How to Instantly Improve Your Java Logging With 7 Logback Tweaks
Join the DZone community and get the full member experience.
Join For Free

the benchmark tests to help you discover how logback performs under pressure
first benchmark: what’s the cost of synchronous log files?
first we took a look at the difference between synchronous and asynchronous logging. both writing to a single log file, the fileappender writes entries directly to file while the asyncappender feeds them to a queue which is then written to file. the default queue size is 256, and when it’s 80% full it stops letting in new entries of lower levels (except warn and error).
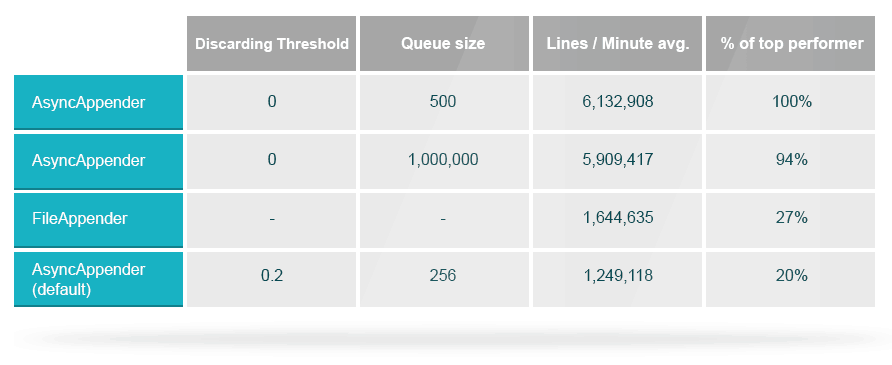
the table compares between the fileappender and different queue sizes for the asyncappender. async came on top with the 500 queue size.
- tweak #1: asyncappender can be 3.7x faster than the synchronous fileappender. actually, it’s the fastest way to log across all appenders.
- tweak #2: the default asyncappender can cause a 5 fold performance cut and even lose messages. make sure to customize the queue size and discardingthreshold according to your needs.
<appender name="async500" class="ch.qos.logback.classic.asyncappender"> <queuesize>500</queuesize> <discardingthreshold>0</discardingthreshold> <appender-ref ref="file" /> </appender>
second benchmark: do message patterns really make a difference?
now we want to see the effect of log entry patterns on the speed of writing. to make this fair we kept the log line’s length equal (200 characters) even when using different patterns. the default logback entry includes the date, thread, level, logger name and message, by playing with it we tried to see what the effects on performance might be.

this benchmark demonstrates and helps see up close the benefit of logger naming conventions. just remember to change its name accordingly to the class you use it in.
- tweak #3: naming the logger by class name provides 3x performance boost.
- tweak #4: compared to the default pattern, using only the level and message fields provided 127k more entries per minute.
third benchmark: dear prudence, won’t you come out to play?
in prudent mode a single log file can be accessed from multiple jvms. this of course takes a hit on performance because of the need to handle another lock. we tested prudent mode on 2 jvms writing to a single file using the same benchmark we ran earlier.

prudent mode takes a hit as expected, although my first guess was that the impact would be a stronger.
- tweak #5: use prudent mode only when you absolutely need it to avoid a throughput decrease.
<appender name="file_prudent" class="ch.qos.logback.core.fileappender"> <file>logs/test.log</file> <prudent>true</prudent> </appender>
fourth benchmark: how to speed up synchronous logging?
let’s see how synchronous appenders other than the fileappender perform. the consoleappender writes to system.out or system.err (defaults to system.out) and of course can also be piped to a file. that’s how we we’re able to count the results. the socketappender writes to a specified network resource over a tcp socket. if the target is offline, the message is dropped. otherwise, it’s received as if it was generated locally. for the benchmark, the socket was was sending data to the same machine so we avoided network issues and concerns.

to our surprise, explicit file access through fileappender is more expensive than writing to console and piping it to a file. the same result, a different approach, and some 200k more log entries per minute. socketappender performed similarly to fileappender in spite of adding serialization in between, the network resource if existed would have beared most of the overhead.
- tweak #6: piping consoleappender to a file provided 13% higher throughput than using fileappender.
fifth benchmark: now can we kick it up a notch?
another useful method we have in our toolbelt is the siftingappender. sifting allows to break the log to multiple files. our logic here was to create 4 separate logs, each holding the logs of 2 or 3 out of the 10 threads we run in the test. this is done by indicating a discriminator, in our case, logid, which determines the file name of the logs:<appender name="sift" class="ch.qos.logback.classic.sift.siftingappender">
<discriminator>
<key>logid</key>
<defaultvalue>unknown</defaultvalue>
</discriminator>
<sift>
<appender name="file-${logid}" class="ch.qos.logback.core.fileappender">
<file>logs/sift-${logid}.log</file>
<append>false</append>
</appender>
</sift>
</appender>
** configuring a siftingappender

once again our fileappender takes a beat down. the more output targets, the less stress on the locks and fewer context switching. the main bottleneck in logging, same as with the async example, proves to be synchronising a file.
- tweak #7: using a siftingappender can allow a 3.1x improvement in throughput.
conclusion
we found that the way to achieve the highest throughput is by using a customized asyncappender. if you must use synchronous logging, it’s better to sift through the results and use multiple files by some logic. i hope you’ve found the insights from the logback benchmark useful and look forward to hear your thoughts at the comments below.Opinions expressed by DZone contributors are their own.
Comments