrift://0.0.0.0:9083
2024-08-05 19:06:17,900 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-7-thread-1) Opened a connection to metastore, current connections: 1
2024-08-05 19:06:18,639 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-7-thread-1) Connected to metastore.
2024-08-05 19:06:18,641 INFO [org.apa.had.hiv.met.RetryingMetaStoreClient] (pool-7-thread-1) RetryingMetaStoreClient proxy=class org.apache.hadoop.hive.metastore.HiveMetaStoreClient ugi=babyboy (auth:SIMPLE) retries=1 delay=1 lifetime=0
2024-08-05 19:06:18,907 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-7-thread-1) Connected to Hive metastore
2024-08-05 19:06:19,725 INFO [org.apa.fli.tab.cat.CatalogManager] (pool-7-thread-1) Set the current default catalog as [ffbaaaacaaaaaaaaafaaaabafafafbaebfaa] and the current default database as [default].
2024-08-05 19:06:21,351 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-10-thread-1) Setting hive conf dir as /Users/babyboy/mumma/braineous/infrastructure/apache-hive-3.1.3-bin/conf
2024-08-05 19:06:21,381 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-10-thread-1) Created HiveCatalog 'ffbaaaacaaaaaaaaafaaaabafafafbaebfaa'
2024-08-05 19:06:21,387 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-10-thread-1) Trying to connect to metastore with URI thrift://0.0.0.0:9083
2024-08-05 19:06:21,388 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-10-thread-1) Opened a connection to metastore, current connections: 2
2024-08-05 19:06:21,396 INFO [org.apa.had.hiv.met.HiveMetaStoreClient] (pool-10-thread-1) Connected to metastore.
2024-08-05 19:06:21,397 INFO [org.apa.had.hiv.met.RetryingMetaStoreClient] (pool-10-thread-1) RetryingMetaStoreClient proxy=class org.apache.hadoop.hive.metastore.HiveMetaStoreClient ugi=babyboy (auth:SIMPLE) retries=1 delay=1 lifetime=0
2024-08-05 19:06:21,399 INFO [org.apa.fli.tab.cat.hiv.HiveCatalog] (pool-10-thread-1) Connected to Hive metastore
2024-08-05 19:06:21,459 INFO [org.apa.fli.tab.cat.CatalogManager] (pool-10-thread-1) Set the current default catalog as [ffbaaaacaaaaaaaaafaaaabafafafbaebfaa] and the current default database as [default].
(
`id` STRING,
`name` STRING,
`age` STRING,
`addr.email` STRING,
`addr.phone` STRING,
`0` STRING
)
2024-08-05 19:06:21,863 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlCreateCatalog does not contain a setter for field catalogName
2024-08-05 19:06:21,864 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlCreateCatalog cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,866 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlCreateView does not contain a setter for field viewName
2024-08-05 19:06:21,866 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlCreateView cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,868 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlAlterViewRename does not contain a getter for field newViewIdentifier
2024-08-05 19:06:21,868 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlAlterViewRename does not contain a setter for field newViewIdentifier
2024-08-05 19:06:21,868 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlAlterViewRename cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,871 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlAlterViewProperties does not contain a setter for field propertyList
2024-08-05 19:06:21,871 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlAlterViewProperties cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,873 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlAlterViewAs does not contain a setter for field newQuery
2024-08-05 19:06:21,873 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlAlterViewAs cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,874 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlAddPartitions does not contain a setter for field ifPartitionNotExists
2024-08-05 19:06:21,874 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlAddPartitions cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,875 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlDropPartitions does not contain a setter for field ifExists
2024-08-05 19:06:21,875 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlDropPartitions cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,876 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dql.SqlShowPartitions does not contain a getter for field tableIdentifier
2024-08-05 19:06:21,877 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dql.SqlShowPartitions does not contain a setter for field tableIdentifier
2024-08-05 19:06:21,877 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.dql.SqlShowPartitions cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,878 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dml.SqlTruncateTable does not contain a getter for field tableNameIdentifier
2024-08-05 19:06:21,878 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dml.SqlTruncateTable does not contain a setter for field tableNameIdentifier
2024-08-05 19:06:21,879 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.dml.SqlTruncateTable cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,879 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dql.SqlShowFunctions does not contain a setter for field requireUser
2024-08-05 19:06:21,879 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.dql.SqlShowFunctions cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,882 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dql.SqlShowProcedures does not contain a getter for field databaseName
2024-08-05 19:06:21,882 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.dql.SqlShowProcedures does not contain a setter for field databaseName
2024-08-05 19:06:21,885 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.dql.SqlShowProcedures cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:21,890 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) class org.apache.flink.sql.parser.ddl.SqlReplaceTableAs does not contain a setter for field tableName
2024-08-05 19:06:21,893 INFO [org.apa.fli.api.jav.typ.TypeExtractor] (pool-10-thread-1) Class class org.apache.flink.sql.parser.ddl.SqlReplaceTableAs cannot be used as a POJO type because not all fields are valid POJO fields, and must be processed as GenericType. Please read the Flink documentation on "Data Types & Serialization" for details of the effect on performance and schema evolution.
2024-08-05 19:06:25,192 INFO [org.apa.fli.cli.pro.res.RestClusterClient] (Flink-RestClusterClient-IO-thread-1) Submitting job 'insert-into_ffbaaaacaaaaaaaaafaaaabafafafbaebfaa.yyya.abc' (5854f94a78a2ef2e79b264b97db11592).
2024-08-05 19:06:41,151 INFO [org.apa.fli.cli.pro.res.RestClusterClient] (Flink-RestClusterClient-IO-thread-4) Successfully submitted job 'insert-into_ffbaaaacaaaaaaaaafaaaabafafafbaebfaa.yyya.abc' (5854f94a78a2ef2e79b264b97db11592) to 'http://127.0.0.1:8081'.Data Verification
To verify the success of the ingestion and delivery to the configured target databases, use the following MongoDB commands.
Expected Result
You should see two records added to a collection called "data" in a database called "yyya" corresponding to configured value configuration.config.database.
mongoshuse yyyashow collectionsdb.data.find()db.data.count()Expected Output
yyya> db.data.find()
[
{
_id: ObjectId("66b924b40c964128eb12400a"),
id: 1,
name: 'name_1',
age: 46,
addr: { email: '[email protected]', phone: '123' }
},
{
_id: ObjectId("66b924b40c964128eb12400b"),
id: '2',
name: 'name_2',
age: 55,
addr: { email: '[email protected]', phone: '1234' }
}
]
yyya>
Conclusion
In conclusion, the modern data pipeline architecture provides high-scale data ingestion, data elasticity, ordering, and data consistency. A data pipeline architecture can modernize an organization's data needs for driving insights, analytics, ETL/ELT use cases, and machine learning infrastructure, among other use cases in this digital age.
Opinions expressed by DZone contributors are their own.
Comments