ZooKeeper in 15 Minutes
Learn the basics of the features, capabilities, and services of Zookeeper, a coordination service for distributed applications.
Join the DZone community and get the full member experience.
Join For FreeZooKeeper is a coordination service for distributed applications with the motto "ZooKeeper: Because Coordinating Distributed Systems is a Zoo." The ZooKeeper framework was originally built at Yahoo. It runs on JVM (Java virtual machine). A few of the distributed applications that use Zookeeper are Apache Hadoop, Apache Kafka, and Apache Storm.
Features of Zookeeper
Synchronization − Mutual exclusion and co-operation between server processes.
Ordered Messages - The strict ordering means that sophisticated synchronization primitives can be implemented at the client.
Reliability - The reliability aspects keep it from being a single point of failure.
Atomicity − Data transfer either succeeds or fails completely, but no transaction is partial.
High performant - The performance aspects of Zookeeper means it can be used in large, distributed systems.
Distributed.
High avaliablity.
Fault-tolerant.
Loose coupling.
Partial failure.
High throughput and low latency - data is stored data in memory and on disk as well.
Replicated.
Automatic failover: When a Zookeeper dies, the session is automatically migrated over to another Zookeeper.
ZooKeeper is fast. It is especially fast in "read-dominant" workloads. Zookeeper applications run on thousands of machines, and it performs best where reads are more common than writes, at ratios of around 10:1.
The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with transaction logs and snapshots in a persistent store. As long as a majority of the servers are available, the Zookeeper service will be available.
Guarantees
Sequential Consistency - Updates from a client will be applied in the order that they were sent.
Atomicity - Updates either succeed or fail. No partial results.
Single System Image - A client will see the same view of the service regardless of the server that it connects to.
Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
Timeliness - The client's view of the system is guaranteed to be up-to-date within a certain time bound.
Service Provided by Zookeeper
Naming service − Identifying the nodes in a cluster by name. It is similar to DNS, but for nodes.
Configuration management − Latest and up-to-date configuration information of the system for a joining node.
Cluster management − Joining/leaving of a node in a cluster and node status in real time.
Leader election − Electing a node as leader for coordination purposes.
Locking and synchronization service − Locking the data while modifying it. This mechanism helps you in automatic fail recovery while connecting other distributed applications like Apache HBase.
Highly reliable data registry − Availability of data even when one or a few nodes are down.
Zookeeper Buzz Words
Ensemble: Group of Zookeeper servers. The minimum number of nodes that is required to form an ensemble is 3.
Leader: Server node which performs automatic recovery if any of the connected node failed. Leaders are elected on service startup.
Follower: Server node which follows leader instruction.
znodes
znodes refer to the data nodes. Every node in a ZooKeeper tree is referred to as a znode. Data must be small- 1MB maximum.
Zookeeper allows distributed processes to coordinate with each other through a shared hierarchal namespace which is organized similarly to a standard file system. The namespace consists of data registers called znodes. znodes are identified by unique absolute paths which are “/” delimited Unicode strings.
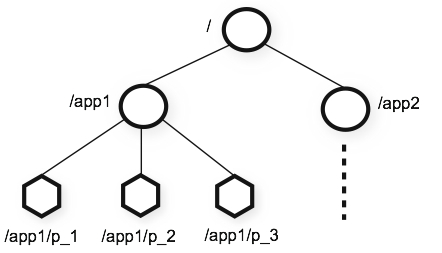
znodes maintain a stat which provides the metadata of a znode. It consists of version number, action control list (ACL), timestamp, and data length. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data, it also receives the version of the data.
Types of znodes: persistence, sequential, and ephemeral.
Persistence znode − Persistence znode is alive even after the client which created that particular znode is disconnected.
Ephemeral znode − Ephemeral znodes are active until the client is alive. When a client gets disconnected from the ZooKeeper ensemble, then the ephemeral znodes get deleted automatically. For this reason, only ephemeral znodes are not allowed to have children further.
Sequential - Sequential znodes can be either persistent or ephemeral. When a new znode is created as a sequential znode, Zookeeper sets the path of the znode by attaching a 10-digit sequence number to the original name.
Client
Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heartbeats. If the TCP connection to the server breaks, the client will automatically connect to a different server.
Clients maintain an in-memory image of state, along with transaction logs and snapshots in a persistent store.
Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol
As part of the agreement protocol, all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
When a client gets a handle to the ZooKeeper service, ZooKeeper creates a ZooKeeper session, represented as a 64-bit number, that it assigns to the client. If the client connects to a different ZooKeeper server, it will send the session id as a part of the connection handshake. Session expiration is managed by the ZooKeeper cluster itself, not by the client. Expirations happens when the cluster does not hear from the client within the specified session timeout period (heartbeat).
Watches
ZooKeeper supports the concept of watches. Clients can set a watch on a znode. A watch will be triggered and removed when the znode changes. When a watch is triggered, the client receives a packet saying that the znode has changed.
Group Membership
Another function directly provided by Zookeeper is group membership. The group is represented by a node. Members of the group create ephemeral nodes under the group node. Nodes of the members that fail abnormally will be removed automatically when Zookeeper detects the failure.
APIs
Zookeeper provides simple APIs to create, delete and check the existence of a node, get children of a node, get and set data, and sync (waits for data to be propagated).
When the server starts up, it knows which server it is by looking for the file myid in the data directory. That file has the contains the server number, in ASCII.
Peers use the port 2888 to connect to other peers and leader. Port 3888 is used for leader election.
Queue
To implement a distributed queue in ZooKeeper, first designate a znode to hold the queue, the queue node. The distributed clients put something into the queue by calling create() with a pathname ending in "queue-", with the sequence and ephemeral flags in the create() call set to true. Because the sequence flag is set, the new pathnames will have the form _path-to-queue-node_/queue-X, where X is a monotonic increasing number.
A client that wants to be removed from the queue calls ZooKeeper's getChildren( ) function, with watch set to true on the queue node, and begins processing nodes with the lowest number. The client does not need to issue another getChildren( ) until it exhausts the list obtained from the first getChildren( ) call. If there are are no children in the queue node, the reader waits for a watch notification to check the queue again.
Barriers
Distributed systems use barriers to block processing of a set of nodes until a condition is met. Barriers are implemented in ZooKeeper by designating a barrier node. The barrier is in place if the barrier node exists
a. Client calls the ZooKeeper API's exists() function on the barrier node, with watch set to true.
b. If exists() returns false, the barrier is gone and the client proceeds
c. Else, if exists() returns true, the clients wait for a watch event from ZooKeeper for the barrier node.
d. When the watch event is triggered, the client reissues the exists( ) call, again waiting until the barrier node is removed.
Locks
Distributed locks that are globally synchronous, meaning at any snapshot in time no two clients think they hold the same lock.
First, define a lock node. Lock protocol: Call create( ) with a pathname of "_locknode_/lock-" and the sequence and ephemeral flags set. Call getChildren( ) on the lock node without setting the watch flag.
If the path name created in step 1 has the lowest sequence number suffix, the client has the lock and the client exits the protocol.
The client calls exists( ) with the watch flag set on the path in the lock directory with the next lowest sequence number. If exists( ) returns false, go to step 2. Otherwise, wait for a notification for the path name from the previous step before going to step 2.
The unlock protocol is very simple: clients wishing to release a lock simply delete the node they created in step 1.
Leader Election
All the nodes create a sequential, ephemeral znode with the same path, /app/leader_election/guid_.ZooKeeper ensemble will append the 10-digit sequence number to the path and the znode created will be /app/leader_election/guid_0000000001, etc.
For a given instance, the node which creates the smallest number in the znode becomes the leader and all the other nodes are followers.
Each follower node watches the znode having the next smallest number. For example, the node which creates znode /app/leader_election/guid_0000000008 will watch the znode /app/leader_election/guid_0000000007, etc.
If the leader goes down, then its corresponding znode /app/leader_electionN gets deleted.
The next in line follower node will get the notification through watcher about the leader removal.
The next in line follower node will check if there are other znodes with the smallest number. If none, then it will assume the role of the leader. Otherwise, it finds the node which created the znode with the smallest number as leader.
Similarly, all other follower nodes elect the node which created the znode with the smallest number as leader.
Opinions expressed by DZone contributors are their own.
Comments