Materialized Views in Data Stream Processing With RisingWave
Materialized views enhance data streaming by improving incremental computation, enabling efficient retrieval and calculation of aggregated or pre-processed data.
Join the DZone community and get the full member experience.
Join For FreeIncremental computation in data streaming means updating results as fresh data comes in, without redoing all calculations from the beginning. This method is essential for handling ever-changing information, like real-time sensor readings, social media streams, or stock market figures.
In a traditional, non-entrepreneurial calculation model, we need to process the entire dataset every time we get a new piece of data. It can be incompetent and slow. In incremental calculations, only the part of the result affected by new data is updated.
There are basically three steps involved in incremental computation in data streaming, where the first step starts with an initial computation, which could be the result of the first chunk of data or a default value. In the second step, processing of incoming data as new data streams in, the computation is incrementally updated. There might be adding new values, removing old values that are no longer relevant, and eventually updating intermediate results based on the changes. Finally, the third step is updating intermediate results based on the changes.
How Incremental Computation Benefits From Materialized Views (MV)
Materialized views have boosted incremental computation when it comes to data streaming. They adopted a procedure to enhance the retrieval and calculation of aggregated or pre-processed data across a flow of events or records. By keeping a pre-processed view of the data, materialized views help to update and query large, ever-changing datasets that result in faster and more efficient calculations. Ideally, in terms of the RDBMS concept, a materialized view is a database object that physically keeps the query result rather than recalculating it each time the query is executed.
However, in relation to data streaming, the materialized views can be thought of as preset sets or outcomes that are gradually updated as new data enters the system. Let’s drill down more functionality-wise
Calculating Aggregates in Advance
It is the process of calculating and storing aggregate values (such as sums, averages, counts, min, max, etc.) in advance before they are actually needed for queries or analysis. It also can be termed a precomputed aggregate. The main objective of this process is to improve performance by avoiding redundant calculations.
Instead of repeatedly computing the aggregate values every time a query is made, the system retrieves the precomputed results, which are much faster. It typically works by starting with data collection as data is processed or streamed, and the system aggregates it incrementally. Next is the storage where the aggregated values are stored in a separate data structure. Eventually, upon queries of the data, the system retrieves the precomputed aggregate, which eliminates the need to compute the result from scratch.
With this approach, the system can efficiently handle more queries or data streams by avoiding repeating computations. Streaming applications and large-scale data processing can be beneficial since they enhance query performance by computing and storing summary information beforehand.
Caching Results
When it comes to data streaming, materialized views act like a cache for the query results so that the system does not need to repeatedly access the raw, potentially large stream data. By maintaining a precomputed result, the system ensures that the time-consuming processing steps only need to happen once, and subsequent updates to the view are relatively lightweight.
Efficient Querying
The efficiency of querying is being increased in the materialized views because of storing the results of frequently-used queries (aggregates, counts, averages, etc.). Without scanning the entire dataset every time, the system can instantly return the results. Besides, the materialized views allow more complex computations to be split up and computed into smaller, more manageable pieces.
With the arrival of new data in the system, there might be a chance of causing or affecting the parts of the materialized view. And interestingly, only the affected parts of the materialized view would be updated. This results in the system avoiding the heavy computational burden of full re-evaluations and can focus on modifying just the required aggregates.
Lower Latency
Real-time data processing and decision-making are important features in many streaming applications. The materialized views reduce the time needed to generate the latest results from the incoming datasets by precomputing and storing query results with optimized system resource utilization.
Large Datasets Handling
In enterprise-level systems, using materialized views that update bit by bit helps handle huge amounts of data without straining resources. The system can work with and keep track of small changes, which means it can keep running even as the data gets bigger. Still, we will have to be careful where storage space is limited and economical.
Refining Complex Query Logic
Materialized views make it easier to handle computations when working with tricky logic or changes that need to happen to huge amounts of data. By keeping the results of complex searches or transformations, materialized views offload computation work from the database when new data is processed. This makes incremental computation easier to handle, as only mandatory changes are applied, and the complicated stuff can be distracted away from the main query.

Effective Utilization of Materialized Views in RisingWave
RisingWave is a leading platform for event stream processing, designed to offer a straightforward and cost-effective solution for handling real-time streaming data. It supports a Postgres-compatible SQL interface and a DataFrame-style Python interface. It functions as a streaming database and utilizes materialized views in an innovative manner to enable continuous analytics and data transformations.
This approach is particularly effective for latency-sensitive applications like alerting, monitoring, and trading, ensuring real-time insights and responsiveness. It is designed to deal with streaming data, and materialized views are key to this. These views store pre-calculated query results, letting the system give fresh, current data without redoing entire datasets. As new data flows into the database, the system updates materialized views bit by bit. This shows changes without needing to redo all calculations, which allows for almost real-time analysis.
In RisingWave, we can create materialized views using either tables or streams through source objects. If storing raw stream data isn't necessary, we can simply select the required fields, apply transformations, and retain only the resulting data. Here, materialized views are refreshed automatically and incrementally each time a new event occurs, rather than being updated manually or on a fixed schedule. Once a materialized view is created, the RisingWave engine continuously monitors for relevant incoming events, ensuring efficient computations by processing only the new data. This design minimizes computing overhead.
Additionally, RisingWave offers snapshot read consistency, guaranteeing that queries run against materialized views or tables within the same database produce consistent results across them.
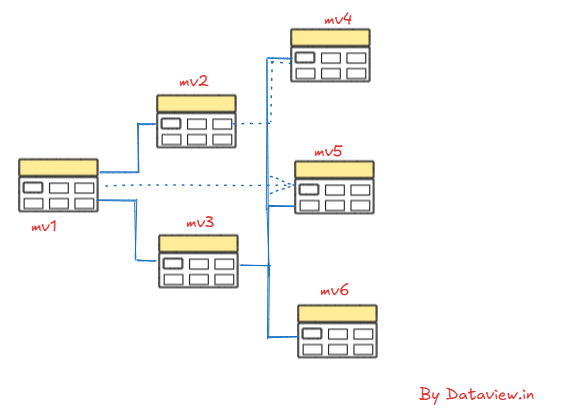
Besides, we can build complex, tree-structured transformations with layered materialized views in order to ensure consistent data at each level and avoid cascading failures or slow refresh rates. In stream processing applications, Apache Kafka often serves as a bridge to integrate various processing workflows.
(You can read here how to integrate Apache Kafka in KRaft Mode with RisingWave for Event Streaming Analytics). The distinct advantage of MV-on-MV lies in its ability to remove the need for intricate inter-system pipelines, enabling you to chain your transformation logic effortlessly.
Note: You can visit here to learn more about RisingWave with all other functionalities, including core product concepts with various source and sink connectors for data streams. In this write-up, I have emphasized leveraging materialized views as a backbond in RisingWave.
I hope you enjoyed reading this. If you found this article valuable, please consider liking and sharing it.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments