How Nebula Graph Stores a One Trillion Connections Social Network: The Practices at WeChat
In this article, take a look at how Nebula graph stores a one trillion connections social network.
Join the DZone community and get the full member experience.
Join For FreeWeChat is one of the social network apps in the world that deals with large scale heterogeneous graphs. The dataset to be processed has:
- One trillion edges/connections
- A total dataset of 150TB
- An hourly update of 100 billion connections,
And it is a huge challenge. The team at WeChat encountered problems when using Nebula Graph, an open source distributed graph database.
However, through deep customization capabilities in the database, the team has realized some useful on-demand features. They include big data storage, data import for large data sets with a fast performance, version control, rollback at the second level, and access to the database at millisecond level.
The Challenges Facing Large Internet Companies
Most well-known graph databases are not capable of dealing with truly big data. For example, the community version of Neo4j provides single-host service and is widely adopted in the knowledge graph area. However, when it comes to a very large data set this solution misses the mark. And large data sets are increasingly common in today’s business world.
Plus, there are issues like data consistency and disaster recovery to consider if you choose a multi-copy implementation. Janus Graph has solved the big data storage problem by using external metadata management, kv storage and indexes. Yet the performance has been widely criticized. As a result, most graph database solutions that the WeChat team evaluated are many times better than Janus Graph in terms of performance.
Some Internet companies build their own databases. These self-developed solutions are catering to their own business requirements, rather than for general graph scenarios. So, they support only a limited proportion of query syntaxes.
GeaBase From Ant Financial
GeaBase is another option, mainly used in the finance industry. It features a self-developed query language, pushdown computation and millisecond latency. The main scenarios for its usage include risk management in financial organizations. To this end, it supports a transaction network with trillions of edges/relationships, storing real-time transaction data, real-time fraud detection.
It is also useful for recommendation engines. This includes applications like stocks and securities recommendations. Its Ant Forest features the capability to store trillions of nodes, strong data consistency, and low latency querying. It also has a GNN feature for Dynamic Graph CNN, for online inference based on dynamic graphs.
iGraph From Alibaba
There is also iGraph, a graph indexing and query system. It stores user behavior information and serves as one of the four backbone middle platforms in Alibaba. iGraph has adopted Gremlin as its graph query language for real-time queries of e-commerce relationships.
ByteGraph From ByteDance (a.k.a TikTok)
By adding a cache layer to the kv layer, ByteGraph splits the relationships into B+ trees for efficient access to edges and data sampling. The structure is like the TAO of Facebook.
Architecture of the WeChat Big Data Solution
The WeChat team has come up with the following architecture to solve the big data storage and processing problem.
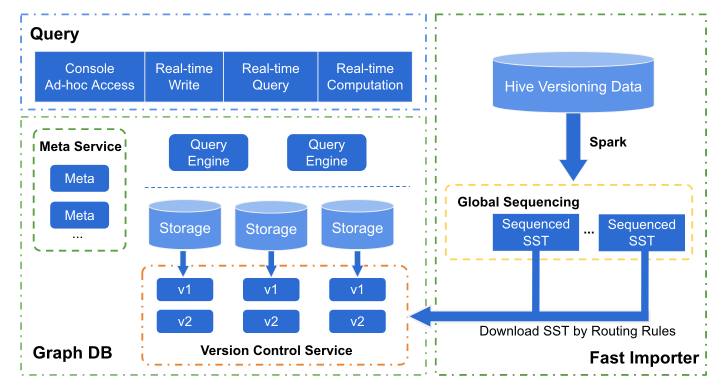
Why Nebula Graph?
As seen in the architecture above, a graph database is the main component of the solution. WeChat ended up selecting Nebula Graph as the starting point of its journey in exploring graph databases.
WeChat found Nebula Graph had the most potential for handling huge dataset storage needs based on the capability of dataset partitioning and an independent relationship storage. It also had pushdown computation and MPP optimization based on the strong consistency storage engine. Finally, the team had extensive experience in the graph database field and a proven model for abstraction for big data.
Problems in Practice Nebula Graph
Insufficient Memory
The WeChat team encountered memory issues. At its essence, it was a problem of performance versus resources. Memory occupation is an un-neglectable issue in an application dealing with large scale datasets. There are a couple of components in RocksDB that contribute to memory usage. There are Block cache, Indexes and bloom filters. There are also Memtables and Blocks pinned by iterators. So, the WeChat team moved to optimize memory utilization. It began with block cache optimization. To do this, it adopted a global LRU cache to control the cache occupation of all RocksDB instances in a machine.
Then the team did a bloom filter optimization. An edge is designed as a key-value pair and stored in RocksDB. If all keys are stored in a bloom filter and each key occupies 10bit, then the memory required by the entire filter will exceed the machine memory by a large margin.
The team observed that most of the time the requests are to acquire a list of edges for a specific node. Therefore, the team adopted a prefix bloom filter. Another optimization was made to create indexes for properties on vertices, which enables acceleration for most requests. Finally, the memory occupation of a single-host filter is at the gigabyte level without sacrificing the speed of most requests.
Version Control
There are several business requirements in practice for version control. It offers graph data fast rollback, periodic full data import, and automatic access to the latest versioning data. The team has classified data sources into two categories.
Recurring data, for example, generates a list of similar users by day and the data takes effect after being successfully imported. Then there is History data and real-time data. For example, there is refresh history data by day and the team combines the history data with real-time data as full data to be imported.
Following is the data storage model in RockDB.
Vertex Storage Model:

Edge Storage Model:

Timestamp is used as the versioning method for real-time data. The version of imported data is specified manually. In practice, the team has three options for version control. First, reverse_versions, where the list of versions is to be kept for rollback. Second is active_version, where the version is accessed by users’ requests. And finally, max_version, where data is reversed after a certain version. The reversed data is the combination of the history data and the real-time data.
Using the three options, the team can manage offline data and online data efficiently. The data that is no longer used is cleared from the disk during the next compaction. In this way, the application can update the data version without in the background. And the data rollback can be completed within seconds.
Below are some examples:
- Keep three versions of data and activate one of them
alter edge friend reserve_versions = 1 2 3 active_version = 1
- Data sources are history data and real-time write data
alter edge friend max_version = 1592147484
Fast Full Data Import
Conducting data imports at a large scale is a common practice. The import requests, without any optimization, would not only affect requests in production, but take longer than a day to complete. So, it became an urgent requirement to improve import speed. SST Ingest is a commonly adopted method to achieve fast import. The WeChat team adopted something similar.
The team generated SST files offline via scheduling Spark tasks. Storage nodes pull the data required and ingest the data to the graph database. And, then there is access to the latest versioning data via the version control request. The import process takes several hours to complete, which is fast. And it does not affect requests to the graph database because the computation is mainly offline.
Shared-Nothing
The shared-nothing architecture is a widely discussed method for ensuring horizontal scalability. It requires programming skills to implement the architecture in practice. The meta cache is encapsulated with shared_ptr and is frequently accessed, making it a warm bed for atomic operation clashing. To realize shared-nothing, the WeChat team copied each meta cache as a local thread. This pull request provides details.
It has been a long journey to achieve graph database utilization. And it is one that continues with success in large part by overcoming obstacles.
Published at DZone with permission of Jamie Liu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments