How to Design a Better Decision Tree With Pruning
A decision tree is a supervised machine learning algorithm that is used for classification and regression problems. Let's see how to design one with Pruning.
Join the DZone community and get the full member experience.
Join For FreeDecision tree (DT) analysis is a general and predictive modeling tool for machine learning. It is one of the simplest and most useful structures for machine learning. As the name indicates, DTs are trees of decisions. By using an algorithm approach for splitting data sets according to different conditions, decision trees are constructed. A decision tree is one of the commonly used and functional techniques for supervised learning.
But before moving on to designing decision trees with pruning, let’s understand its true concept.
Understanding Decision Trees
A decision tree is a supervised machine learning algorithm that is used for classification and regression problems. Decision trees follow a set of nested if-else statement conditions to make predictions. And as decision trees are used for classification and regression, the algorithm that is used to grow them is called CART (Classification and Regression Trees). And there is not only one but multiple algorithms proposed to build decision trees. Decision trees aim to create a model that predicts the target variable’s value by learning simple decision rules inferred from the data features.
Each node of a decision tree represents a decision.
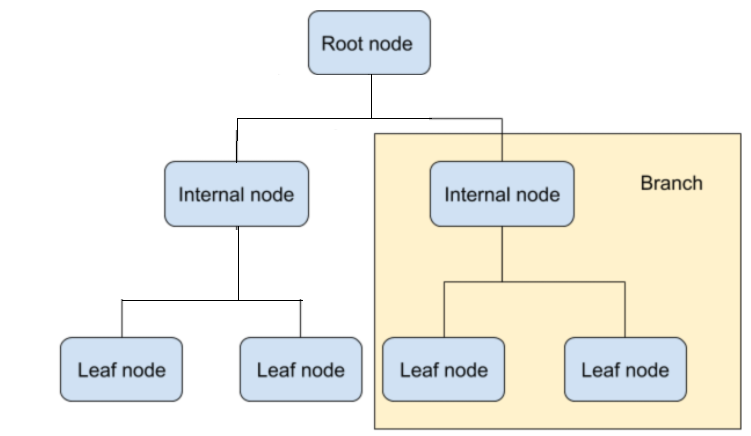
In the above diagram, the root node is the beginning of the decision tree graph with zero depth. Then there are child/internal nodes where binary decisions are taken. And finally, there are leaf nodes, where predictions of a category are made.
The algorithm that helps to build a decision tree aims to predict a target variable from the variables and their attributes. The structure of the decision tree is made through binary splits series from the root node through branches. To reach the leaf node in the decision tree, you have to pass multiple internal nodes to check the predictions made.
Assumptions While Building Decision Trees
Some of the assumptions that you have to make while working with decision trees are:
- The whole training set is root.
- It is preferable to have categorical feature values. Discrete values are used before building a decision tree model.
- The attribute values are used to recursively distribute records.
- Statistical approaches are used to determine which attributes should be placed as root or internal nodes of the tree.
The Sum of Product (SOP) or Disjunctive Normal Form representation is used in decision trees.
Each branch in a class, from the root to the leaf node of the tree having the different branches ending forms a disjunction (sum), same class forms conjunction (product) of the values.
Why Decision Tree?
A decision tree follows the same process as a human follows when making a decision in real life, making it simpler to understand. It is crucial for solving decision-making problems in machine learning. The reason why it is so commonly used to train an ML model is that decision trees help to think about all the possible outcomes of a problem. Moreover, there is less requirement for data cleaning in comparison to other algorithms.
But, the decision tree also has its limitations, which is Overfitting.
Overfitting in Decision Trees
Overfitting is a significant practical difficulty in decision trees. A decision tree will always overfit the training data if it is allowed to grow to its max depth. Overfitting occurs in a decision tree when the tree is designed to fit all samples in the training data set perfectly. As a result, decision trees end up with branches with strict sparse data rules and this affects the accuracy of prediction by working with samples that are not part of the training set. The deeper the tree grows, the more complex the decision rule sequence becomes. Assigning the maximum depth is the easiest way to simplify a tree and handle overfitting.
But how to improve our tree model in a more precise way? Let’s find out!
How To Prevent Overfitting in Decision Trees with Pruning?
Pruning is a technique used to remove overfitting in Decision trees. It simplifies the decision tree by eliminating the weakest rule. It can be further divided into:
- Pre-pruning refers to stopping the tree at an early stage by limiting the growth of the tree through setting constraints. To do that, we can set parameters like min_samples_split, min_samples_leaf, or max_depth using Hyperparameter tuning.
- Post-pruning or Backward pruning is used after the decision tree is built. It is used when the decision tree has become extremely in-depth and shows model overfitting. To do that, we will control the decision tree branches like max_samples_split and max_depth through cost-complexity pruning.
Pruning starts with an unpruned tree. Then it takes the subtree sequence and selects the best one via cross-validation.
It’s important that pruning ensures that the subtree is optimal, i.e., it has higher accuracy, and the optimal subtree search is computationally tractable. Hence, pruning should not only reduce overfitting but also make the decision tree less complex, easier to understand, and efficient to explain than the unpruned decision tree while maintaining its performance.
Takeaway
Now we know that decision trees belong to supervised machine learning algorithms. In contrast to other algorithms of supervised learning, decision trees can also be used to solve classification and regression problems.
Decision trees are used to build models for predicting variable values or classes based on simple decision rules derived from previous training data. Another takeaway point of this blog is pruning. Pruning helps decision trees to make precise decisions while reducing their complexity and setting constraints.
Opinions expressed by DZone contributors are their own.
Comments