How To Implement and Design Twitter Search Backend Systems using Java Microservices?
In this article, you’ll learn about implement and design Twitter search backend systems functionality how to work using Java microservices with explanations.
Join the DZone community and get the full member experience.
Join For FreeTwitter is the largest and one among the most important social networking service where users can share photos, news, and text-based messages. In this article, I have explained in this blog about designing a service which, will store and search user tweets.
What do you mean by Twitter Search and how this functionality works?
Twitter users can update their status whenever they want to update irrespective of time. Each status or we can say it as Tweets consists of a plain string or test, and I intend to design a system that allows searching over all the user tweets. In this blog, I have given importance to the Tweet Search Functionality.
The predominant factors where I have given more emphasis throughout the blogs are given below:
- Functional and Nonfunctional Requirements for the Twitter Search System
- Estimation of initial Capacity:-considering all Constraints
- Rest APIs needed for the Applications
- High-Level Design architecture
- Detailed system explanations with Components Design Diagram
- High Scalability & Fault Tolerance
- Caching using Redis Cluster
- Load Balancers for Load balancing
- Feedback/Rating Service
Requirements for the Twitter Search System
Let’s consider the functional and non-functional requirements: As you know the fact here that Twitter has more than 1 billion total users with 600 million daily active users. So, if we calculate the average then Twitter gets every day more than 200 million tweets approximately. Then if you calculate the average size of a tweet, it will come to around 300 bytes. Then, in this case, we have to assume there will be 500M searches every day. The search queries generally consist of multiple words combined with AND/OR. So, our goal here is to come up with a system that can efficiently store and query tweets.
Estimation of Initial Capacity:
Storage Capacity: Since as per our calculation, we will have every day 200 million new tweets, and then if we calculate the average it will come around 200 bytes. So, let’s find out how much storage we will need here:
200M * 200 equals to = approx. 40GB/day
So, the calculation goes like this: - Total storage per second: 40GB / 24hours / 3600sec approximately = 0.4MB/second
Designing REST API
Now we have to implement REST APIs to expose the functionality of our service; the following could be the definition of the search API:
Sample Handler method Signature
search(api_key, search_words, max_results, sort, page_token)
Parameters
- api_key (string): The API key of a registered account. This will be used to, among other things, restrict users based on their allocated permissions/quota.
- search_words (string): A string containing the search terms.
- max_results (number): Number of tweets to return.
- sort (number): Optional sort mode: Latest first (0 - default), Best matched (1), Most liked (2).
- page_token (string): This token will specify a page in the result set that should be returned.
Response Body: (JSON)
The response body returned will be a JSON which will contain information about the below fields:
- Several tweets that match with the search query and return type will be a List here.
- Each tweet that, is returned will have the user_ID & User_Name then we will have Tweet_ID & Tweet_Text filed.
- Also, the JSON will contain the creation timestamp & number of likes as well.
High-Level Design Architecture
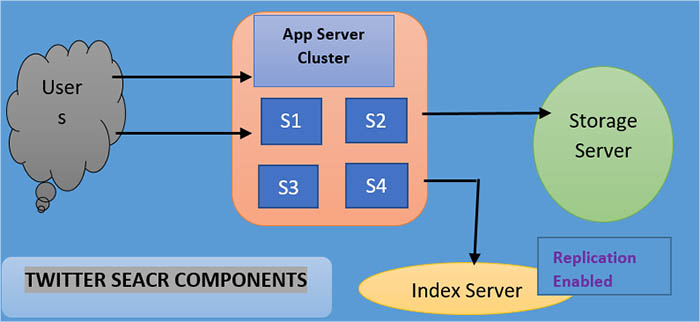
At the high level, I have explained here how we can design our backend system to store all the tweets in our SQL / NoSQL database and the next step is creating or building an index. The significance of this index is to keep track of those words which appear in specific tweets. In this way, with the help of our index, we can quickly find the search tweets when a user tries to search for a specific tweet.
Storage: We have to consider how much storage space is needed here to store the new tweets of size 400GB every day. As you can, guess this is going to be a huge amount of data, so, we definitely have to think of some advanced data storage mechanism which is data partitioning and database sharding scheme. These mechanisms will share/distribute the data efficiently to clusters of multiple servers. Let’s consider for the next five years Plan, then we are going need the following storage:
So, the calculation goes like this 40GB * 365days * 5years approximately = 70TB
If you do not want to be saturated or more than 80-85% full at any time, we approximately will need 80TB of total storage. Let’s assume that we want to keep an extra copy of all tweets for fault tolerance; then, our total storage requirement will be 200 TB. If we assume a modern server can store up to 1TB of data, we will need 70-80 such servers to hold all of the required data for the next five years.
Let’s start with a simplistic design where we store the tweets in a MySQL/Oracle database. You can even opt for NoSQL Db like Mongo or Cassandra. Here, better we can assume that we store the tweets in a table having two columns, Tweet ID and Tweet message. Let’s assume we partition our data based on Tweet ID. If our Tweet IDs are particular system-wide, we will outline a hash characteristic that can map a Tweet ID to a storage server wherein, we will save that tweet object.
How can we build here the unique Tweet IDs throughout our backend system? If we consider that we may get every day 400M new tweets, then let’s calculate how many tweet objects will be created in five years?
So, the calculation goes like this:- 200M * 365 days * 5 years equals approx. 370 billion
It means we will require around the number which is of 5 bytes size here to identify the Tweet IDs uniformly or uniquely. We can consider here one thing that we have a service, that will be generating a unique Tweet ID when we are going to store an object (To note here the Tweet ID I have mentioned here is similar to Tweet ID what I already mentioned in Designing Twitter section). Then you can feed this Tweet ID to the hash function to find the storage server and store our tweet object there.
Index: What should our index suppose to be designed or formed? Since our tweet queries will consist of words, hence we have to build an index that can tell us which word comes in which tweet object. In this case, we have to estimate first our index will look like how big or how small.
If we want to build an index for all the English words and some famous nouns like people names, address or city names, etc., and if we assume that we have around 200K-250K English words and around 150K nouns, then we will have 350-400k total words in our index. So, considering the above fact, we have to assume that the average length of a word is 4-5 characters. If we are keeping our index in memory, we need 1-1.5MB approximately of memory to store all the words:
400K (Taking a maximum of) * (Taking a maximum of) 5 = approx. 2 MB
One more thing here we have to consider is that we want to keep the index in memory for all the tweets from only the past 1 year. You can increase to 2 Years, but I have considered the basic level here. Since we will be getting approximately 370 B tweets in 5 years, it will give us 74 B tweets in one year. In our case, as we have considered that each Tweet ID will be 5 bytes, let’s calculate how much memory will we need to store all the Tweet IDs?
In our case, it will be 74 B * 5 = approximately 370 GB
So, our index what I mentioned here should be like a distributed hash table, where ‘value’ can be a list of Tweet IDs which will have from all those tweets which contain that word and ‘key’ will be the search term or search word.
Assuming on average we have 20-30 words in each tweet messages and since we will not be considering for indexing the prepositions and other small words like ‘the’, ‘an’, ‘and’ etc.: these we will be excluded from indexing, So, assume here that we will have approximately 10 words which need to be indexed in each tweet message. It means each Tweet ID will be stored 10 times in our index. So, let’s calculate how much total memory we may need for storing our index:
(370 * 10) + 0.4 MB approximately equals to = 1.5 TB
If we assume that a high-end server has 130GB of memory, we would need 15 such servers to hold our index, and then we can partition our data based on two criteria.
Word-Based Sharing: When creating our index, we will repeat through all the words in the tweet and calculate the hash of each word to find the server where it will be indexed. To get all the tweets that contain a specific word, then in this case just query to that specific server that contains that word or term.
We can have side effects with this approach where we may get few issues which I have explained below:
- In case the Tweet search word or term becomes popular or we say it is a technical term as “HOT”, Then in this case there will be a lot of queries that need to be triggered on the server which holds that word. As this will cause a very high load on the server then it will affect the performance of our Search service.
- After some days or years, there may be few words that will end up storing a lot of Tweet IDs compared to others, therefore, to maintain a proper or uniform distribution of words while tweets are growing is a little bit tricky. To get rid of these situations, we have to go for Consistent Hashing, or another alternative option is to repartition our data.
- Sharding is based on the tweet object: While storing, we will pass the Tweet ID to our hash function to find the server and index all the tweet words on that particular server or server. So, when you will be querying for a particular word, we have to query all the servers. In this case, each one of the servers will return a set of Tweet IDs. Then finally a centralized server will aggregate these results to return them to the user.
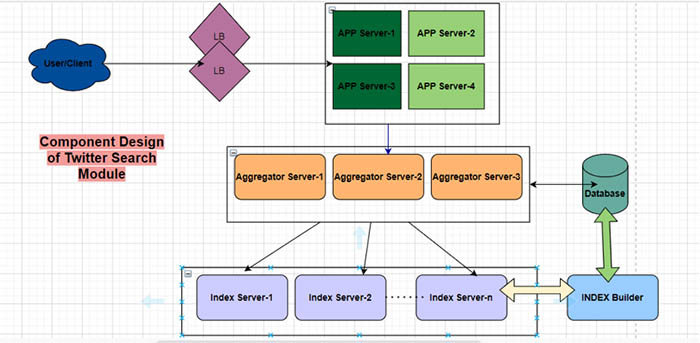
System Designing for Twitter Search Service
Detailed Component Design
Here, we directly apply several microservices like the search service to its service user timeline, home timeline, and social graph, fan out and of course, there is a data store and caching layer as well. You can find here we actually go deep down into designing the Twitter search service and also you can get to know how the fan-out service works and how the home timeline service works as well.
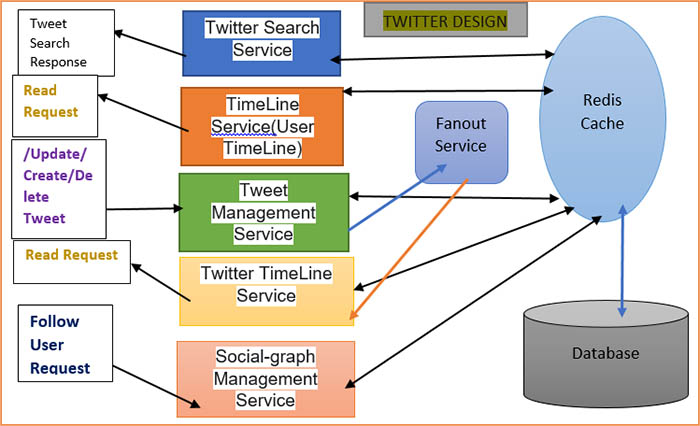
Fan-out service is possible for forwarding that to it from the tweet service to search service and the user home timeline service. In case there are other components or microservices in the Twitter service architecture for example notification or trending service, it is the fellow service that is possible for forwarding the tweets to those services as well.
The Fan-out service comparison of multiple distributed queues and whenever a tweet service receives a tweet from a user it passes the tweet to the fan-out service by calling an API exposed by the fan-out service which is called push-tweet. The push-tweet API inserts the tweet in one of the distributed queues. The distributed queues at the first stage are assigned by the hash of the user ID of the user who posted the tweet. The function push() returns immediately after posting the tweet to one of the distributed queues.
How does the Twitter Search Service module work?
The search service is formed on basis of the following logical components. Wo we have Ingester, Search index, and Blender, and of course we have data store with Cache. The Ingester or ingestion engine is responsible for tokenizing the Tweet into several terms or keywords. Let me give you an example where a user posts a tweet that ”Bangalore is becoming a hub of IT companies”. Eventually, the fan-out service will forward this tweet to the Search service and it will call an API to forward this to it to the Ingester.
The Ingester will first organize this into following different terms with each word separately. It will then filter out those terms or words which are not useful to be used for search. These terms are called Stop Words. So, for example, it will remove, or discard “is” and “of” words from the whole sentence because they are not useful for searching.
The Ingester can get the listing of these phrases this is the prevent phrases both shape a few configurations or a few databases that it has the following step is to carry out a technique known as Stemming at the closing phrases to discover the foundation phrase. Stemming is the technique of decreasing inflected or every so often known as derived phrases to the phrase stem or root phrase For example, the root word for Bangalore is Bangalore and for IT Hub it is IT Hub. But here companies actually can become a company.
The Ingester component then passes the tweet along with the root terms to the search index component. It is to be noted that Ingester would comply with at least three application servers and we can of course always increase these application servers as the load on the service increases.
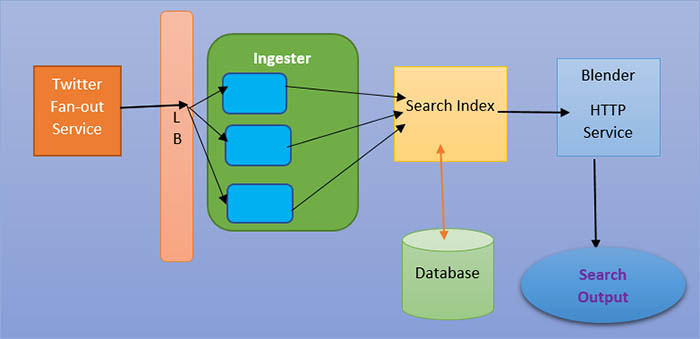
The search index module will generally create an inverted index. An inverted index is nothing but an "Index Datastrcuture" which stores or saves a mapping among the contents together with phrases to its area withinside the report or set of files that are in our case might be ready of tweets. For the search index, the search-index for micro provider or thing shops the phrases together with the Tweet ID withinside the datastore.
Now there is more than one process or we can say multiple approaches to shard the data store, The first and easy approach to shard the data store is by “Sharding by words.” In this approach, we shard the database by the hash of the word, which means different words will be in different partitions, and then a single partition will hold all the tweets that contain that word.
In this case to find the tweets containing a specific word we just need to go to a single partition. So, in that case, the search is very fast however the call form and Ingester to a search index to generate this inverted index will be slower, because it's possible now that a tweet may contain 9, 10, 12, 13, or even more terms.
So, we would be going to different partitions to write the word – to- tweet ID mapping in all those partitions for all the different terms or words which are Tweet contains.
In our example of the tweet, we are saying that “Bangalore is becoming a hub of IT companies, we have four different terms or words. When Ingester will send the Write operation to the search index we will go to four different partitions for the word “Bangalore”, “hub”, IT, and company to store the Tweet ID mapping to all those words. There are some other issues with this approach for example if a word becomes hot then there will be lots of queries that come into this partition storing that word.
To mitigate that we can add Caching mechanism in front of the data store, and we can also add a large number of replicas for that particular partition in the distributed cache. The second approach is shared by Tweet ID. In this case, the write operation will go to a single partition and all the mapping between the words with Tweet ID will be stored there. With this Sharding approach, the write operation is very fast because we are just going to a single partition.
Search requires sending the request to all the partitions to read the list of tweets that contain a specific word. Then an aggregator server combines all those results from those different partitions before sending the final result to the user. The issue with this approach is that every single search query will hit all the partitions and thus will put extra pressure on the data store.
The Third sharding approach is to level shard by words and that Tweet ID. In this approach, we first perform the first layer sharding by the hash of the word to determine a group of partitions, and then we used the second layer sharding by Twitter ID to determine the person in that group where the word- to- Tweet ID mapping should be stored.
In this case to search tweets for a word we only need to go to only a small set of partitions. The search index will also have the same design that it will have at least three application servers and also it will have a distributed cache and a data store with it.
Fault Tolerance
- What will happen when an index server is out of Order? We can have replication here where a secondary replica of each server and if the primary server dies it can take control after the failover. So here both servers primary and secondary in this case will be holding the same copy of the index.
- Let’s say both primary and secondary servers go into shutdown state at the same time, then in that case, what you are going to do? In this case, we may allocate a new web server and rebuild the same index on it. But the question comes how you are going to do it? In this case, you are not aware of what terms or words, or tweets were kept on this server.
- If we want to use a brute-force mechanism solution approach which is :-> ‘Sharding based on the tweet object’, then it works in such a way that it iterates through the whole database to filter the Tweet IDs. Then, with the help of the hash function, it finds out all the tweets that are required and which need to be stored on this server. But just think yourself how it is really inefficient because when the new server builds up or starts up I mean during that gap of the rebuild of the new server, we will not be able to serve any query from it, hence we are going to missing some tweets that should have been seen by the user.
- So, the primary consideration is here how efficiently we can fetch a mapping between the index server and the tweet to obtain consistency. In this case, we have to go for the approach, where we need to build a reverse index that will map all the Tweet IDs to their index server. Our Index-Builder server will be holding this information. And we have to just build a Hash table where the ‘key’ will be the index server number and the ‘value’ will be a HashSet containing all the Tweet IDs which were already kept at that index server.
- One thing observes here is that we are storing/maintaining all the Tweet IDs in a HashSet; what it does is that this enables us to add/remove tweets quickly from our index server. So now, during the switch over time when an index server has to rebuild itself, it can simply query the Index-Builder server so that it will fetch all that tweets for which it can again build the index once after it stores those tweets. This approach is the best approach and surely be fast. Also, we can maintain a replica of the Index-Builder server for achieving fault tolerance.
Caching
To deal with hot tweets, the Java spring boot development team can introduce Caching Mechanism in front of our database. They can use Memcached or Redis, which can store all such hot tweets in memory as key-value pairs in the Redis cache. We can set up the Redis cluster for High availability. Application servers, before hitting the backend database, can check if the cache has that tweet. So that the loads on the database will be less. Based on the User’s usage patterns or during heavy traffic or low traffic, you can adjust the number of cache servers you need.
Scaling & Load Balancing
In our design architecture, we can implement a load balancing layer at two places in our System environment:
- Clients --LB-- Application Servers
- Application Servers --LB-- Backend Server.
Initially, a very basic Round Robin Load balancing approach can be leveraged for our requirement model that uniformly routes the incoming requests to the underlying backend Apache Web servers. This Load Balancer (LB) ideally does not introduce any performance issue or overhead in case of heavy Load. Another benefit of this Load balancing approach is that it discards the servers which are already dead, and it manages the traffic through other active servers and does not send any request to dead servers by taking out of the rotation.
But there are also few drawbacks of this Round Robin Load balancer. It does not consider the server load in case if it is heavily loaded or less occupied. What I mean to say here is that even though the server is heavily loaded, the LB continues sending the traffic to that server. To overcome the above drawback, another powerful intelligent Load balancing technique can be used in our case. What this LB does the extra thing? It manages the load efficiently by keeping track of the load of each server by querying the backend servers periodically for knowing their health status as well as the load percentage and then accordingly adjust traffic.
Feedback & Rating
How can we achieve ranking and Feedback functionality where Search Results have to be ranked on basis of few factors such as social graph distance/popularity or relevance etc. that? Let’s assume on basis of Popularity we want to rank the tweets by the number of likes or comments on a specific tweet is getting, etc. In such a case, our Ranking or Rating algorithm can programmatically derive a ‘number’ based upon the likes’ count, we can call it a Popularity number. Then we have to store and map it with the index.
Before returning the results to the aggregator server, what needs to be done here:- Each partition can filter the results and then sort primarily based totally on this number of likes. The next step is that the aggregator server collects all these results, adds up this result, and then applies a sorting algorithm based on that specific number which we derived earlier (i.e. the Popularity Number), and finally gives the response as the top results to the end-user.
Opinions expressed by DZone contributors are their own.
Comments