How Relevant Is Chaos Engineering Today?
Chaos Engineering involves core principles that guide the design and execution of experiments to assess the resilience of software systems.
Join the DZone community and get the full member experience.
Join For FreeThe rapid advancement of software systems, fuelled by the adoption of microservices and cloud architectures, has significantly increased complexity and unpredictability. As modern enterprises become more reliant on these distributed systems, the risk of unexpected failures and service disruptions has grown. In response to these challenges, a transformative approach has emerged called Chaos Engineering.
Chaos Engineering has gained momentum in software development, with its origins rooted in experiments by tech leaders like Netflix and Amazon. This practice involves deliberately introducing controlled disruptions into production systems to evaluate their resilience and uncover vulnerabilities. However, as software systems continue to evolve, the practice of Chaos Engineering is being reconsidered and refined.
The Emergence of Chaos Engineering
The origins of Chaos Engineering date back to the 1980s when Apple used a "monkey" program to simulate random events, helping identify memory issues in Macintosh systems. This concept later evolved as companies like Amazon and Google adopted similar techniques to enhance system reliability by simulating and addressing potential failures.
The breakthrough came in 2011 when Netflix formalized Chaos Engineering. By creating a tool called Chaos Monkey, Netflix randomly disabled servers during normal operations to ensure engineers-built redundancy and automation into the system. The success of Chaos Monkey led to the development of Netflix's Simian Army, a suite of tools designed to test various failure scenarios, such as network disruptions and database outages, thereby laying the foundation for modern Chaos Engineering.
Core Principles of Chaos Engineering
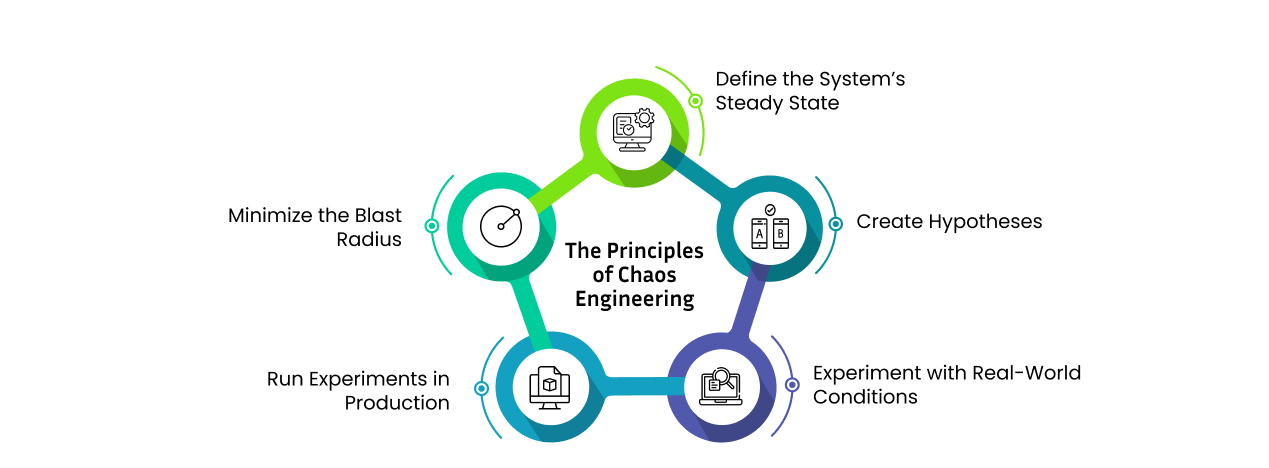
Chaos Engineering is grounded in a set of key principles that guide the planning and execution of experiments to evaluate software system resilience:
- Define the Steady State: The process begins by establishing a clear understanding of the system's normal behavior. This involves identifying measurable key performance indicators (KPIs) that act as a baseline for assessing deviations during experiments.
- Formulate Hypotheses: Once the steady state is defined, hypotheses are created to predict how the system should behave under specific failure scenarios. These predictions are then tested through controlled disruptions.
- Simulate Real-World Scenarios: Chaos experiments mimic real-world events such as hardware failures, network latency, or resource exhaustion. These simulations allow engineers to observe system responses and uncover weaknesses in a controlled environment.
- Conduct Experiments in Production: To ensure realistic results, experiments are carried out in the live production environment rather than in isolated testing setups, providing a true representation of system behavior under actual conditions.
- Limit the Blast Radius: Despite running tests in production, minimizing user impact is critical. Careful planning, executing experiments during off-peak times, and using backup systems ensure disruptions are contained and quickly recoverable.
Benefits of Chaos Engineering
Adopting Chaos Engineering provides organizations with several key advantages:
- Enhanced System Resilience and Reliability: By proactively uncovering and addressing vulnerabilities, Chaos Engineering strengthens critical software systems, ensuring they remain operational and reliable under stress.
- Mitigation of Financial Risks: Unanticipated outages can result in significant revenue losses and increased operational costs. Chaos Engineering minimizes these risks by helping organizations prevent disruptions.
- In-Depth System Insights: Chaos experiments offer a clearer understanding of complex system interactions and dependencies, enabling engineers to make more strategic decisions in system architecture and design.
- Accelerated Recovery from Failures: Organizations can refine incident response strategies by analyzing system behavior during various failure scenarios, reducing recovery times and improving operational efficiency.
- Enhanced Customer Experience: Robust, failure-resistant systems foster customer trust and satisfaction, as they deliver consistent and dependable services even in the face of unexpected challenges.
Challenges and Limitations
While chaos testing offers significant advantages, it also comes with notable limitations and considerations that organizations should carefully address:
- Impact on Production Systems: Introducing disruptions in a live production environment entails risks, including potential service outages or downtime. Thoughtful planning and risk mitigation are crucial to minimize the effects on users and operations.
- Complexity and Cost: Conducting chaos testing demands substantial resources, such as specialized tools, robust infrastructure, and skilled professionals. For smaller organizations with limited budgets or expertise, these requirements may pose significant barriers.
- Potential for Misinterpretation: Without proper analysis, test results can be misleading. A system’s response during a test may not always mirror its behavior in more complex or varied real-world scenarios. Results should be contextualized and validated through repeated testing.
- Limited Scope and Coverage: Chaos testing may not account for all possible failure scenarios, leaving certain vulnerabilities undetected. Supplementing it with other testing methods, like penetration and security testing, ensures broader coverage.
- Unpredictability of Outcomes: The inherent randomness of chaos testing makes it challenging to predict specific outcomes, which can hinder efforts to replicate scenarios or consistently validate fixes.
- Ethical and Regulatory Considerations: Deliberately inducing failures in systems handling sensitive data, critical infrastructure, or financial transactions raises ethical concerns. Compliance with regulations and safeguarding sensitive information is essential.
- Specialized Skill Requirements: Effective chaos testing requires expertise in distributed systems, fault injection, and system monitoring. Organizations may need to invest in training or hiring skilled professionals to maximize the benefits.
- Integration with CI/CD Pipelines: Incorporating chaos tests into continuous integration and deployment workflows is complex and demands careful orchestration to avoid disrupting pipelines or delaying releases.
- Metrics and Measurement Challenges: Defining and accurately measuring metrics that reflect system resilience under stress can be difficult. Metrics must be carefully chosen to yield actionable insights.
- Organizational Readiness: Successful adoption of chaos testing depends on a culture that views failure as a learning opportunity. This requires collaboration across teams (developers, operations, security) and a commitment to continuous improvement in system reliability.
Beyond Chaos: Designing for Resilience
A cornerstone of the modern approach to software development is embedding resilience directly into system design rather than relying solely on Chaos Engineering to identify and address vulnerabilities. This involves incorporating features like redundancy, fault tolerance, and self-healing mechanisms from the outset, ensuring systems can endure and recover from failures with minimal disruption to users.
By adopting this proactive strategy, organizations can minimize the reliance on disruptive Chaos Engineering experiments and prioritize building systems that are inherently robust and scalable. This approach aligns with the growing focus on non-functional requirements such as security, maintainability, and performance, which are often overshadowed by the drive for rapid feature delivery.
Observability and Continuous Improvement
Modern software development also emphasizes observability with real-time monitoring tools that provide insights into system performance. By integrating observability into development workflows, organizations can identify potential issues early and drive continuous improvement, refining system resilience over time.
Empowering Developers: Shifting Left
The evolution of Chaos Engineering includes a "shift left" approach, empowering developers to build resilient systems from the start. By equipping developers with tools like Steadybit, organizations enable them to incorporate resilience practices such as retries, circuit breakers, and rolling updates directly into their code. This democratization of Chaos Engineering distributes responsibility for system reliability across the development team, reducing dependency on dedicated Site Reliability Engineering (SRE) teams.
The Future of Chaos Engineering
As the software industry evolves, Chaos Engineering is poised to become an integral part of a broader strategy for building resilient systems. Rather than existing as an isolated practice, it will increasingly be recognized as one of many techniques within a comprehensive Resilience Engineering framework.
This approach will seamlessly combine proactive system design, enhanced observability, continuous improvement, and empowering developers to build reliability into their work. By embracing this holistic perspective, organizations can create software that is not only highly available and scalable but also adaptive, self-healing, and capable of withstanding the unpredictable challenges of today’s digital landscape.
Conclusion
In conclusion, the role of Chaos Engineering in today’s software landscape is evolving significantly. While it has been instrumental in enhancing system resilience, the industry is shifting towards a more proactive, design-focused approach to building robust systems. By embedding resilience into software design, harnessing observability, promoting continuous improvement, and empowering developers to prioritize reliability, organizations can create systems that are not only scalable and highly available but also adaptive, self-healing, and equipped to handle the uncertainties of the digital world.
As software development continues to advance, Chaos Engineering will increasingly integrate with Resilience Engineering to form a unified strategy aimed at delivering reliable, high-performance, and user-focused digital solutions. Adopting this comprehensive approach enables organizations to future-proof their software and sustain a competitive advantage in the rapidly changing technological landscape.
Opinions expressed by DZone contributors are their own.
Comments