How to do Memory Management for DataWeave
This article explains on how can we can perform memory management to effectively run larger MuleSoft DataWeave scripts.
Join the DZone community and get the full member experience.
Join For FreeAbout
This article goes over how to perform memory management in order to effectively run larger MuleSoft DataWeave scripts. I tried to create helpful images to explain how DataWeave memory management works.
Introduction
DataWeave is a powerful and MuleSoft proprietary data transformation expression language, tightly integrated with powerful Mule Runtime Engine.
The MuleSoft platform uses the DataWeave engine to weave one or more different types of input data together to create another output data format.
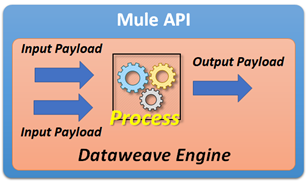
Starting with version 4.x, MuleSoft extended its support and began using DataWeave scripts in most of its message processors.
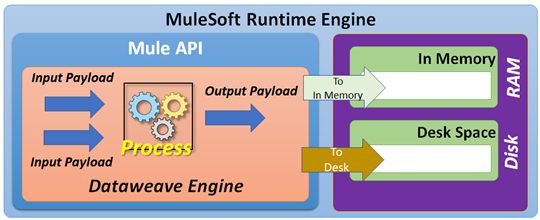
MuleSoft strongly recommends using DataWeave scripts while building Mule integration flows. Thus, writing efficient DataWeave scripts is very much required in processing large payloads and performing data transformations. While performing large input data processing by using DataWeave, we may experience memory errors. In these cases, we might need to do some fine-tuning of our memory usage. To act on input payloads, DataWeave has to keep the data in small/large files, either in-memory or on disk space.
Smaller temporary files are managed in-memory. If these temporary file sizes increase, we may require the use of disk space.
Deep Dive
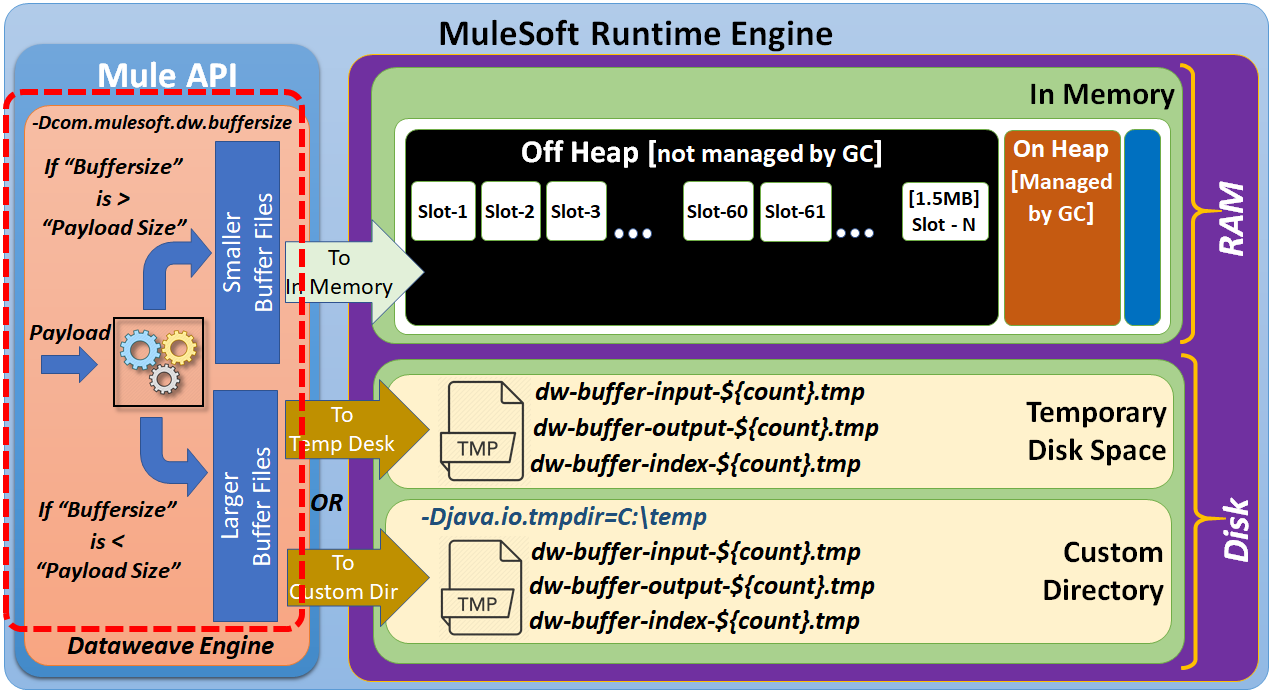
To perform data transformation, DataWeave needs to have a temporary space to keep input and output payloads. While performing smaller data transformations, DataWeave keeps the input/output buffer files in-memory. But to handle larger data transformations, the DataWeave engine may require the use of disk space.
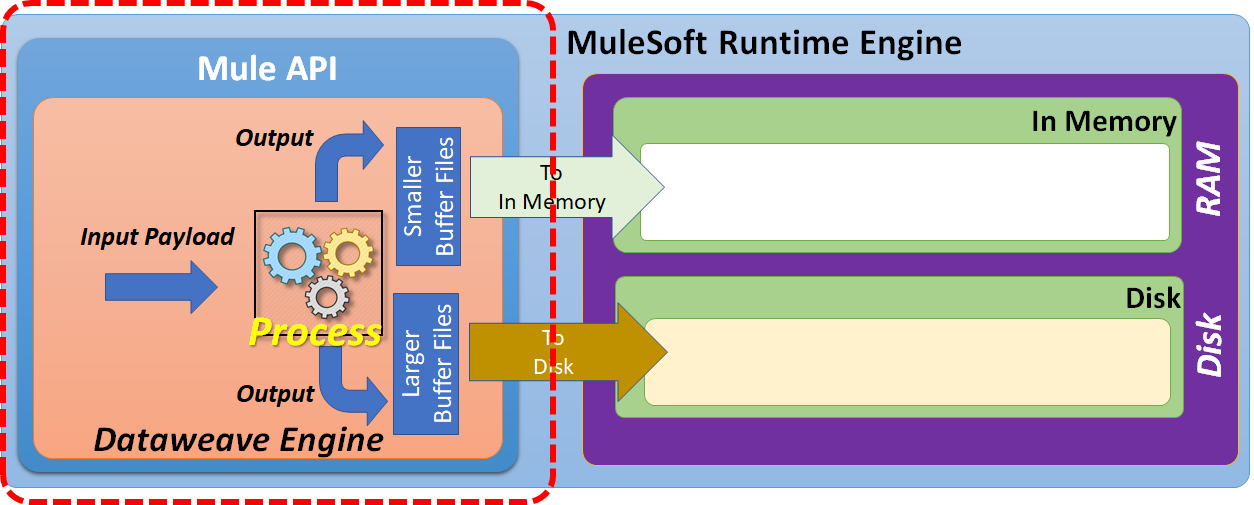
Based on the input payload size, the DataWeave engine has to manage either smaller buffer files or larger buffer files.
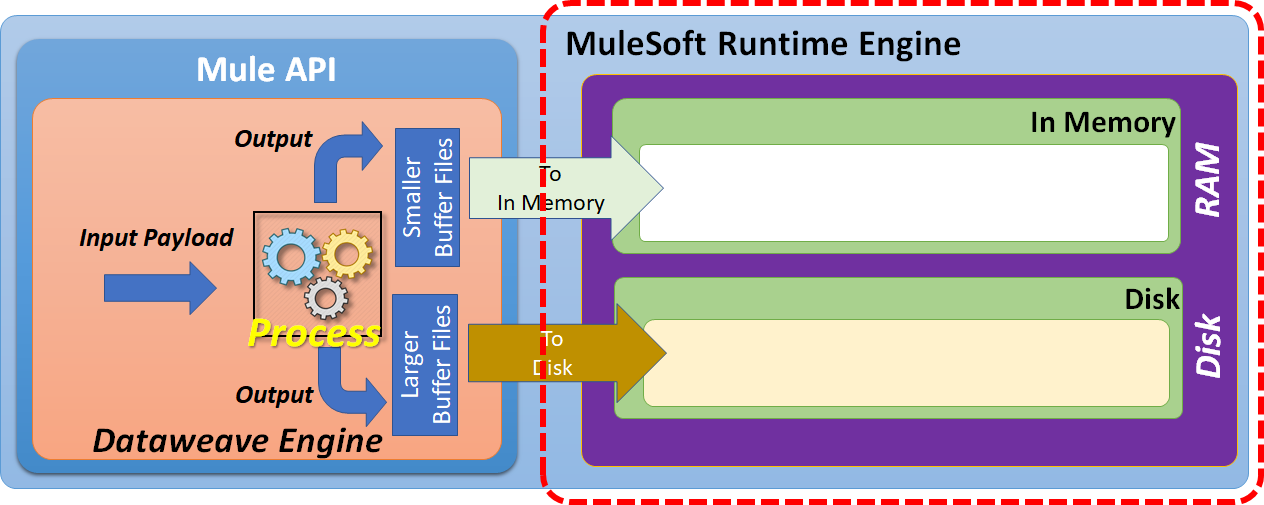
Smaller buffer files can be managed by using in-memory storage (RAM).
To manage the larger buffer files, we may be required to use disk space.
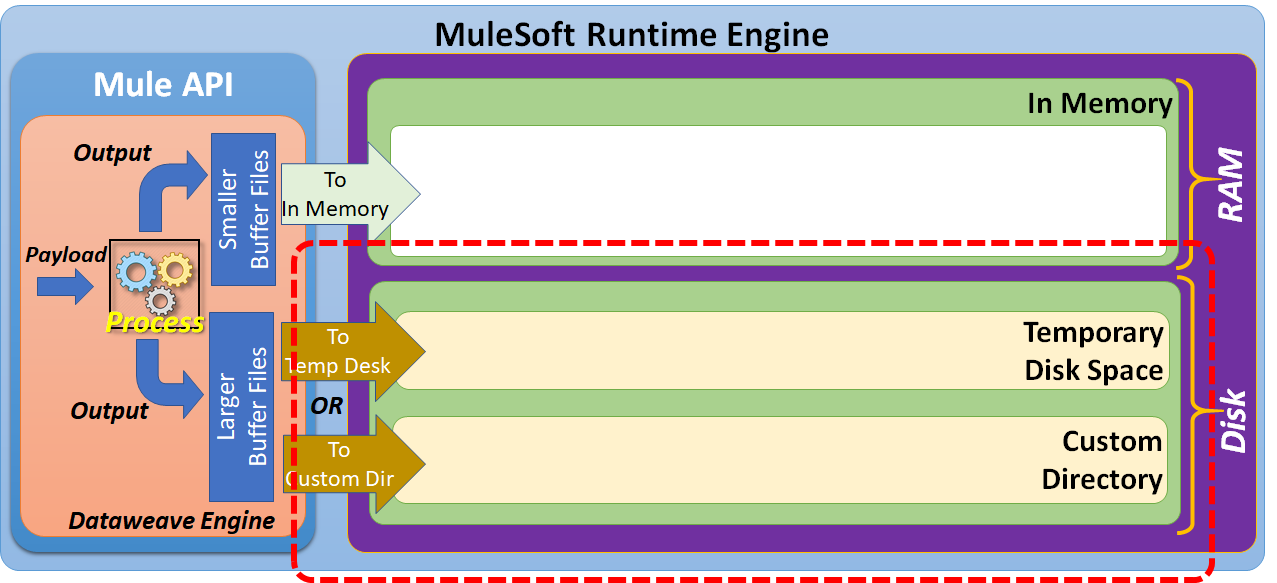
Disk space can be further categorized as "Temporary Disk Space" or "Custom Directory."
By default, larger buffer files are written to temporary disk space. But, we can customize this to write these larger buffer files to a specified custom directory.
Off Heap Memory
Before we go further, let's try to talk more about off heap memory.
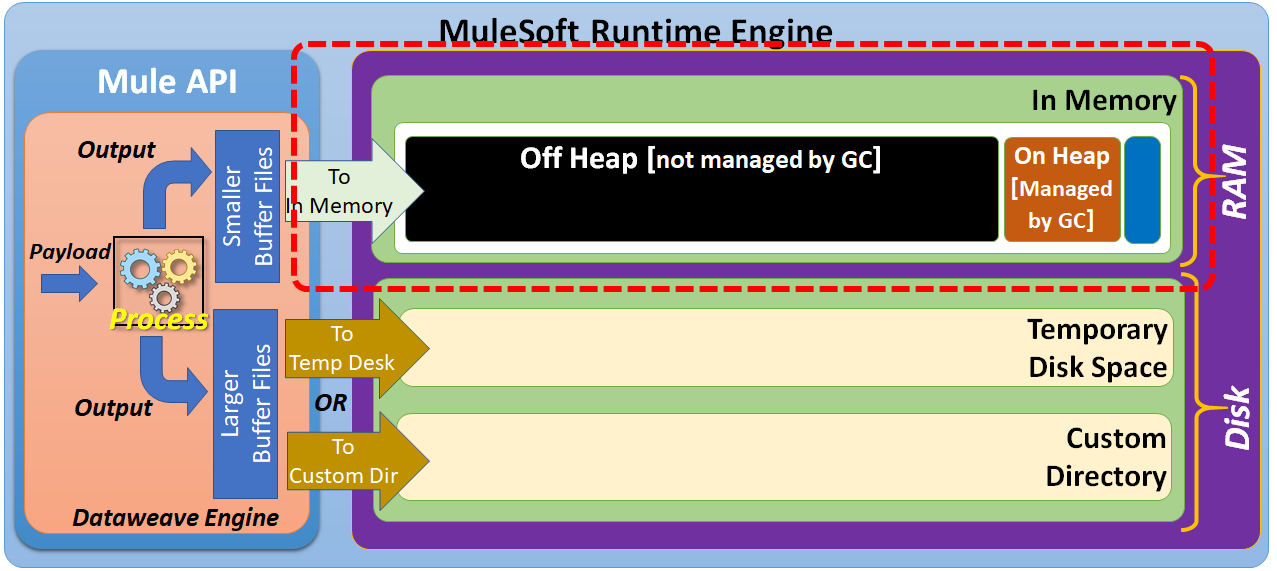
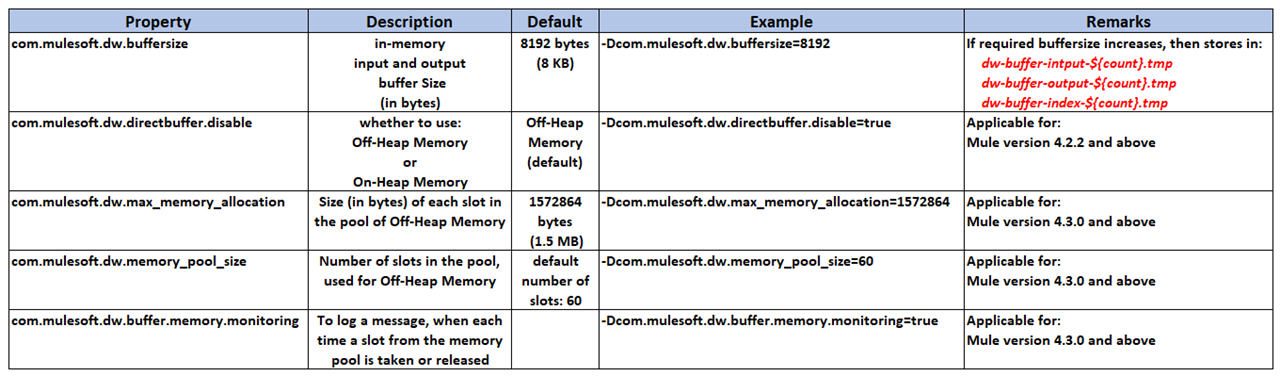
By default, smaller buffer files are written to "off heap" memory space, which is not managed by a Garbage Collector (GC). But, we can configure MuleSoft to use "on heap" memory space, which is managed by a Garbage Collector (GC).
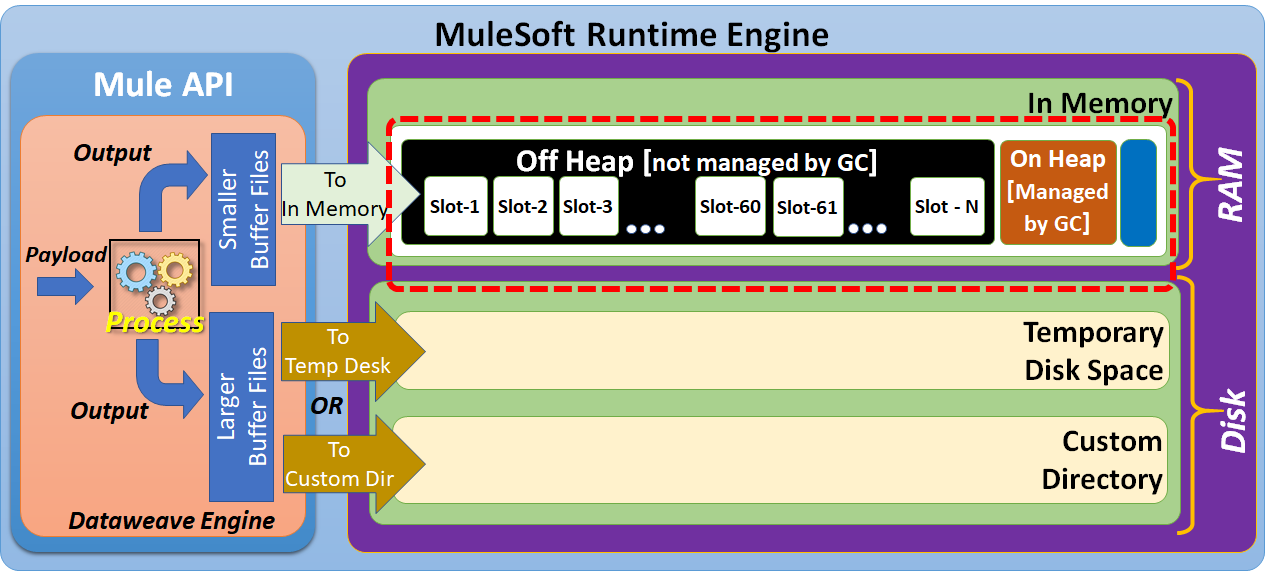
Off heap memory space consists of "slots." By default, the size of each slot is 1.5MB.
By default, DataWeave uses memory pool slots with a size of 60. But these parameters can be further configured.

Once the size of the buffer files exceeds the configurable threshold values, then these files are written to temporary disk space.
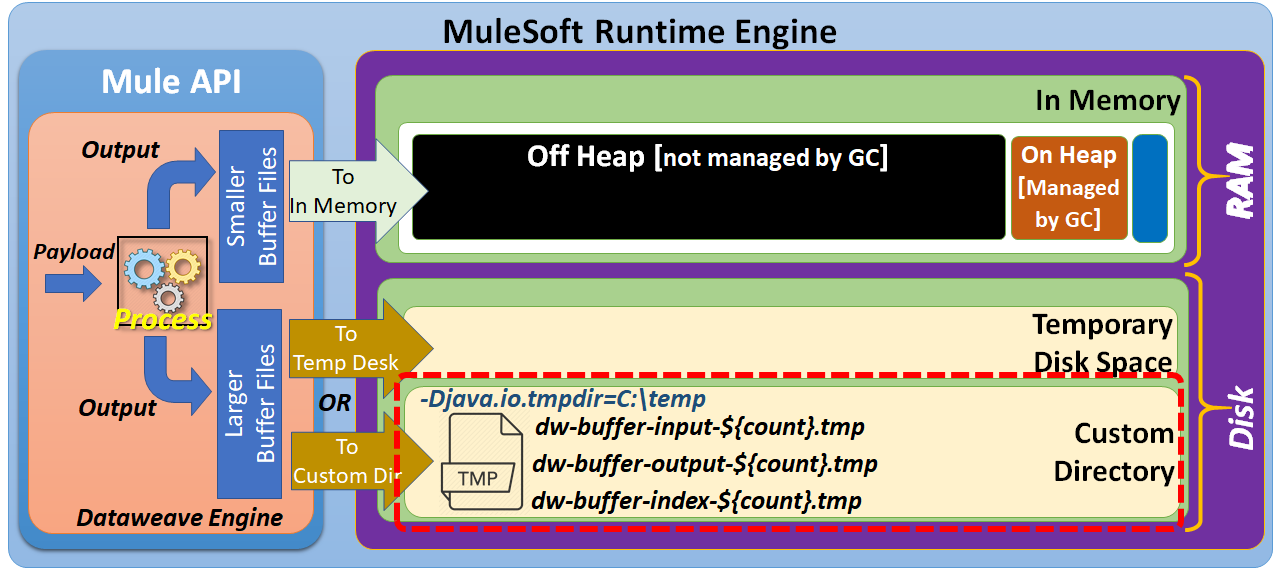
If required, these files can be written to a Custom Directory by specifying the system property java.io.tmpdir.
Input Buffer Files
Used to store the input of a transformation when it is bigger than the in-memory buffer value.
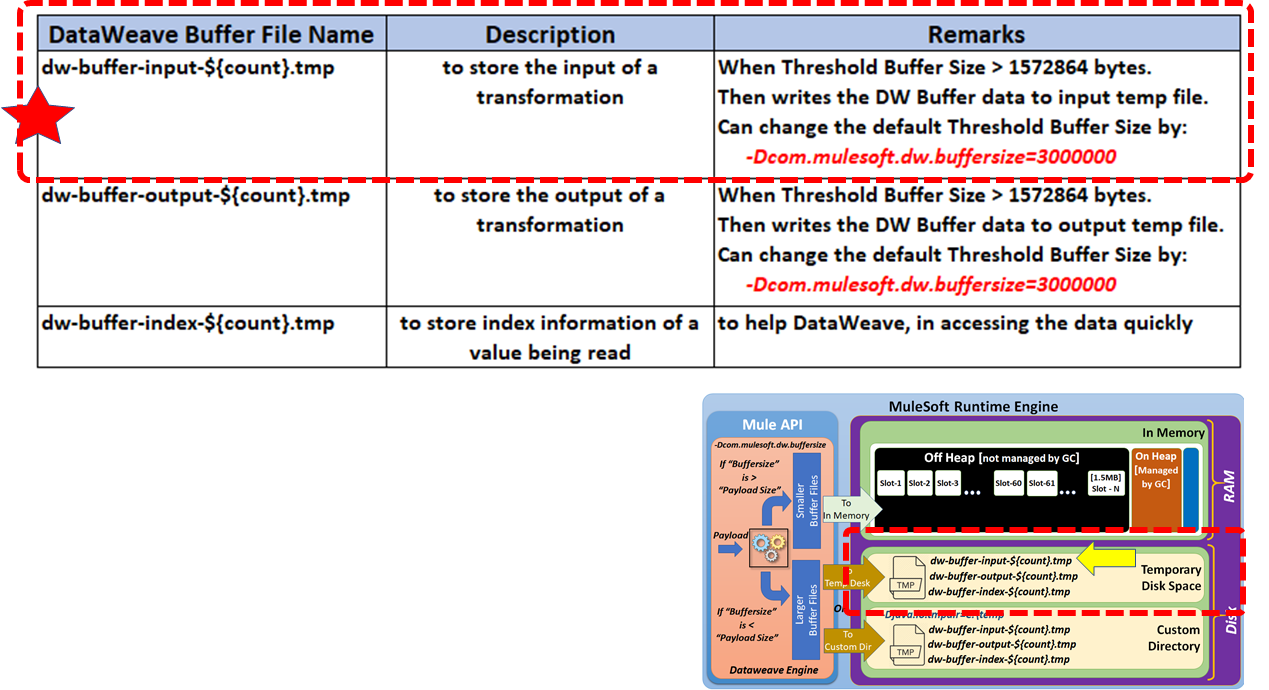
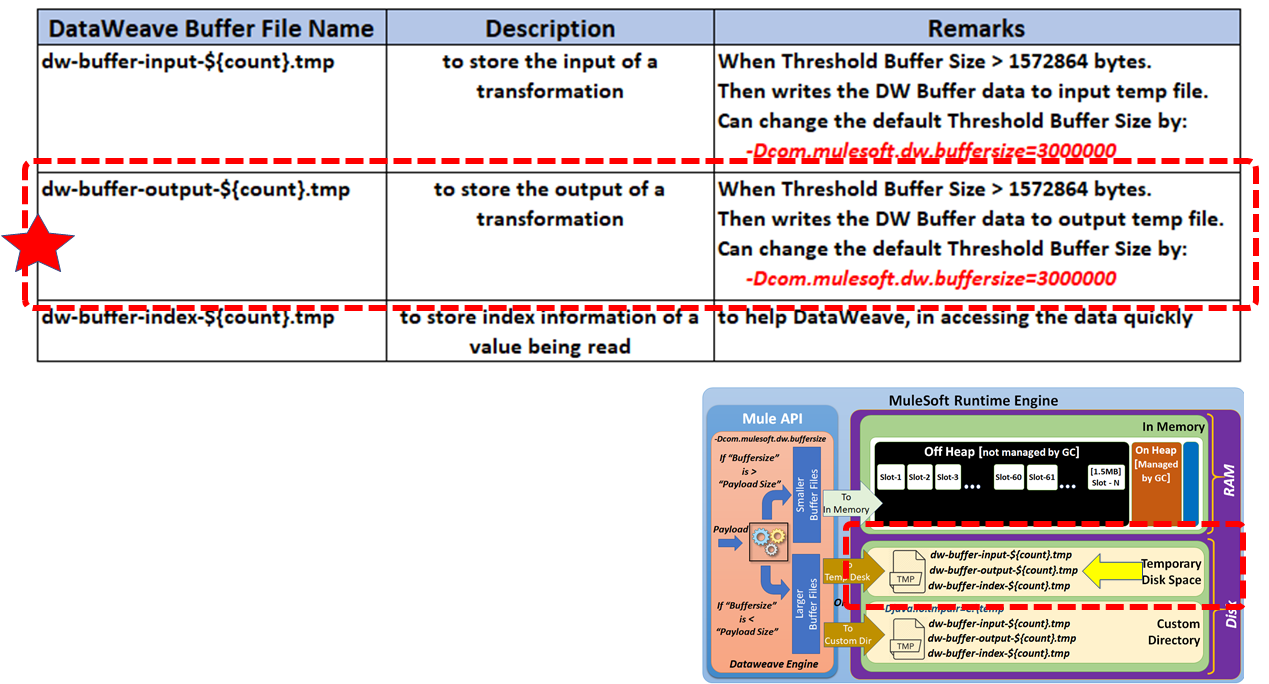
Output Buffer Files
Used to store the output of a transformation when the result is bigger than the threshold value.
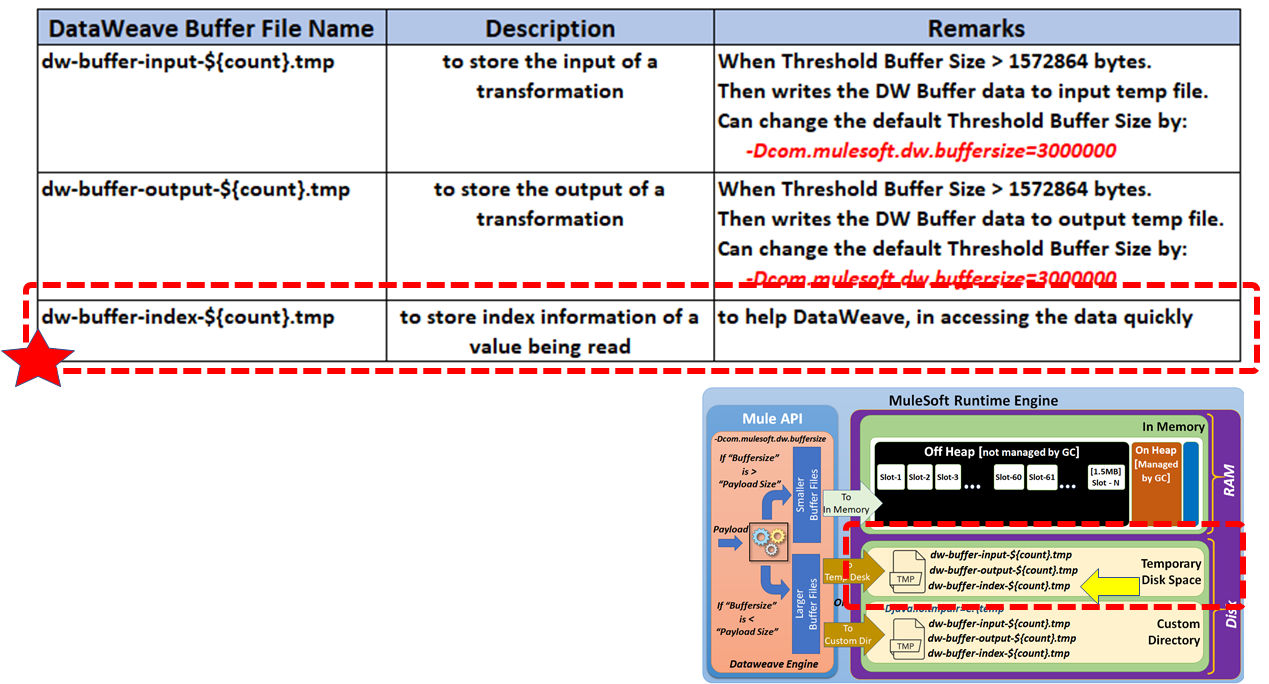
Index Buffer Files
Used to store the index information of a value being read.
Managing Memory
Use the system property com.mulesoft.dw.buffersize to determine the size of the in-memory input and output buffers used in DataWeave to keep the processed inputs and outputs. If a payload exceeds this size, it is stored in *.tmp temporary files.
If the buffer size is greater than the payload size, then buffer files are written to in-memory space.
If the buffer size is less than the payload size, then buffer files are written to disk space.
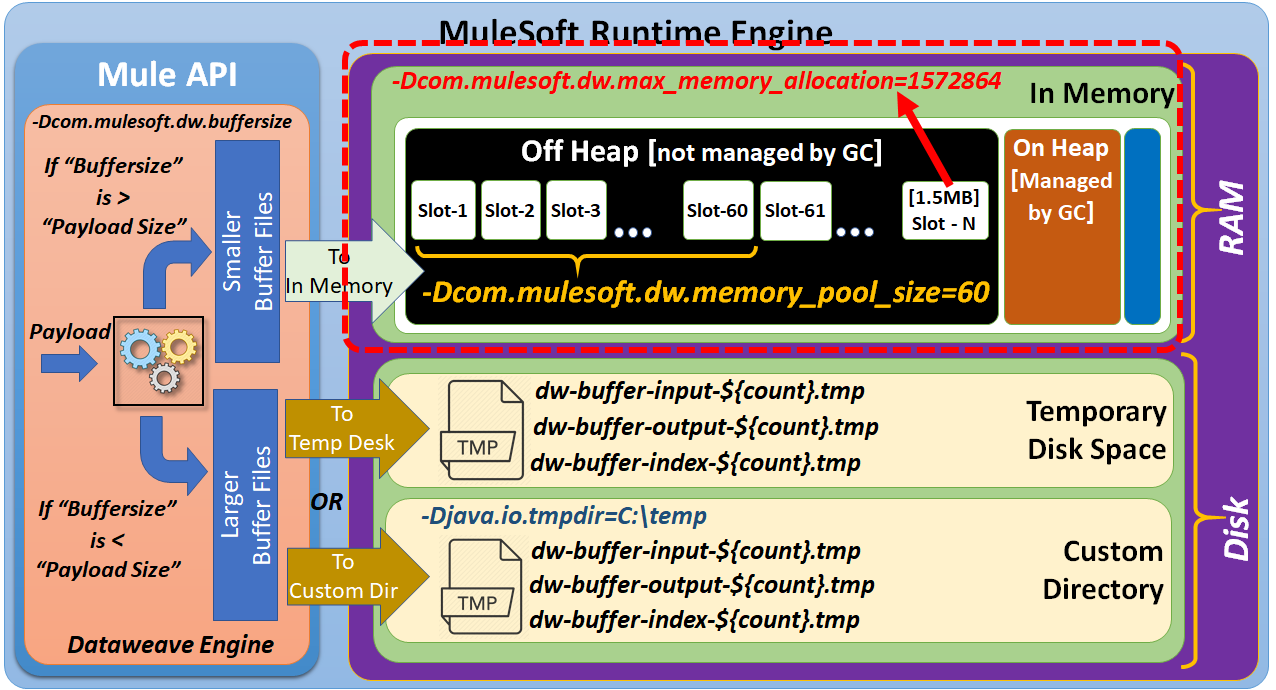
The size of each off-heap slot can be configured by using the system property:
-Dcom.mulesoft.dw.max_memory_allocation=1572864
Also, the size of an off-heap slot's memory pool can be configured by using the system property:
xxxxxxxxxx
-Dcom.mulesoft.dw.memory_pool_size=60
The table below provides the details of different systems properties, which can be configured to fine-tune Memory Usage.
Conclusion
Memory management in DataWeave plays a key role in efficiently performing larger data transformations. Make sure to use appropriate system properties for fine-tuning memory usage.
In case of any further queries on this article, add a comment here. Your feedback matters a lot.
Opinions expressed by DZone contributors are their own.
Comments