Real-Time Streaming Architectures: A Technical Deep Dive Into Kafka, Flink, and Pinot
While individual components like Kafka, Flink, and Pinot are very powerful, managing them at scale across cloud and on-premises deployments can be operationally complex.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures.
Real-time streaming architectures are designed to ingest, process, and analyze data as it arrives continuously, enabling near real-time decision making and insights. They need to have low latency, handle high-throughput data volumes, and be fault tolerant in the event of failures. Some of the challenges in this area include:
- Ingestion – ingesting from a wide variety of data sources, formats, and structures at high throughput, even during bursts of high-volume data streams
- Processing – ensuring exactly-once processing semantics while handling complexities like stateful computations, out-of-order events, and late data arrivals in a scalable and fault-tolerant manner
- Real-time analytics – achieving low-latency query responses over fresh data that is continuously being ingested and processed from streaming sources, without compromising data completeness or consistency
It's hard for a single technology component to be capable of fulfilling all the requirements. That's why real-time streaming architectures are composed of multiple specialized tools that work together.
Introduction to Apache Kafka, Flink, and Pinot
Let's dive into an overview of Apache Kafka, Flink, and Pinot — the core technologies that power real-time streaming systems.
Apache Kafka
Apache Kafka is a distributed streaming platform that acts as a central nervous system for real-time data pipelines. At its core, Kafka is built around a publish-subscribe architecture, where producers send records to topics, and consumers subscribe to these topics to process the records.
Key components of Kafka's architecture include:
- Brokers are servers that store data and serve clients.
- Topics are categories to which records are sent.
- Partitions are divisions of topics for parallel processing and load balancing.
- Consumer groups enable multiple consumers to coordinate and process records efficiently.
An ideal choice for real-time data processing and event streaming across various industries, Kafka's key features include:
- High throughput
- Low latency
- Fault tolerance
- Durability
- Horizontal scalability
Apache Flink
Apache Flink is an open-source stream processing framework designed to perform stateful computations over unbounded and bounded data streams. Its architecture revolves around a distributed streaming dataflow engine that ensures efficient and fault-tolerant execution of applications.
Key features of Flink include:
- Support for both stream and batch processing
- Fault tolerance through state snapshots and recovery
- Event time processing
- Advanced windowing capabilities
Flink integrates with a wide variety of data sources and sinks — sources are the input data streams that Flink processes, while sinks are the destinations where Flink outputs the processed data. Supported Flink sources include message brokers like Apache Kafka, distributed file systems such as HDFS and S3, databases, and other streaming data systems. Similarly, Flink can output data to a wide range of sinks, including relational databases, NoSQL databases, and data lakes.
Apache Pinot
Apache Pinot is a real-time distributed online analytical processing (OLAP) data store designed for low-latency analytics on large-scale data streams. Pinot's architecture is built to efficiently handle both batch and streaming data, providing instant query responses. Pinot excels at serving analytical queries over rapidly changing data ingested from streaming sources like Kafka. It supports a variety of data formats, including JSON, Avro, and Parquet, and provides SQL-like query capabilities through its distributed query engine. Pinot's star-tree index supports fast aggregations, efficient filtering, high-dimensional data, and compression.
Integrating Apache Kafka, Flink, and Pinot
Here is a high-level overview of how Kafka, Flink, and Pinot work together for real-time insights, complex event processing, and low-latency analytical queries on streaming data:
- Kafka acts as a distributed streaming platform, ingesting data from various sources in real time. It provides a durable, fault-tolerant, and scalable message queue for streaming data.
- Flink consumes data streams from Kafka topics. It performs real-time stream processing, transformations, and computations on the incoming data. Flink's powerful stream processing capabilities allow for complex operations like windowed aggregations, stateful computations, and event-time-based processing. The processed data from Flink is then loaded into Pinot.
- Pinot ingests the data streams, builds real-time and offline datasets, and creates indexes for low-latency analytical queries. It supports a SQL-like query interface and can serve high-throughput and low-latency queries on the real-time and historical data.
Figure 1. Kafka, Flink, and Pinot as part of a real-time streaming architecture
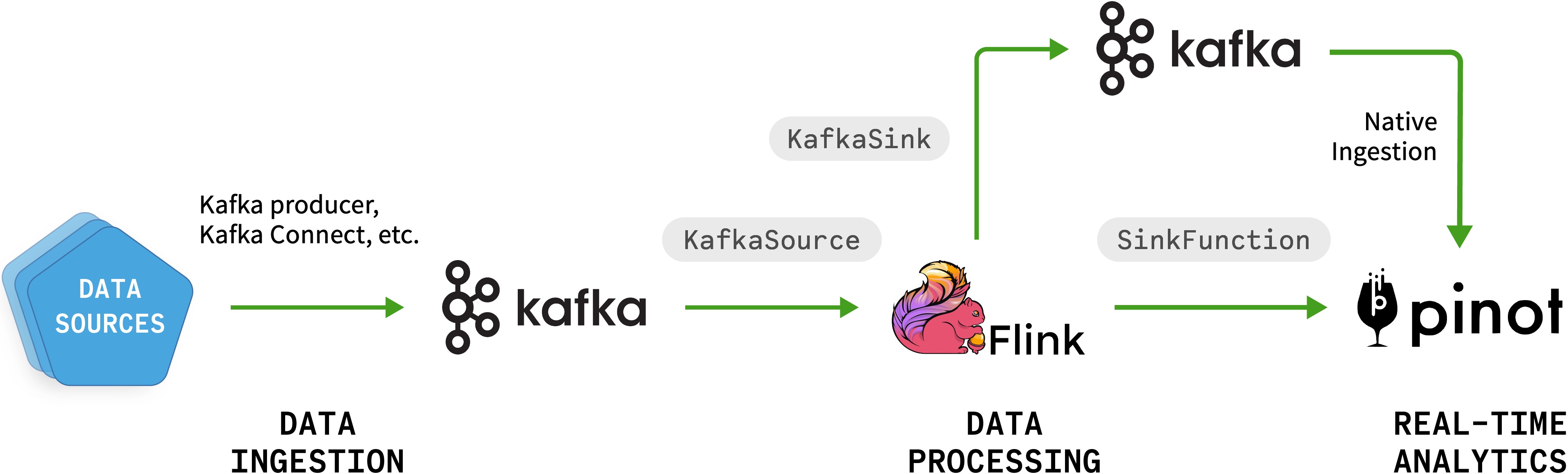
Let's break this down and dive into the individual components.
Kafka Ingestion
Kafka offers several methods to ingest data, each with its own advantages. Using the Kafka producer client is the most basic approach. It provides a simple and efficient way to publish records to Kafka topics from various data sources. Developers can leverage the producer client by integrating it into their applications in most programming languages (Java, Python, etc.), supported by the Kafka client library.
The producer client handles various tasks, including load balancing by distributing messages across partitions. This ensures message durability by awaiting acknowledgments from Kafka brokers and manages retries for failed send attempts. By leveraging configurations like compression, batch size, and linger time, the Kafka producer client can be optimized for high throughput and low latency, making it an efficient and reliable tool for real-time data ingestion into Kafka.
Other options include:
- Kafka Connect is a scalable and reliable data streaming tool with built-in features like offset management, data transformation, and fault tolerance. It can read data into Kafka with source connectors and write data from Kafka to external systems using sink connectors.
- Debezium is popular for data ingestion into Kafka with source connectors to capture database changes (inserts, updates, deletes). It publishes changes to Kafka topics for real-time database updates.
The Kafka ecosystem also has a rich set of third-party tools for data ingestion.
Kafka-Flink Integration
Flink provides a Kafka connector that allows it to consume and produce data streams to and from Kafka topics.
The connector is a part of the Flink distribution and provides fault tolerance along with exactly-once semantics.
The connector consists of two components:
KafkaSourceallows Flink to consume data streams from one or more Kafka topics.KafkaSinkallows Flink to produce data streams to one or more Kafka topics.
Here's an example of how to create a KafkaSource in Flink's DataStream API:
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("ad-events-topic")
.setGroupId("ad-events-app")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
Note that FlinkKafkaConsumer, based on the legacy SourceFunction API, has been marked as deprecated and removed. The newer data-source-based API, including KafkaSource, provides greater control over aspects like watermark generation, bounded streams (batch processing), and the handling of dynamic Kafka topic partitions.
Flink-Pinot Integration
There are a couple options for integrating Flink with Pinot to write processed data into Pinot tables.
Option 1: Flink to Kafka to Pinot
This is a two-step process where you first write data from Flink to Kafka using the KafkaSink component of the Flink Kafka connector. Here is an example:
DataStream<String> stream = <existing stream>;
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("ad-events-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);As part of the second step, on the Pinot side, you would configure the real-time ingestion support for Kafka that Pinot supports out of the box, which would ingest the data into the Pinot table(s) in real time.
This approach decouples Flink and Pinot, allowing you to scale them independently and potentially leverage other Kafka-based systems or applications in your architecture.
Option 2: Flink to Pinot (Direct)
The other option is to use the Flink SinkFunction that comes as part of the Pinot distribution. This approach simplifies the integration by having a streaming (or batch) Flink application directly write into a designated Pinot database. This method simplifies the pipeline as it eliminates the need for intermediary steps or additional components. It ensures that the processed data is readily available in Pinot for low-latency query and analytics.
Best Practices and Considerations
Although there are a lot of factors to consider when using Kafka, Flink, and Pinot for real-time streaming solutions, here are some of the common ones.
Exactly-Once Semantics
Exactly-once semantics guarantee that each record is processed once (and only once), even in the presence of failures or out-of-order delivery. Achieving this behavior requires coordination across the components involved in the streaming pipeline.
- Use Kafka's idempotence settings to guarantee messages are delivered only once. This includes enabling the
enable.idempotencesetting on the producer and using the appropriate isolation level on the consumer. - Flink's checkpoints and offset tracking ensure that only processed data is persisted, allowing for consistent recovery from failures.
- Finally, Pinot's upsert functionality and unique record identifiers eliminate duplicates during ingestion, maintaining data integrity in the analytical datasets.
Kafka-Pinot Direct Integration vs. Using Flink
The choice between integrating Kafka and Pinot directly or using Flink as an intermediate layer depends on your stream processing needs. If your requirements involve minimal stream processing, simple data transformations, or lower operational complexity, you can directly integrate Kafka with Pinot using its built-in support for consuming data from Kafka topics and ingesting it into real-time tables. Additionally, you can perform simple transformations or filtering within Pinot during ingestion, eliminating the need for a dedicated stream processing engine.
However, if your use case demands complex stream processing operations, such as windowed aggregations, stateful computations, event-time-based processing, or ingestion from multiple data sources, it is recommended to use Flink as an intermediate layer. Flink offers powerful streaming APIs and operators for handling complex scenarios, provides reusable processing logic across applications, and can perform complex extract-transform-load (ETL) operations on streaming data before ingesting it into Pinot. Introducing Flink as an intermediate stream processing layer can be beneficial in scenarios with intricate streaming requirements, but it also adds operational complexity.
Scalability and Performance
Handling massive data volumes and ensuring real-time responsiveness requires careful consideration of scalability and performance across the entire pipeline. Two of the most discussed aspects include:
- You can leverage the inherent horizontal scalability of all three components. Add more Kafka brokers to handle data ingestion volumes, have multiple Flink application instances to parallelize processing tasks, and scale out Pinot server nodes to distribute query execution.
- You can utilize Kafka partitioning effectively by partitioning data based on frequently used query filters to improve query performance in Pinot. Partitioning also benefits Flink's parallel processing by distributing data evenly across worker nodes.
Common Use Cases
You may be using a solution built on top of a real-time streaming architecture without even realizing it! This section covers a few examples.
Real-Time Advertising
Modern advertising platforms need to do more than just serve ads — they must handle complex processes like ad auctions, bidding, and real-time decision making. A notable example is Uber's UberEats application, where the ad events processing system had to publish results with minimal latency while ensuring no data loss or duplication. To meet these demands, Uber built a system using Kafka, Flink, and Pinot to process ad event streams in real time.
The system relied on Flink jobs communicating via Kafka topics, with end-user data being stored in Pinot (and Apache Hive). Accuracy was maintained through a combination of exactly-once semantics provided by Kafka and Flink, upsert capabilities in Pinot, and unique record identifiers for deduplication and idempotency.
User-Facing Analytics
User-facing analytics have very strict requirements when it comes to latency and throughput. LinkedIn has extensively adopted Pinot for powering various real-time analytics use cases across the company. Pinot serves as the back end for several user-facing product features, including "Who Viewed My Profile." Pinot enables low-latency queries on massive datasets, allowing LinkedIn to provide highly personalized and up-to-date experiences to its members. In addition to user-facing applications, Pinot is also utilized for internal analytics at LinkedIn and powers various internal dashboards and monitoring tools, enabling teams to gain real-time insights into platform performance, user engagement, and other operational metrics.
Fraud Detection
For fraud detection and risk management scenarios, Kafka can ingest real-time data streams related to transaction data, user activities, and device information. Flink's pipeline can apply techniques like pattern detection, anomaly detection, rule-based fraud detection, and data enrichment. Flink's stateful processing capabilities enable maintaining and updating user- or transaction-level states as data flows through the pipeline. The processed data, including flagged fraudulent activities or risk scores, is then forwarded to Pinot.
Risk management teams and fraud analysts can execute ad hoc queries or build interactive dashboards on top of the real-time data in Pinot. This enables identifying high-risk users or transactions, analyzing patterns and trends in fraudulent activities, monitoring real-time fraud metrics and KPIs, and investigating historical data for specific users or transactions flagged as potentially fraudulent.
Conclusion
Kafka's distributed streaming platform enables high-throughput data ingestion, while Flink's stream processing capabilities allow for complex transformations and stateful computations. Finally, Pinot's real-time OLAP data store facilitates low-latency analytical queries, making the combined solution ideal for use cases requiring real-time decision making and insights.
While individual components like Kafka, Flink, and Pinot are very powerful, managing them at scale across cloud and on-premises deployments can be operationally complex. Managed streaming platforms reduce operational overhead and abstract away much of the low-level cluster provisioning, configuration, monitoring, and other operational tasks. They allow resources to be elastically provisioned up or down based on changing workload demands. These platforms also offer integrated tooling for critical functions like monitoring, debugging, and testing streaming applications across all components.
To learn more, refer to the official documentation and examples for Apache Kafka, Apache Flink, and Apache Pinot. The communities around these projects also have a wealth of resources, including books, tutorials, and tech talks covering real-world use cases and best practices.
Additional resources:
- Apache Kafka Patterns and Anti-Patterns by Abhishek Gupta, DZone Refcard
- Apache Kafka Essentials by Sudip Sengupta, DZone Refcard
This is an excerpt from DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments