How to Design Event Streams, Part 3
This article covers the relationship of event definitions to the streams themselves. One event type per stream or multiple event types per stream?
Join the DZone community and get the full member experience.
Join For FreeSee previous Part 1 and Part 2.
The relationship between your event definitions and the event streams themselves is a major design. One of the most common questions I get is, “Is it okay to put multiple event types in one stream? Or should we publish each event type to its own stream?”
This article explores the factors that contribute to answering these questions and offers a set of recommendations that should help you find the best answer for your own use cases.
Example Consumer Use Cases
- General alerting of state changes (deltas)
- Processing sequences of events (deltas)
- Transferring state (facts)
- Mixing facts and deltas
The consumer’s use case should be a top consideration when deciding how to structure your event streams. Event streams are replayable sources of data that are written only once, but that can be read many times by many different consumers.
We want to make it as easy as possible for them to use the data according to their own needs.
Use Case: General Alerting of Changes
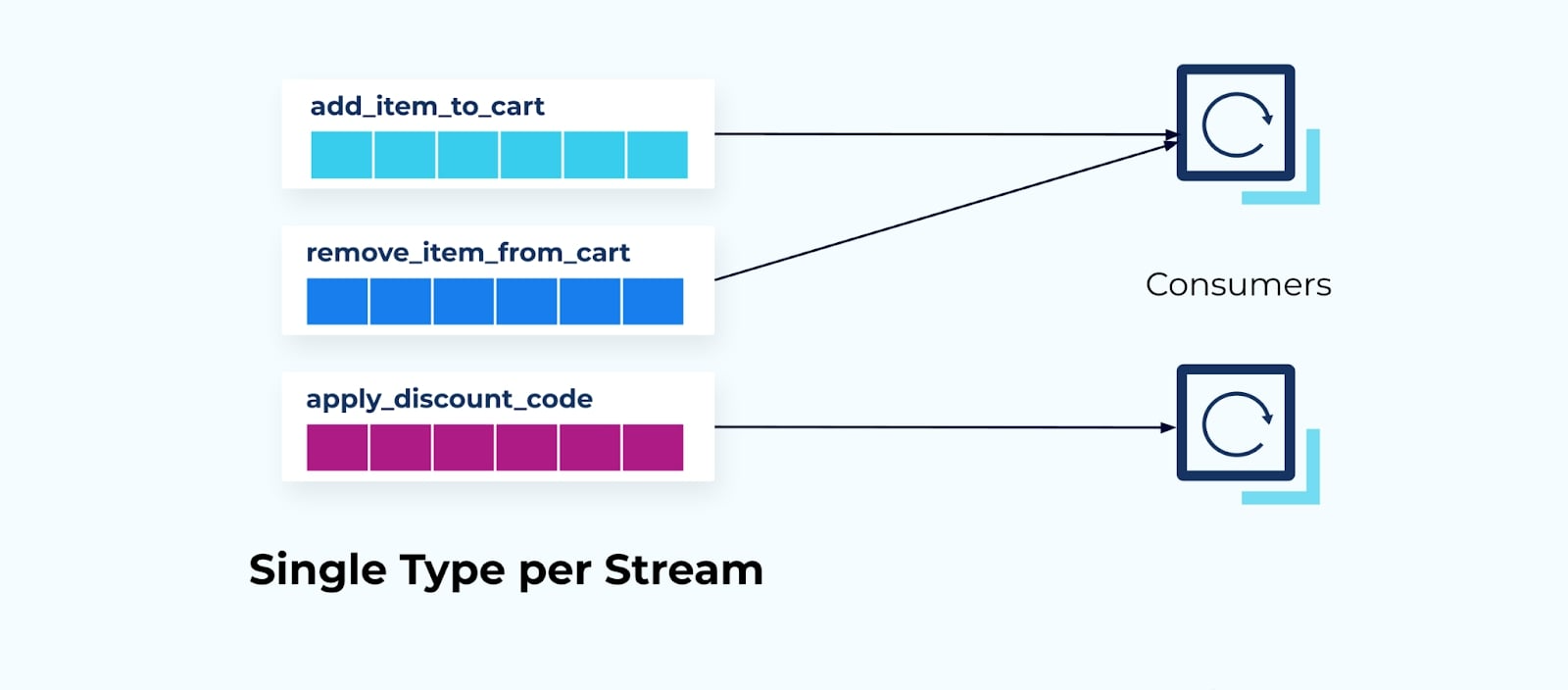
Deltas work very well for the general change alerting. Applications can respond to the delta events exposed from inside of an application. Splitting up events so that there is only one type per stream provides a high granularity and permits consumer applications to subscribe to only the deltas they care about.
Use Case: Processing Sequences of Delta Events
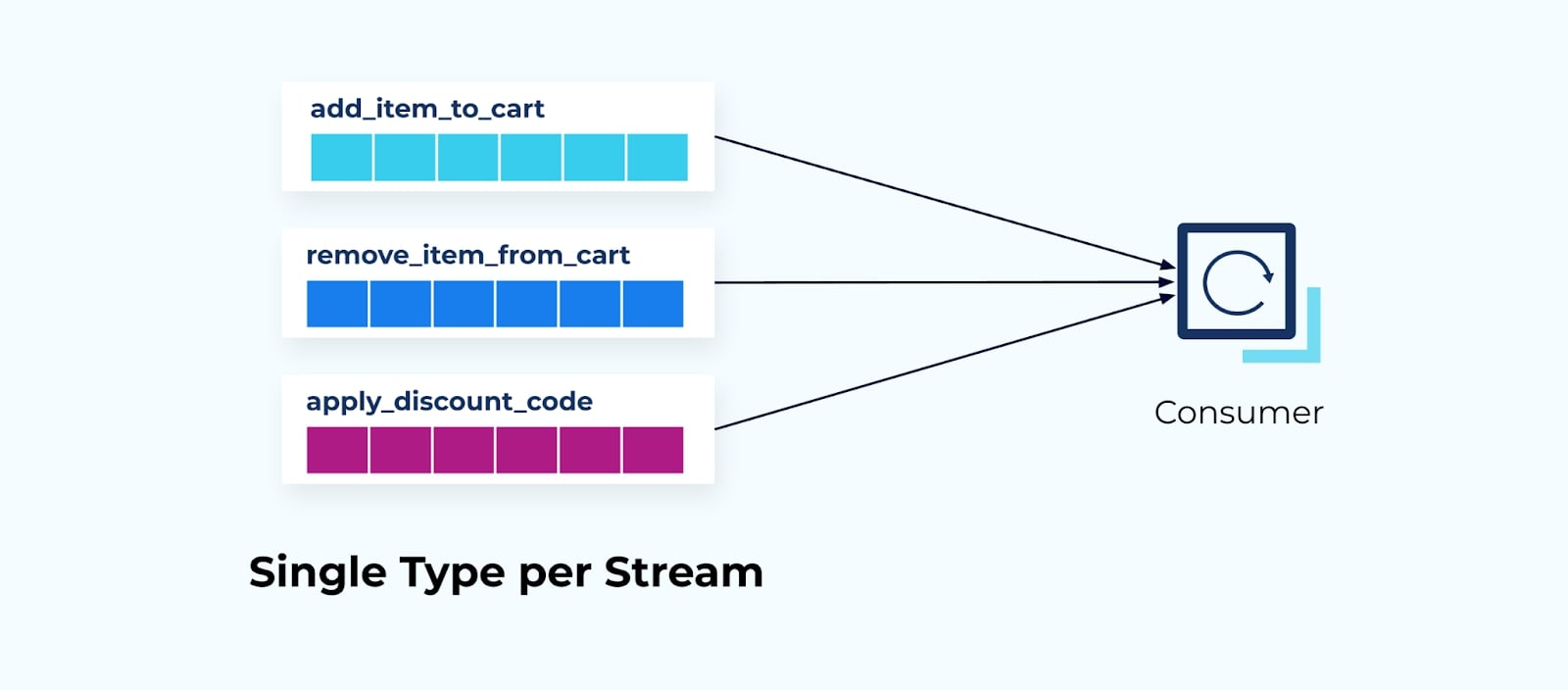
But what if a single application needs to read several deltas, and the ordering between events is very important? Following a one-event per stream strategy introduces the risk that events may be read and processed out of order, giving inconsistent sequencing results.
Stream processors, like Kafka Streams and Flink, typically contain logic to process events in both ascending timestamp and offset order, a process that I call “event scheduling.” For example, Kafka Streams uses a best-effort algorithm to select the next record to process, while Flink uses a Watermarking strategy to process records based on timestamps. Be warned that not all stream processing frameworks support event scheduling, leading to wildly diverging processing orders based on race condition outcomes.
At the end of the day, even event scheduling is a best-effort attempt. Out-of-order processing may still occur due to intermittent failures of the application or hardware, as well as unresolved corner cases and race conditions in the frameworks themselves.
Note that this is not nearly as dire as it seems. Many (if not the vast majority) of streaming use cases aren’t that sensitive to processing order between topics. For those that are sensitive, Watermarking and event scheduling tend to work pretty well in the majority of cases. And for those event sequences that need perfectly strict ordering? Well, read on.
What About Strict Ordering?
But what do you do if you need something with stronger guarantees? A precise and strict ordering of events may be a significant factor for your business use case.
In this case, you may be better off putting all of your events into a single event stream so that your consumer receives them in the same order as they are written. You also need a consistent partitioning strategy to ensure that all events of the same key go to the same partition, as Kafka only guarantees order on a per-partition basis.
Note that this technique is not about reducing the number of topics you’re using — topics are relatively cheap, and you should choose to build your topics based on the data they’re carrying and the purposes they’re meant to serve — not to simply cut down on topic count. Apache Kafka is perfectly capable of handling thousands of topics without any problem.
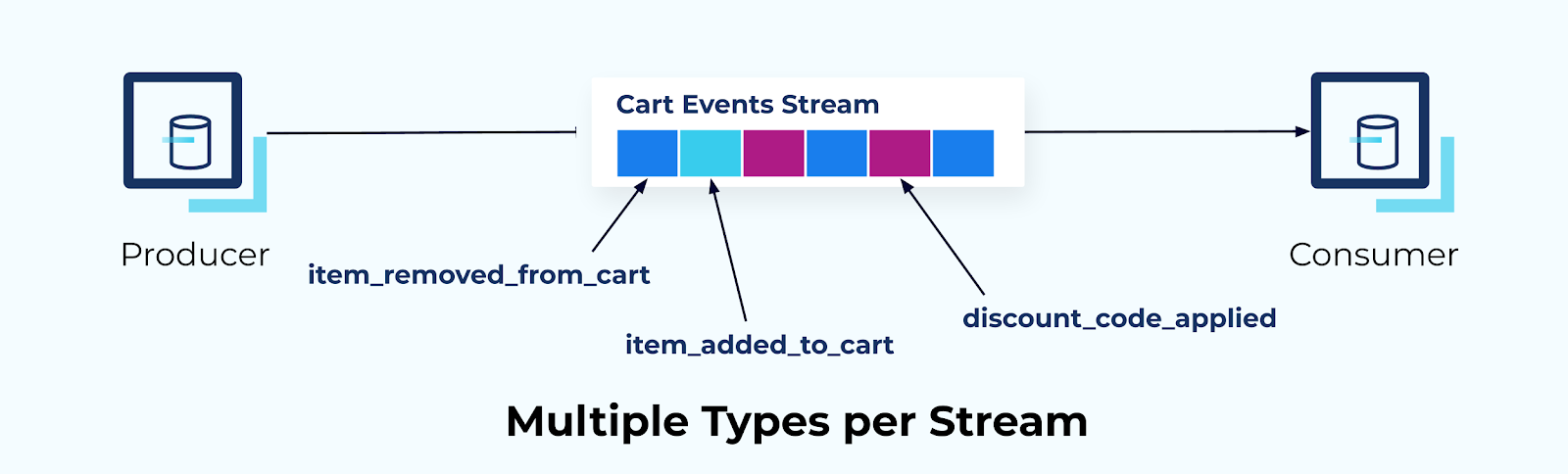
Single Stream, Multiple Delta Types

Putting related event types into a single topic partition provides a strict incremental order for consumer processing, but it requires that all events be written by a single producer, as it needs strict control over the ordering of events.
In this example, we have merged all of the adds, removes, and discount codes for the shopping cart into a single partition of a single event stream.
Use Case: Processing Sequences of Delta Events
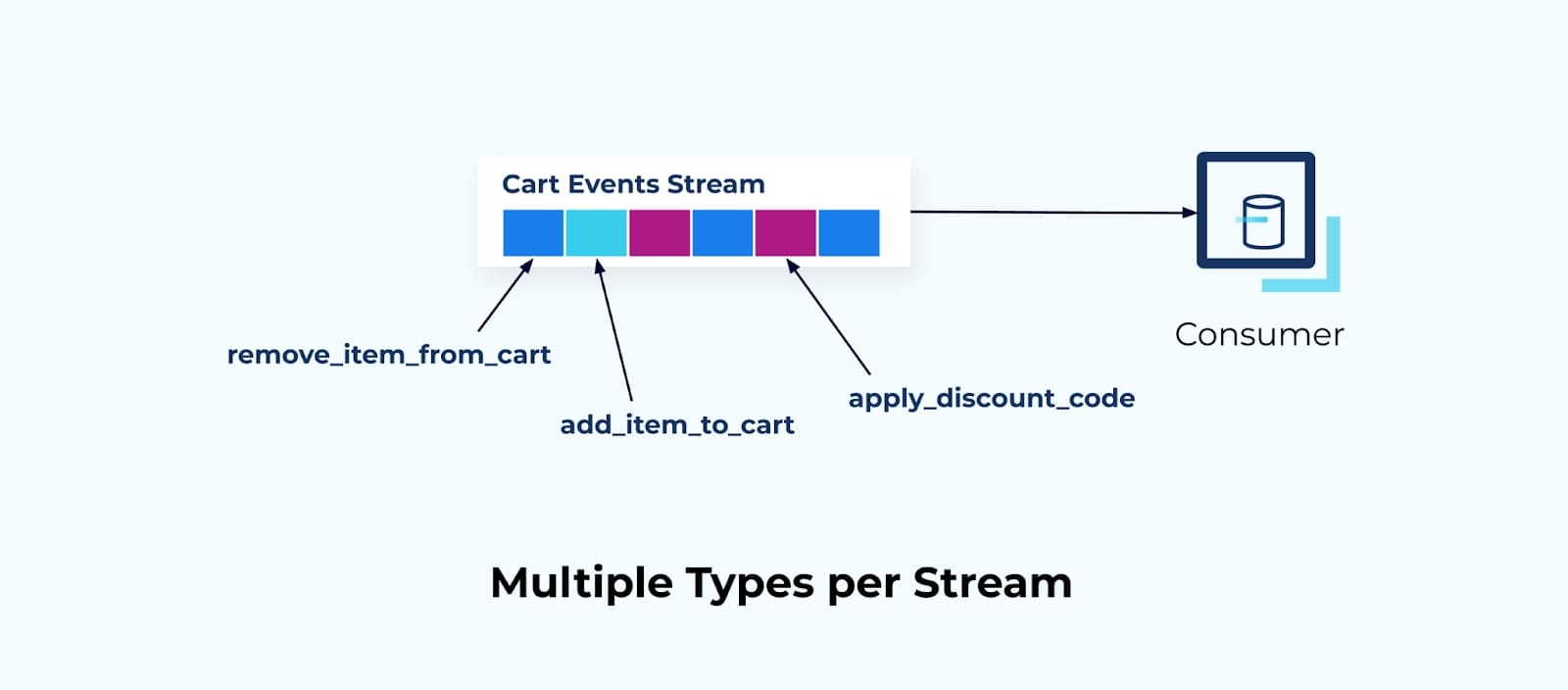
Zooming back out, you can see a single consumer coupled with this stream of events. They must be able to understand and interpret each of the types in the stream. It’s important not to turn your topic into a dumping ground for multiple event types and expect your consumers to simply figure it out. Rather, the consumer must know how to process each delta type, and any new types or changes to existing types would need to be negotiated between the application owners.
Use Flink SQL to Split Stream Up
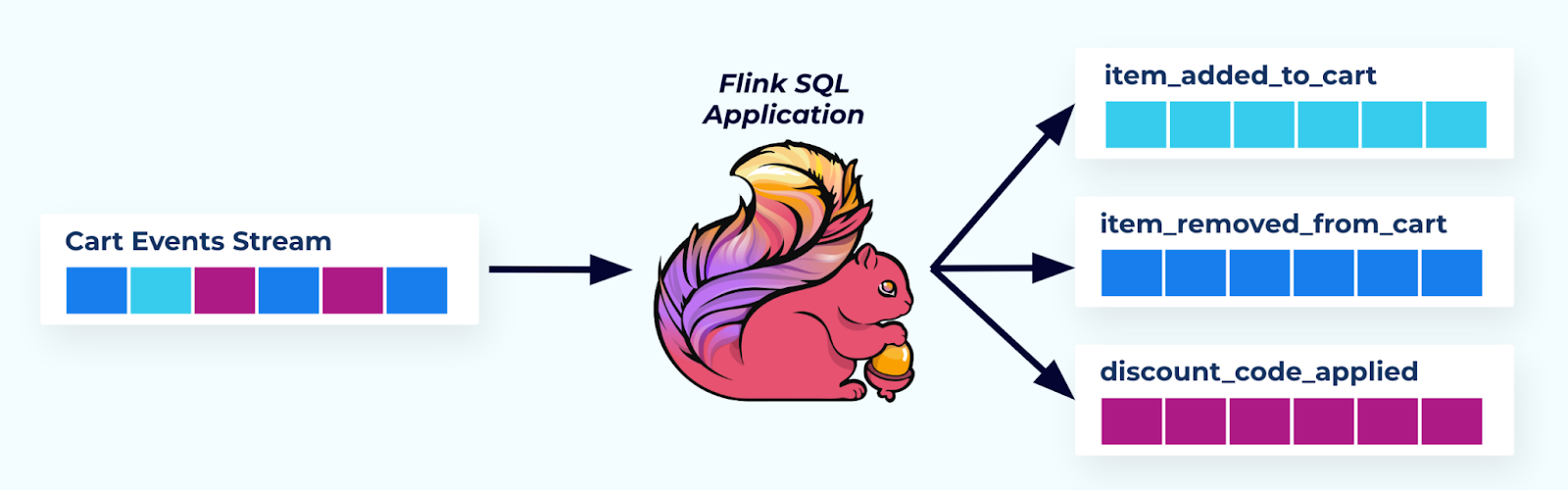
You can also use a stream processor like Flink to split the single cart events stream up into an event stream per delta, writing each event to a new topic. Consumers can choose to subscribe to these purpose-built delta streams, or they can subscribe to the original stream and simply filter out events they do not care about.
Word of Caution
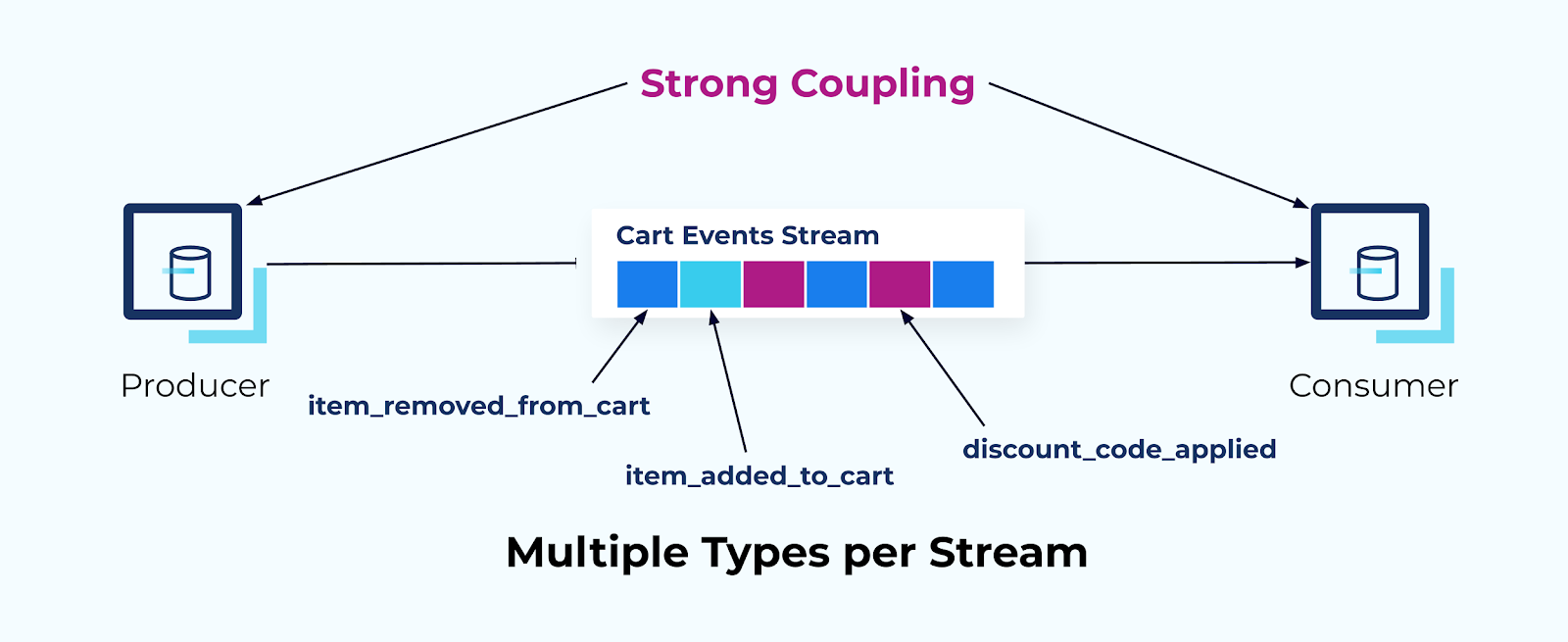
A word of caution, however. This pattern can result in a very strong coupling between the producer and the consumer service. Usually, it is only suitable for applications that are intended to be strongly coupled, such as a pair of systems using event sourcing, and not for general-purpose usage. You should also ask yourself if these two applications merit separation or if they should be redesigned into a single application.
Use Case: Transferring State with Facts
Facts provide a capability known as Event-Carried State Transfer. Each event provides a complete view of the state of a particular entity at a particular point in time.
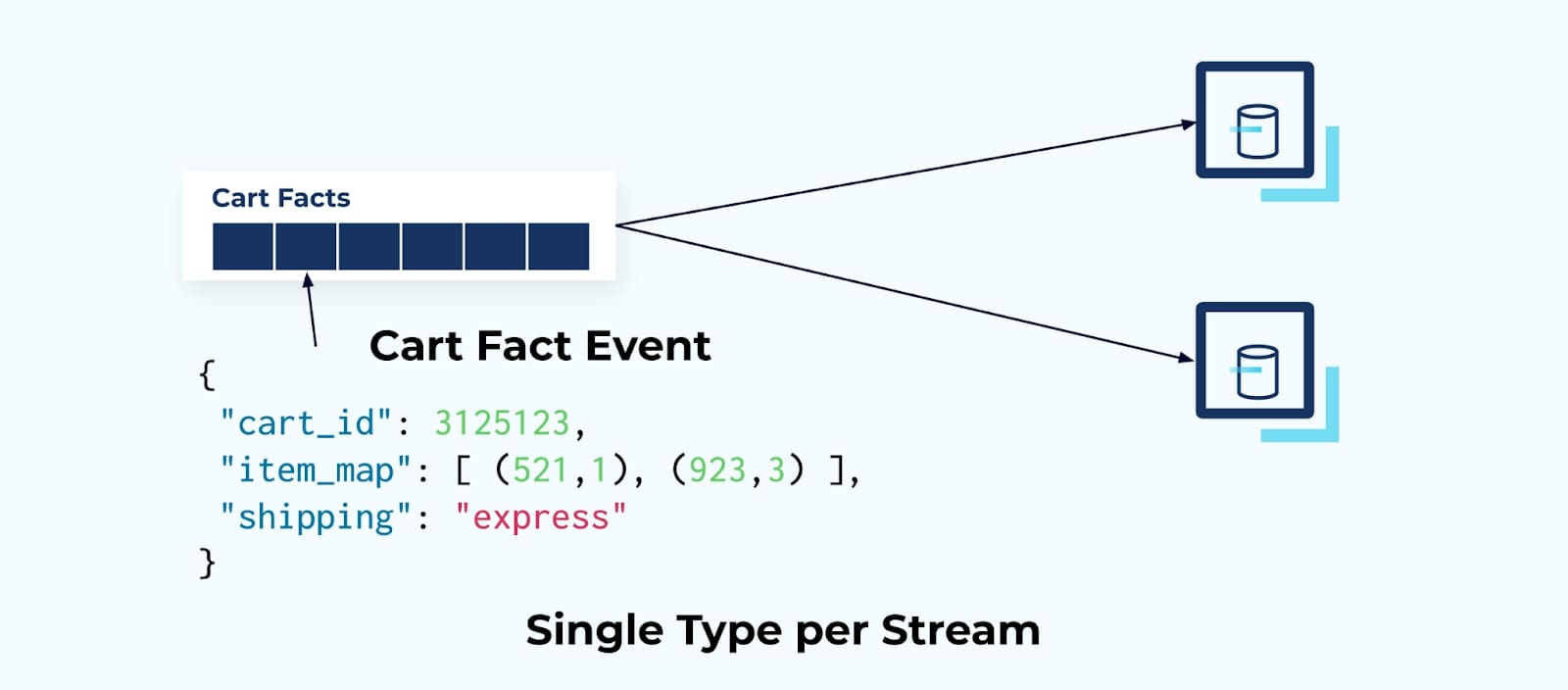
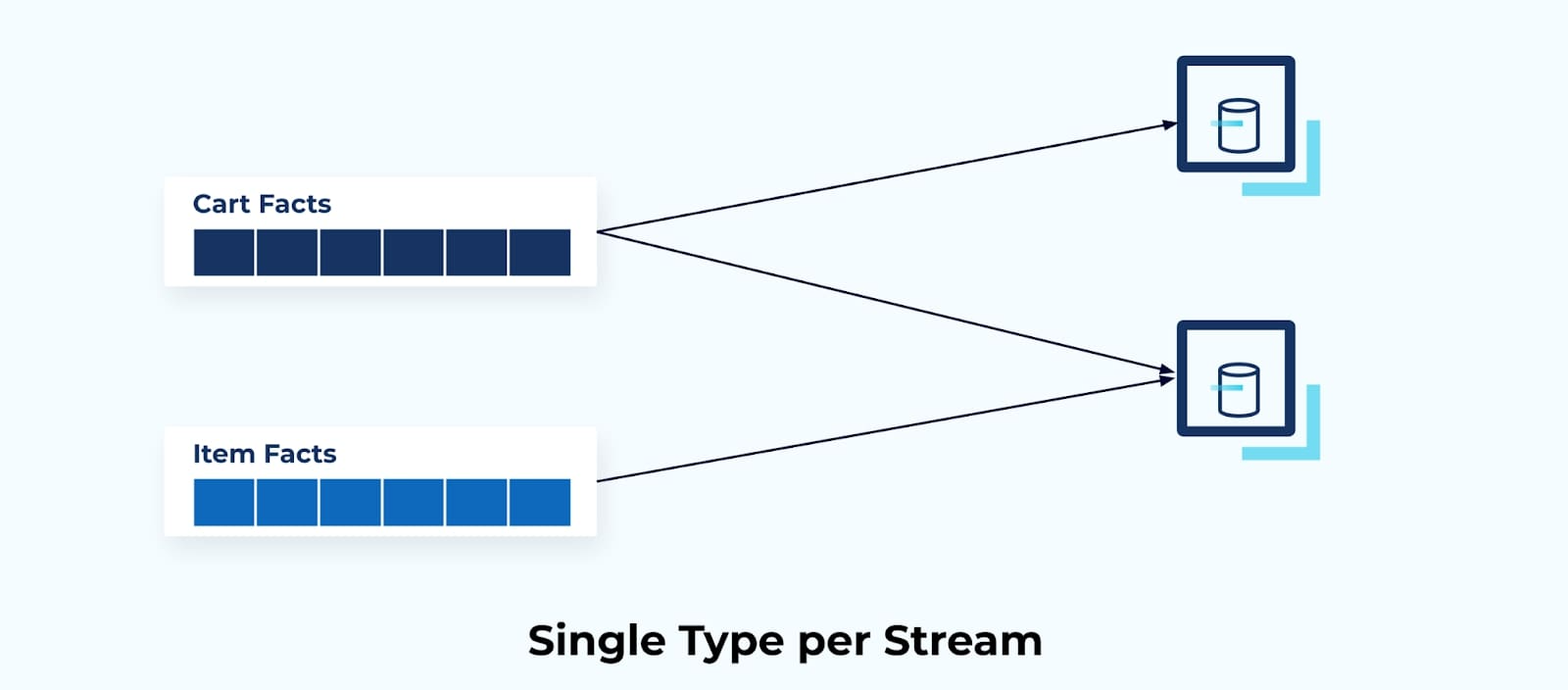
Fact events present a much better option for transferring state, do not require the consumer to interpret a sequence of events, and offer a much looser coupling option. In this case, only a single event type is used per event stream — there is no mixing of facts from various streams.
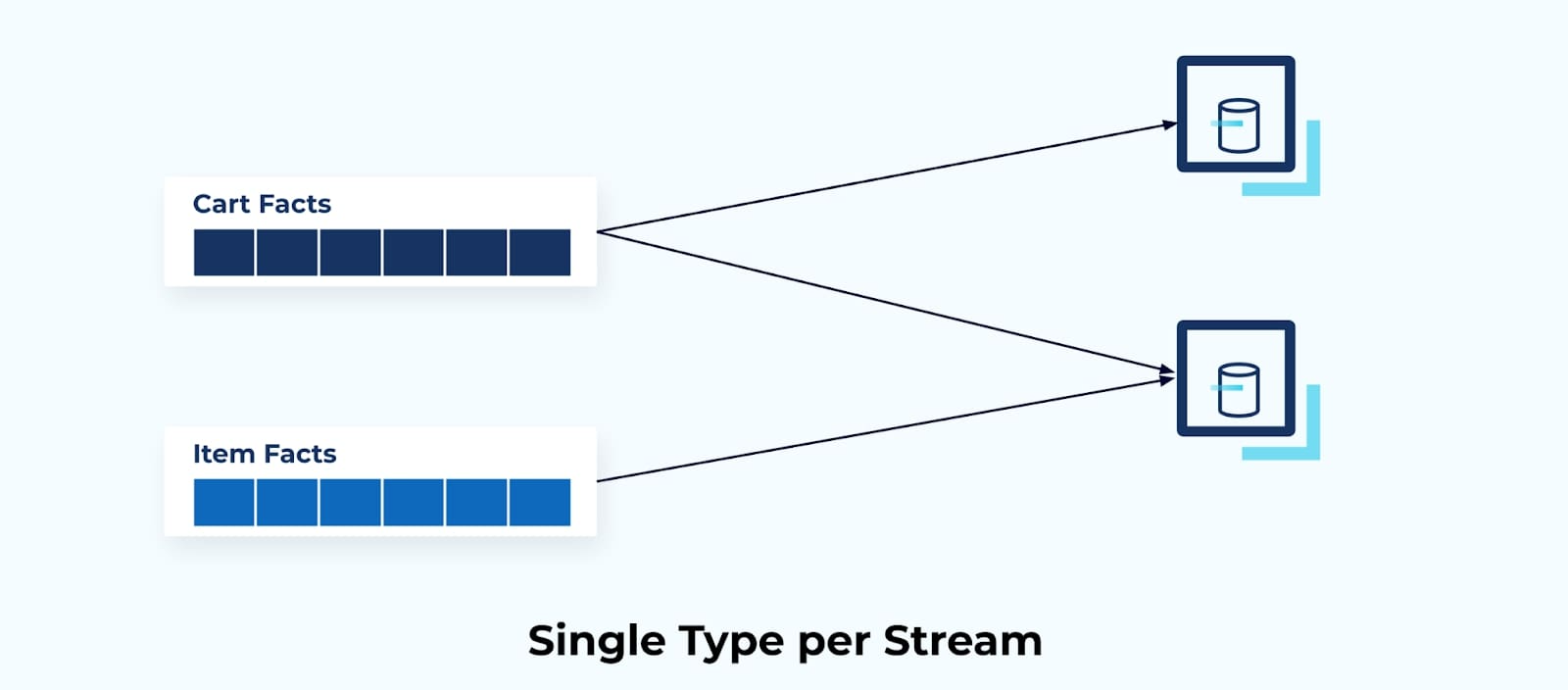
Keeping only one fact type per stream makes it much easier to transfer read-only state to any application that needs access to it. Streams of Facts effectively act as data building blocks for you to compose purpose-built applications and services for solving your business problems.
Single Fact Type Per Stream
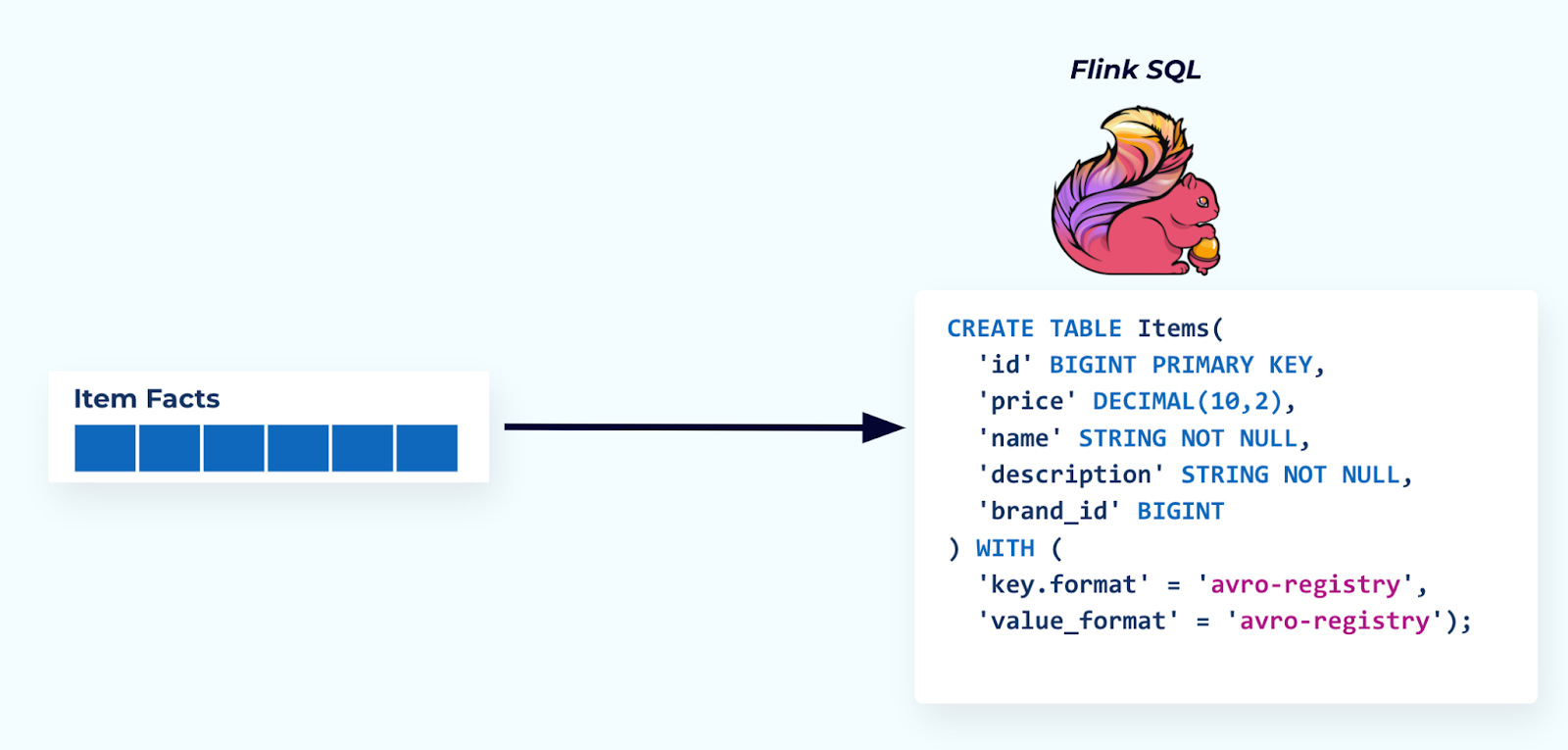
The convention of one type of fact per stream shows up again when you look into the tools you can build your applications with — like Kafka Streams or Flink.
In this example, a Flink SQL application materializes the item facts into a table. The query specifies the table schema, the Kafka topic source, the key column, and the key and value schema format.
Flink SQL enforces a strict schema definition and will throw away incoming events that do not adhere to it. This is identical to how a relational database will throw an exception if you try to insert data that doesn’t meet the table schema requirements.
Joining Disparate Fact Streams
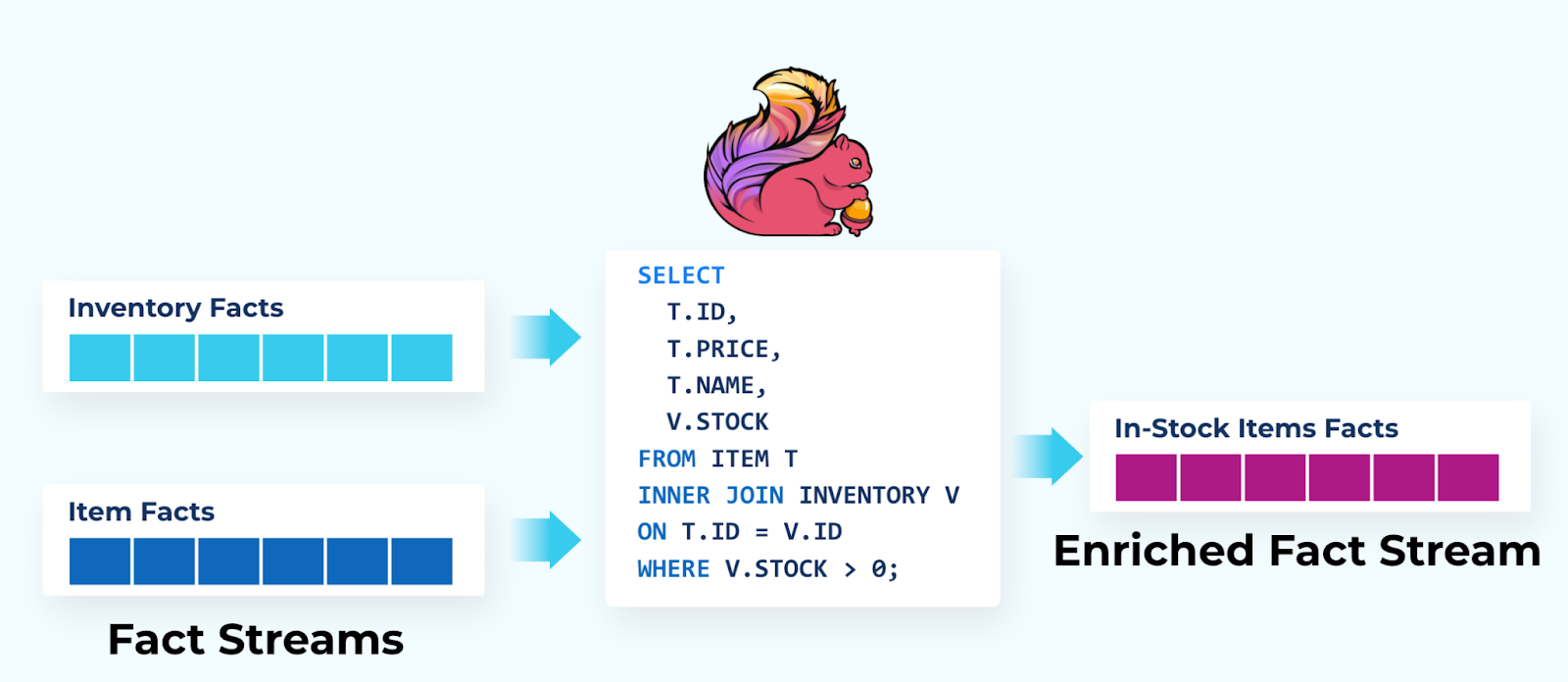
You can leverage Flink SQL’s join functionality when consuming multiple types of facts from different streams, selecting only the fields you need for your own business logic and discarding the rest. In this example, the Flink SQL application consumes from both inventory and item facts and selects just the ID, price, name, and stock, but only keeps records where there is at least one item in stock. The data is filtered and joined together, then emitted to the in-stock items facts stream, which can be used by any application that needs it.
Best Practice: Record the Entire State in One Fact
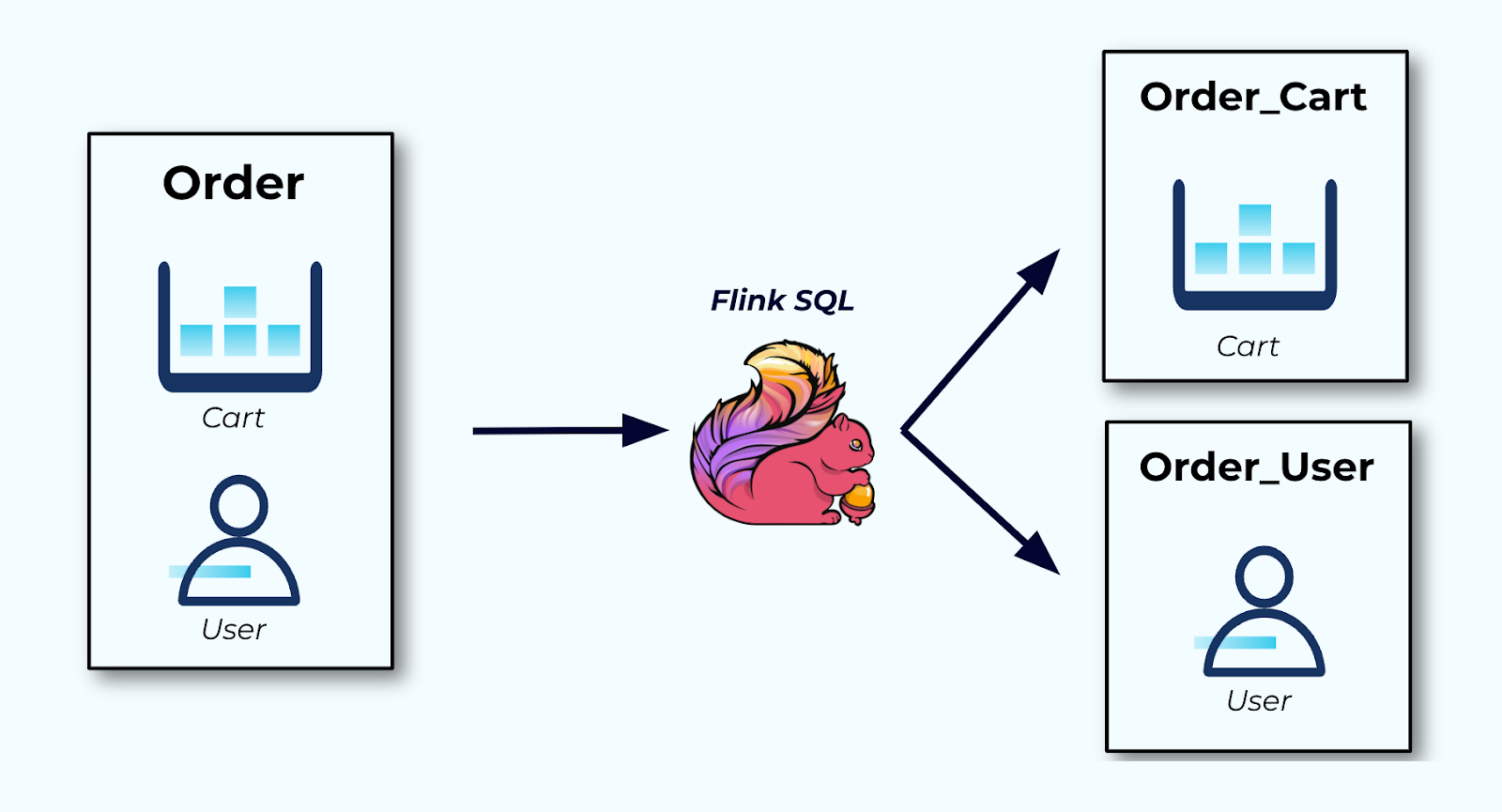
When recording an event, it’s important to keep everything that happened in a single detailed event.
Consider an order (above) that consists of both a cart entity and a user entity. When creating the order event, we insert all of the cart information as well as all of the user information for the user at that point in time. We record the event as a single atomic message to maintain an accurate representation of what happened. We do not split it up into multiple events in several other topics!
Consumers are free to select only the data they really want from the event, plus you can always split up the compound event. However, it is far more difficult to reconstruct the original event if you split it up from the beginning.
A best practice is to give the initial event a unique ID, and then propagate it down to any derivative events. This provides event tracing. We will cover event IDs in more detail in a future post.
Use Case: Mixing Facts and Deltas
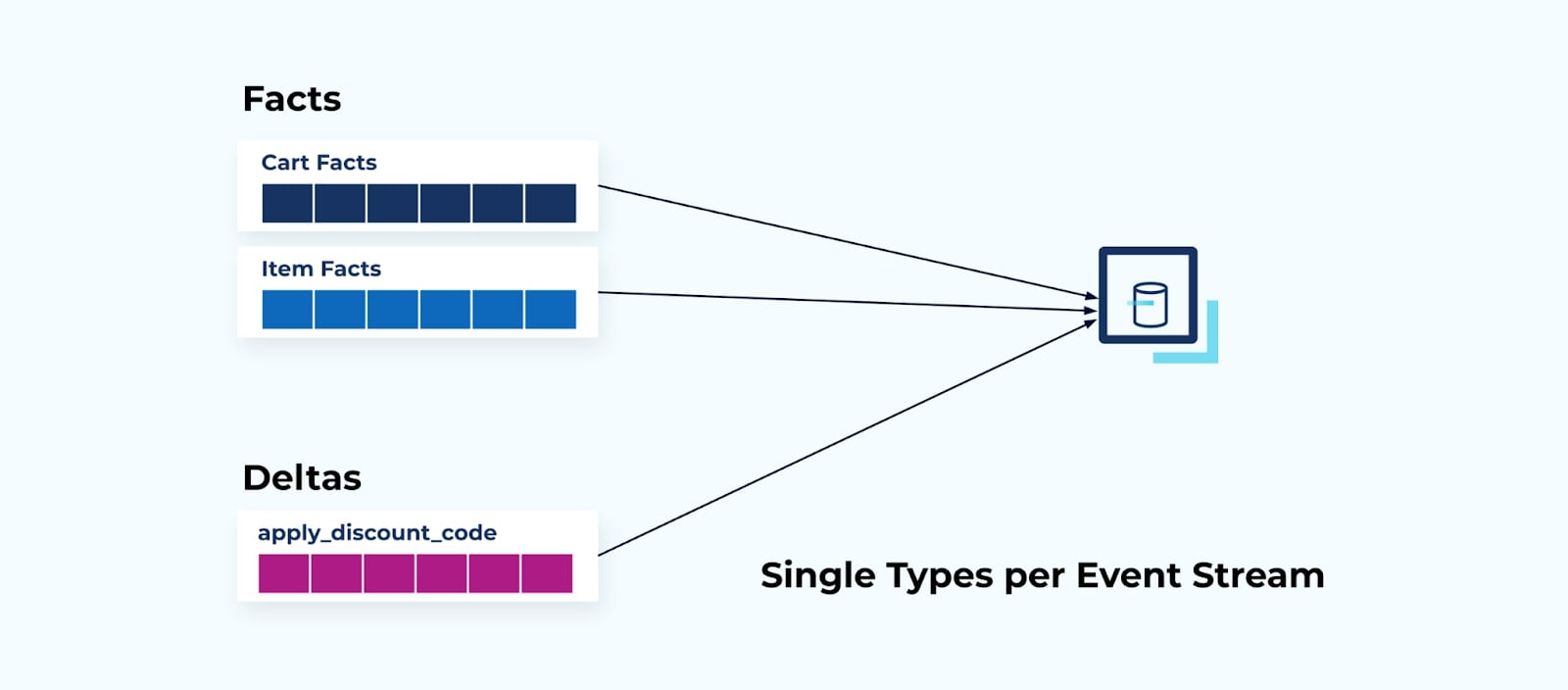
Consumers can also compose applications by selecting the fact streams that they need and combining them with selected deltas.
This approach is best served by single types per event stream, as it allows for easy mixing of data according to each consumer's needs.
Summary
Single streams of single delta types make it easy for applications to respond to specific edge conditions, but they remain responsible for building up their own state and applying their own business logic.
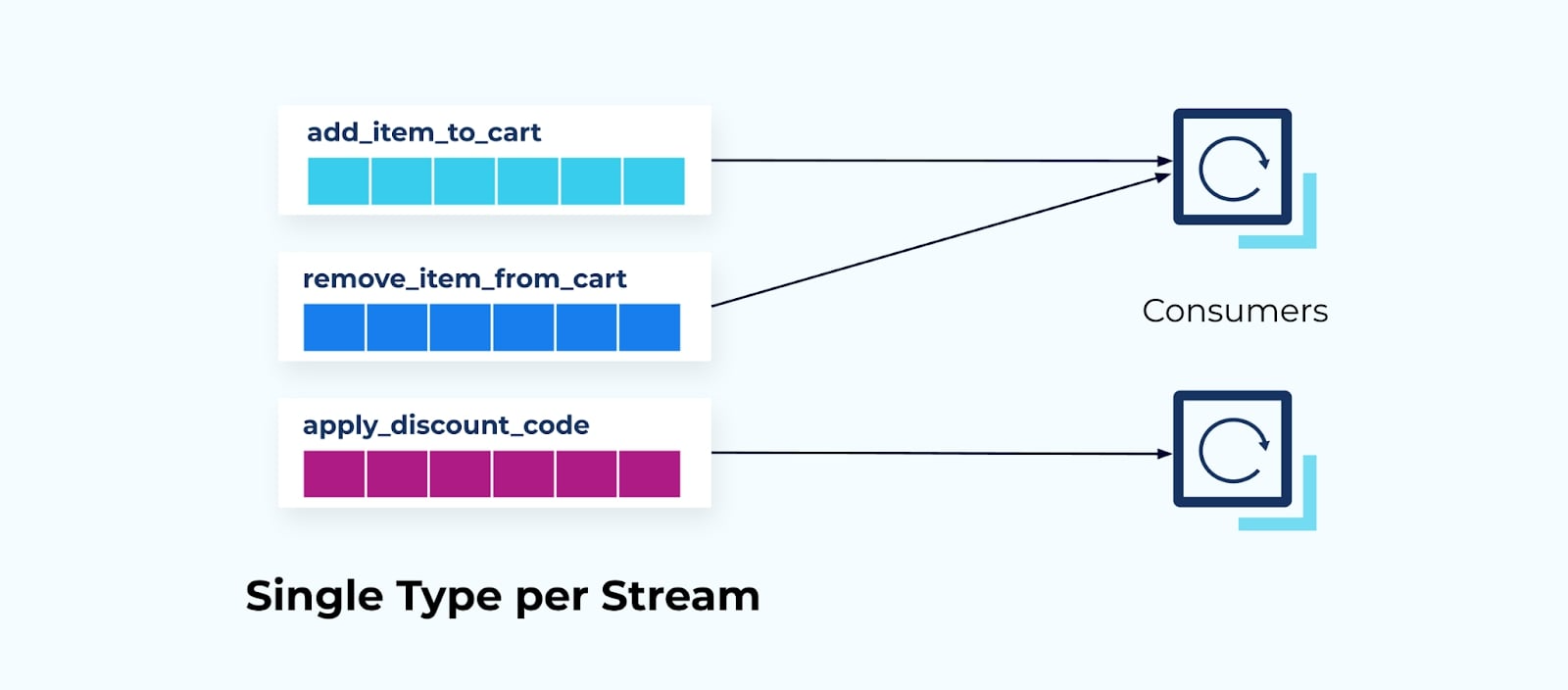
A single delta per stream can lead to difficulties when trying to create a perfect aggregation of states. It can also be challenging when trying to figure out which events need to be considered to build the aggregate.
Put multiple event types in the same stream if you are concerned about strict ordering, such as building up an aggregate from a series of deltas. You’ll have all of the data necessary to compose the final state, and in precisely the same order that it was published by the producer.
The downside is that you must consume and process each event, even if it’s one you don’t really care about.
And finally, use a single event type for fact streams. This is identical to how you would store this information in a relational database, with a single well-defined schema per table. Your stream consumers can mix, match, and blend the fact events they need for their own use cases using tools like Kafka Streams or Flink.
There’s one more part to go in this event design series. Stay tuned for the next one, where we’ll wrap it up, covering elements such as workflows, assorted best practices, and basics of schema evolution.
Opinions expressed by DZone contributors are their own.
Comments