Are Traditional Data Warehouses Being Devoured by Agentic AI?
DSS systems are designed around the logic of human decision-making as the ultimate consumer. However, in Agentic AI era, the final "consumer" is likelier to be an agent.
Join the DZone community and get the full member experience.
Join For FreeFrom a technical architecture perspective, I believe this wave of AI will profoundly reshape the entire software ecosystem. DSS systems are designed around the logic of human decision-making as the ultimate consumer. However, with the advent of the Agentic AI era, the final "consumer" is more likely to be an agent. This will lead to a complete redesign—or even elimination—of traditional data warehouses and complex ETL pipelines. Conventional data warehouses emphasize structure and query patterns, but they will be replaced by Agentic Data Stack architectures that focus on semantics and response patterns.
Introduction: The Signal Behind Snowflake’s CEO Change
In the spring of 2024, Snowflake, a star in the cloud data warehouse space, announced a change in leadership: Sridhar Ramaswamy, former head of Google’s advertising business, succeeded the legendary CEO Frank Slootman, who had helped Snowflake reach a $60 billion valuation.
If you think this is just a routine executive shuffle, you're not seeing the full picture. The real implication is that the paradigm of the data warehouse world is undergoing a quiet yet profound transformation.
Technological evolution is never linear—it's about leaps. From OLTP databases to MPP data warehouses, from localized MPP computing to vectorized cloud data engines, each stage represents a leap to the next generation of technology—and from one dominant product to the next.
Slootman represented the "golden age of data warehousing." He bet on cloud-native, multi-tenant architectures and positioned Snowflake as the central hub of the next-generation data platform. Under his leadership, Snowflake directly disrupted my first employer—Teradata, the former data warehouse giant—which saw its market value plummet from $ 10.2 billion to just $2 billion.
As he stepped down, the keywords on Snowflake’s official blog shifted to: AI-first, agent-driven, and semantically-oriented data architecture.
This is no coincidence—it’s a sign of the times.
At the same time, the most forward-thinking VCs in Silicon Valley are betting on a new concept: “Agentic AI.” In this new paradigm, AI is no longer just a model—it’s an agent that can perceive, act, set goals, and collaborate.
So here’s the question:
When AI is no longer just a “chat tool” but a smart agent capable of sensing business changes, understanding intentions, and executing actions—can traditional data warehouses, designed for humans, still meet the needs of agents?
Data warehouses, once considered vital enterprise “data assets,” are now at risk of becoming mere “data material libraries” for agents. Even the term “material” is losing value, because an Agentic Data Stack can directly access raw data and feed it to upper-layer Sales Agents, Risk Agents, and others in a semantic + data format. Meanwhile, the redundant, non-semantic data in traditional warehouses is left for BI tools and data engineers to consume.
The real danger isn't just being eliminated—it's that you're still operating by the old rules while the world has already flipped the script.
This isn’t about disparaging data warehouses—it's about the recurring cycles of tech history. Just as Hadoop and Iceberg once reshaped the data lake landscape, Agentic AI is now rewriting the enterprise big data architecture.
1970–2024: The Evolution of Data Warehouse Architectures
1970: The Father of Data Warehousing, Bill Inmon
Bill Inmon, the “Father of Data Warehousing,” was the first to propose the concept of an EDW (Enterprise Data Warehouse) as a “subject-oriented, integrated, time-variant, and non-volatile collection of data,” laying the foundation for enterprise data architecture over the next half-century.
I was fortunate to study and participate in the translation of the first edition of Building the Data Warehouse more than 20 years ago during my time at Peking University under the guidance of Professor Tang Shiwei. This book's descriptions of subject areas, data layering architecture, and slowly changing dimensions (historical tables) have endured from the last century to today, becoming foundational concepts for data warehousing.
1983: Teradata Is Born: MPP Architecture Takes the Stage
In 1983, Teradata Corp. was founded—the company that dominated enterprise data warehouse infrastructure for the next 30 years. This was also my first job after graduation. Teradata was the first to introduce the MPP (Massively Parallel Processing) architecture into data systems. With its tightly integrated software and hardware and Bynet-based MPP design, Teradata significantly outperformed Oracle and DB2 in massive data processing and complex SQL queries.
When I joined Teradata, it was still a department under NCR, and my business card looked like this.

1996: Kimball Proposes the “Snowflake Schema”; OLAP Engines Emerge
Following Bill Inmon, Ralph Kimball introduced the concept of the “data mart” and redefined data modeling with the star schema and snowflake schema. For the next several decades, data architects continuously debated whether to build a centralized data warehouse or separate data marts first. “Dimensional modeling” and the “snowflake schema” became calling cards for data engineers.
At the BI layer, MOLAP engines like Hyperion Essbase and Cognos began to emerge. OLAP technology finally had a systematic methodology to follow.
Decades later, a new generation of data warehouse companies even adopted “Snowflake” as their brand name, inspired by the snowflake schema.
2013: The Big Data Boom – Hadoop Takes the World by Storm
With the release of Apache Hadoop in 2006, enterprises began widely adopting big data systems with low storage costs. In Big Data: A Revolution That Will Transform How We Live, Work, and Think, Viktor Mayer-Schönberger defined big data with the “4Vs”: Volume, Velocity, Variety, and Value.
Photo from 2015: The author William Guo with Viktor Mayer-Schönberger

This marked the beginning of a massive wave of big data platform construction. Over the next 10 years, a new generation of big data technologies emerged—Apache Hadoop, Hive, Spark, Kafka, DolphinScheduler, SeaTunnel, Iceberg, and more. Big data platforms began to shake the dominance of traditional data warehouses. In fact, after 2015, most Chinese enterprises dealing with petabyte-scale data storage no longer used traditional MPP data warehouse architectures. Instead, they built their platforms using Hadoop or Iceberg-based big data/data lake architectures.
2015: Snowflake Bursts Onto the Scene, the Modern Data Stack Rises
With the rise of the cloud and the release of Marcin Zukowski's paper on “vectorized” engines, Snowflake emerged with a cloud-native architecture that separated compute and storage, completely disrupting traditional data warehouse thinking. For the first time, BI engineers could enjoy elastic scaling “on demand” without worrying about cluster scheduling or resource allocation.
Snowflake turned the “data warehouse” into the “data cloud.” It led to the rise of an entirely new generation of data warehouse technology stacks. Tools like Fivetran, Dagster, Airbyte, DBT, and WhaleStudio followed, giving rise to the Modern Data Stack trend in Silicon Valley. Indeed, the previous generation of ETL and data engineering tools—Informatica, Talend, DataStage—originated in the 1980s. The rise of new technologies required a completely new ecosystem.
Overall, throughout the past decades, whether it was traditional data warehouses, big data platforms, cloud data warehouses, or data lakes, their architectures all essentially followed the structure shown in the diagram below:

In the Inmon era, this architecture was called a DSS system (Decision Support System). As the name suggests, the “support” was always intended for humans. The entire data warehouse tech stack was designed for human users.
The architecture of the data warehouse was also designed for data engineers. That’s why we had multiple subject areas, atomic layers, aggregation layers, and metrics layers—to assist ETL engineers in development. BI tools also needed to define star and snowflake schemas, with drag-and-drop interfaces for reports and dashboards. All the consumers were human.
But in the era of large-model agents, all of this is about to change dramatically.
Are Agents Devouring Traditional Data Warehouses?!
At the end of 2022, OpenAI released ChatGPT, kicking off the era of large language models.
Since 2023, Llama, Claude, Gemini, GPT-4o, DeepSeek… many LLMs have rapidly evolved. AI is no longer just a language model, but a “general intelligence engine” capable of understanding and making decisions for complex tasks.
In 2024, RAG (Retrieval-Augmented Generation) technology went mainstream. Tools like LlamaIndex, LangChain, and Dify gained widespread adoption. AI began integrating enterprise domain knowledge, becoming a truly “knowledgeable assistant.”
By 2025, the Agent architecture will have fully risen. Technologies and protocols like AutoGPT, Function Calling, and the MCP protocol have emerged. AI is no longer just a chat tool—it now has perception, planning, and execution capabilities, becoming a “digital employee.”
In the data domain, the arrival of large models has also brought major disruption. Have you used ChatGPT’s Data Analyst? If so, you were likely amazed by its performance. It can help a business user generate a detailed analytical report from a dataset from multiple perspectives. It can practically replace a junior data analyst. At various layers, many "automation" tools have also emerged, such as ChatBI and TXT2SQL, each leveraging large models and agents to automate or semi-automate data warehouse development processes.
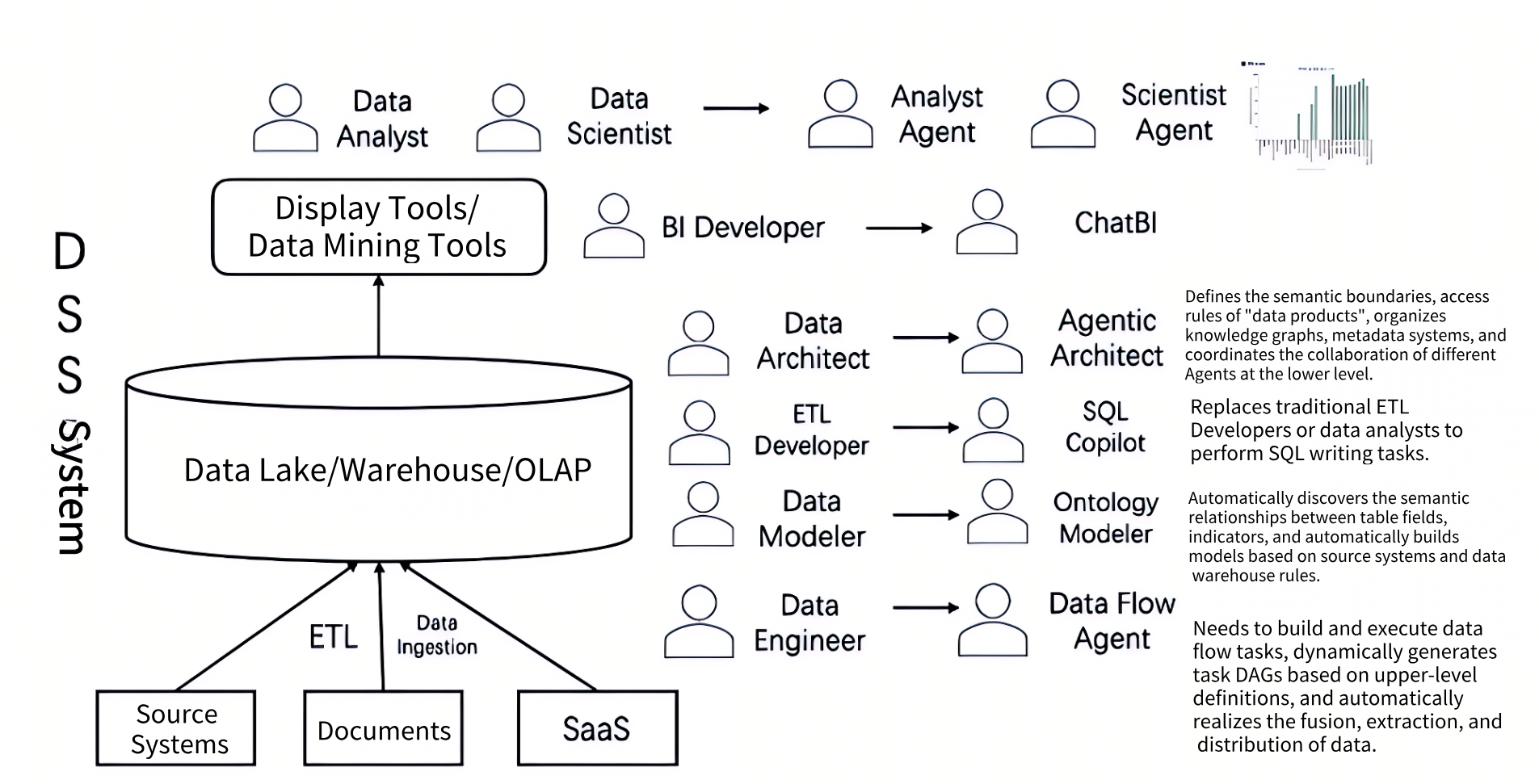
In the future, more and more agents will emerge—not just in data analysis, but also in ad campaign optimization, customer service, and risk management. These agents will gradually liberate business personnel by replacing their interactions with systems.
Ultimately, AI will no longer be a “passive answering tool,” but an “intelligent agent proactively achieving goals.”
For the past 20+ years, the “users” of data platforms have typically been data engineers, analysts, and BI professionals.
In the next 20 years, every role—from analyst to supply chain operator—may be redefined by Agents:
- Marketers will have a Campaign Agent that automatically integrates multi-channel data, optimizes placements, and generates copy;
- Customer service reps will have a Support Agent that’s more than a chatbot—it will be a context-aware assistant with knowledge graphs and memory;
- The supply chain team will have a Procurement Agent that parses orders, tracks delivery timelines, fetches ERP data, and auto-replenishes inventory;
- Legal teams will have a Compliance Agent, HR will have a Hiring Agent, and even the board of directors could have a Board Agent…
The SQL you used to write every day, the reports you compiled, and the ops meetings you attended are all becoming Agent-triggered actions, semantic commands, and automated responses.

But a pressing reality follows:
If the end users of data are Agents, and even data warehouse development is done by Agents—and the ultimate decision-makers using data are Agents rather than “humans”—does the original DSS (Decision Support System) data warehouse architecture still make sense?
Anyone who’s studied software engineering knows the first diagram you draw when designing a system is the “Use Case” diagram—it defines the system’s users, boundaries, and behavior scenarios.
When the user of a data warehouse shifts from human to Agent, the DSS architecture envisioned by Bill Inmon no longer holds water. At least in my view, it doesn’t.
When the user changes, the software must change, too.
The rise of Agents isn’t just a win for large models—it’s a complete disruption of how we perceive the user experience:
- Traditional data systems operated in a “pull model”: the user knew the problem, queried the data, and extracted conclusions.
- Future Agents operate in a “push model”: the system proactively senses changes, understands intent, and generates decision suggestions.
It’s like moving from traditional maps to GPS navigation:
You no longer need to know “where the road is”—you simply tell the system where you want to go, and it takes you there.
Traditional data warehouses focus on structure and querying, whereas Agentic architectures prioritize semantics and responsiveness.
Put simply: whoever understands business language will rule the data world.
Agentic Data Stack and Contextual Data Unit (CDU): Data With Built-In Semantics
For Agents to develop and use data automatically, today’s data warehouse design is not suitable—it was never meant for large models or Agents. What’s stored inside are “raw” data—just numerical values and column names. What these values or fields mean is stored in a separate “data asset” management system. Understanding each value or field requires a full-fledged “data governance” project. This design is unfriendly to large models and Agents, which rely on semantic reasoning. So, if we were to redesign a data storage system for Agents and large models, we’d have to store data and semantics together. I call this:
Contextual Data Unit (CDU): a dual-element unit combining data + semantic explanation—every data entry carries its meaning with it.
It fuses the information traditionally stored in data catalogs directly into each data entry, reducing lookup time and error rate when Agents or large models access it.
Meanwhile, the semantics in CDU are derived from business systems—they’re distilled and abstracted by Data Flow Agents at the source. The CDU is formed during ingestion, flowing into an Agentic Data Lake—not generated afterward. In other words, data governance and lineage are embedded in the agent-driven development process itself, not retroactively applied after data has entered the warehouse, avoiding conflict and ambiguity.
At this point, you should understand my thinking: in the era of Agentic AI, everything from ETL to storage to data application will be reshaped because the consumers are now Agents and models. To serve these intelligent agents, traditional data platforms must evolve into an Agent-callable, semantically-aware, event-driven architecture—what we call the Agentic Data Stack.
Agentic Data Stack: in the Agent era, a new data tech stack that spans from tools to obtain “data + semantics,” to platforms that compute and store CDU-format data, and finally to the interaction layer that delivers this data to Agents.
Here’s my bold prediction of what the Agentic Data Stack might include:
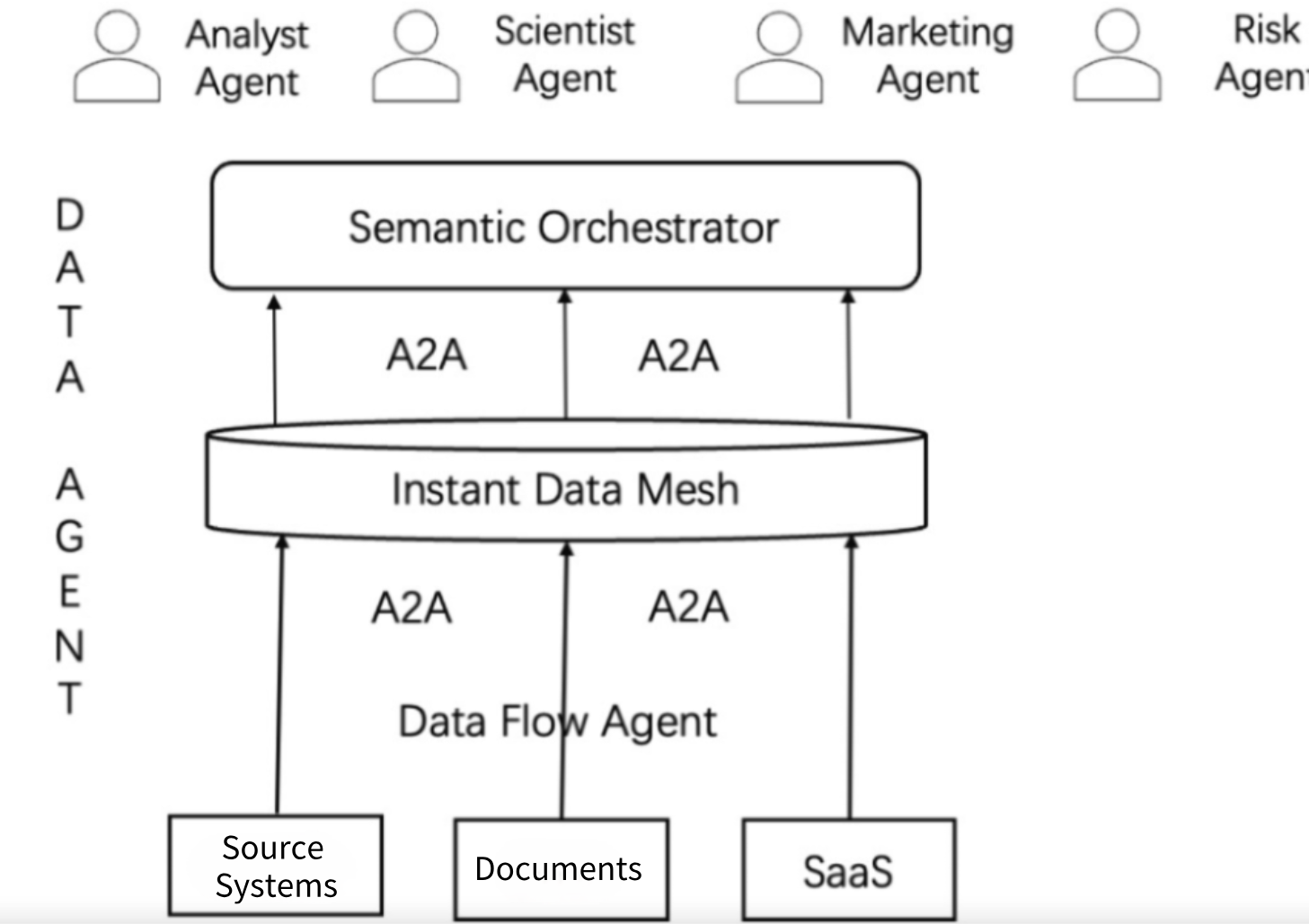
- Semantic Orchestrator (Interaction Layer): This is no longer a BI/dashboard interface, but the “brain” and “command center” of the Agentic architecture. With natural language understanding and semantic reasoning capabilities, it bridges other agents with underlying data assets, enabling intelligent, multi-round interactions and service generation.
- Data Mesh (Storage Layer): No longer a traditional Data Warehouse or Data Lake—it’s a service-oriented, computation-friendly fusion layer that stores data with semantics. It can supply data for complex computations by LLMs while also supporting real-time processing.
- Data Flow Agent (Processing Layer): Not just “moving data,” but understanding and orchestrating data. Not scheduled periodically, but event-driven and intent-driven. Capable of detecting data changes, analyzing schemas, understanding business logic, and responding accordingly.
In the Agentic AI era, the cycle of building data platforms will drastically shrink. New data is discovered by Data Flow Agents, pre-stored in the Data Mesh, and interpreted by the Semantic Orchestrator with business-aligned definitions—ultimately enabling “instant computation” from business demand to data output.
LLMs provide the brainpower. Agents are the hands and feet. Agentic Data Stack gives them the data accessibility needed in the era of large models.
With the rise of the Agentic Data Stack, the cost of building next-gen “data warehouses” drops dramatically. Having natural-language query capabilities and access to relevant data won’t just be the privilege of big enterprises—it will become accessible to small businesses and even individuals. You can capture your Google Drive files, home NAS, PDFs on your laptop, and app orders from your phone into your personal data store via a Data Flow Agent. Then ask a question like “How much did I spend visiting Disney last month?”—something that previously required exporting from multiple platforms and manually building Excel sheets. Even more complex queries like “Find my insurance contract from 5 years ago” become doable.
And this isn’t fantasy. Recently, under the leadership of WhaleOps, the Apache SeaTunnel community released Apache SeaTunnel MCP Server—already moving toward becoming a Data Flow Agent. Of course, there are still technical hurdles to overcome—like the immature A2A protocols, unproven semantic+data storage models in the Data Mesh layer, and the transformation of legacy governance outputs into inputs for the Semantic Orchestrator.
But the arrival of the LLM and Agent era will reshape the data analytics industry just as the invention of SQL once did.
It’s never your “visible” competitor who beats you. A story: When I was a kid, two popular bike brands were Forever and Phoenix. They competed over speed via “accelerated axles.” But what disrupted the bike market wasn’t a better bike—it was a food delivery company launching shared bikes, flipping the entire industry. As Agents rise, some core product paths we once believed in may lose meaning. While keeping your head down on execution, remember to look up at the sky.
Conclusion: Live in the Present, See the Future
When I shared this vision at AICon, AWS Community Day, and other tech summits, the audience always split into two camps. The “Believers” think I’m too conservative in saying Agentic Data Stack is 5–10 years away—they believe AI is evolving so fast that we’ll see it fully formed within 5 years. The “Skeptics” think the impact of AI Agents on data warehouse architecture is wildly exaggerated. They argue that today’s data warehouse designs are the highest-ROI format, and anything less efficient won’t scale commercially—it’s just a pie in the sky.
Personally, I’m a “centrist”: I believe the emergence of the Agentic Data Stack is inevitable. This wave of AI will impact software architecture in a way that’s fundamentally different from previous waves. We must look at the total cost and outcome of enterprise data warehouse construction and operations, not just storage or compute ROI alone.
Currently, we see trends: the rise of real-time data warehouses, the expansion of data lakes, and the reduction of layers in modern warehouse design. (I’d even argue that now that our generation of Teradata-trained data modeling architects is retiring, the market lacks professionals who can keep up with fast-evolving business logic). So traditional modeling itself is iterating—real-time warehouses now often use 2 layers instead of 3–4. I’m simply pointing out a bigger leap ahead in the Agentic AI era. On balance, the ROI of Agentic Data Stack will likely surpass that of the current Modern Data Stack.
It’s not AI that replaces you—it’s the person who knows how to use AI. It’s not that data warehouses are being devoured, but rather their structure-and-query-centric model is being replaced by a semantics-and-response-centric architecture. Just like how once you’ve used GPS, you won’t go back to a paper map.
The gates to the Agentic Data Stack are opening.
Are you ready?
Published at DZone with permission of William Guo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments