When To Use Decision Trees vs. Random Forests in Machine Learning
This article covers the ideas behind decision trees and random forest algorithms, comparing the two and their benefits.
Join the DZone community and get the full member experience.
Join For FreeThe development of sophisticated algorithms has Completely changed how data is handled and choices are made. With so much online data, efficient interpretation and decision-making tools have become essential. Choosing the best option can be difficult, though, because so many options are accessible. The ideas behind decision trees and random forest algorithms will be covered in this blog, along with comparing the two. We will also look at the benefits of random forests versus choice trees.
A decision tree is a model that divides the data recursively according to the values of its features to forecast a target variable using a tree-like structure. To produce an exact tree that is simple to understand and helpful for making decisions, the algorithm chooses the features that offer the most significant information gain or the best split.
Multiple decision trees are combined in Random Forest, an ensemble learning method, to increase accuracy and decrease overfitting. First, it creates several decision trees, each trained on a collection of arbitrarily chosen features and samples. Then it combines the predictions from all the trees to arrive at a final prediction. Random forests are frequently used for classification and regression tasks, mainly when working with high-dimensional datasets containing many features. They make the model more robust and decrease variance.
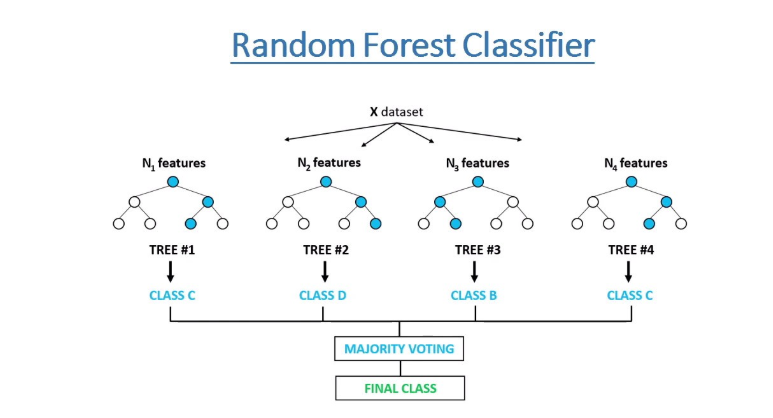
Figure 1: Random Forests
Importance of Understanding When to Use Each Algorithm
When interpretability is crucial, the dataset is tiny, the features are categorical or numerical, there are missing values, and you need a straightforward and quick model, decision trees are a good option.
When dealing with an extensive, high-dimensional dataset with numerous features, attempting to reduce overfitting and obtain more accurate predictions, and confronting a classification or regression issue, Random Forest is an appropriate solution.
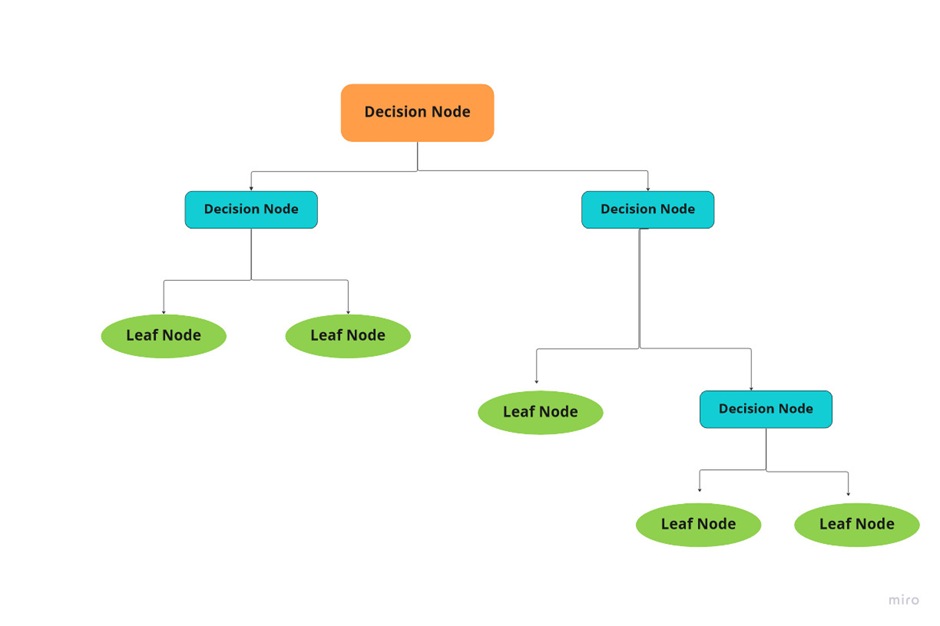
Figure 2: Decision Tree
When To Use Decision Trees
- When it matters to be interpretable.
- When the collection is modest.
- When the characteristics are in number or categorical.
- When there are blank numbers in the dataset.
- When you require a fast and basic model
When To Use Random Forests
- When a big, multidimensional dataset.
- When a dataset contains many characteristics.
- When attempting to lessen overfitting.
- When you require a more precise model.
- When a categorization or regression issue arises.
Comparison of Decision Trees vs. Random Forests
Because they require fewer computational resources to construct and make predictions, Decision Trees are quicker than Random Forests. They help develop simple models and exploratory data analysis because they are also reasonably simple to interpret. However, decision trees are prone to overfitting data and being impacted by anomalies.
Random Forests, on the other hand, are ensemble models that combine various Decision Trees; as a result, they are more difficult to understand but less prone to overfitting and outliers. They take longer to build the model and require more computational resources, but they typically outperform Decision Trees in terms of accuracy, particularly for large, complex datasets with numerous features.
While Random Forests struggle with linear data patterns, Decision Trees are better adapted. Implementing Decision Trees is simple, whereas building Random Forests takes longer based on the size of the dataset. It is simple to visualize Decision Trees but more challenging to visualize Random Forests.
|
Random Forest |
Decision tree |
Computation |
Computationally intensive |
Computationally very effective |
Interpretability |
Hard to interpret |
Easy to interpret |
Accuracy |
Highly accurate |
Accuracy varies |
Overfitting |
Less likely to overfit data |
highly likely overfit to data |
Outliers |
Not affected by outliers |
Affected by outliers |
Differences in Algorithm Approach in Decision Trees and Random Forest
Decision Trees and Random Forests are guided machine learning algorithms, but their methods for creating models are different. Until a stopping criterion is satisfied, Decision Trees recursively divide the dataset into smaller groups based on the feature that maximizes information gain or the best-split criterion. Then, it is possible to make forecasts using the resulting tree structure. In contrast, Random Forests combine numerous Decision Trees trained on randomly sampled subsets of the data and a randomly selected subset of features. It is known as an ensemble approach. Finally, the predictions from all the trees are combined to produce the end prediction, lowering the possibility of overfitting and enhancing performance.
Advantages and Disadvantages of Each Algorithm
Decision Tree Algorithm Advantages
- Straightforward procedure
- Both number and categorical data can be handled.
- The more evidence, the better the outcome.
- Speed
- Can come up with principles that make sense.
- It possesses the capacity to conduct classification without requiring a lot of computation.
- Clearly identifies the most critical areas for categorization or prediction.
Decision Tree Algorithm Disadvantages
- Maybe overfit
- Big pruning procedure
- Unguaranteed optimization
- Intricate computations
- High Deflection
- It can be less suitable for estimation tasks, particularly when determining the value of a continuous attribute is the end goal.
- Are more vulnerable to mistakes in categorization issues.
- Training may be computationally costly.
Random Forest Algorithm Advantages
- Strong and very precise.
- Not necessary to normalize.
- Can run trees in parallel.
- Manage multiple features at once.
- Can carry out both classification and regression assignments.
- Produces accurate predictions that are simple to comprehend.
Random Forest Algorithm Disadvantages
- They favor particular characteristics. Sometimes.
- Slow: The random forest algorithm can become relatively slow and inefficient for real-time predictions due to the existence of a large number of trees, which is one of its main drawbacks.
- Not suitable for use with linear techniques.
- For extensive dimensional data, worse.
- It would be better to choose alternative techniques since the random forest is a predictive modeling tool rather than a descriptive one, particularly if you're trying to describe the relationships in your data.
When Should You Choose Which Algorithm to Use Between the Decision Tree and Random Forest?
Consider the dataset's size and complexity, the models' interpretability and performance, and the risk of overfitting when choosing between Decision Trees and Random Forests for a supervised learning assignment. While Random Forests are better for complex problems with many features and higher accuracy requirements, Decision Trees are better for smaller datasets with fewer features and simple interpretability. Furthermore, overfitting is less likely to occur due to the ensemble structure of Random Forests.
Conclusion
In conclusion, the choice between Decision Trees and Random Forests in machine learning relies on the size and complexity of the dataset, interpretability, performance, and concerns about overfitting. While Random Forests are better for complex issues with many features and high accuracy requirements, Decision Trees are better for smaller datasets and more straightforward problems. When deciding between the two, the project's unique requirements and objectives must be thoroughly considered.
Opinions expressed by DZone contributors are their own.
Comments