How to Populate a Child-Side Parent Association via a Hibernate-Specific Proxy
A handy solution to avoid a common persistence performance penalty.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we talk about a very handy performance optimization that can be applied in the persistence layer using Spring Data and Hibernate persistence provider.
You can fetch an entity by identifier via the Spring built-in query methods, findById() or getOne(). Behind the findById() method, Spring uses EntityManager#find(), and behind the getOne() method, Spring uses EntityManager#getReference().
Calling findById() returns the entity from the Persistence Context, the Second Level Cache, or the database (this is the strict order of attempting to find the indicated entity). Therefore, the returned entity is the same type as the declared entity mapping.
On the other hand, calling getOne() will return a Hibernate-specific proxy object. This is not the actual entity type. A Hibernate-specific proxy can be useful when a child entity can be persisted with a reference to its parent (@ManyToOne or @OneToOne lazy association). In such cases, fetching the parent entity from the database (executing the corresponding SELECT statement) is a performance penalty and merely a pointless action, because Hibernate can set the underlying foreign key value for an uninitialized proxy.
Let’s put this statement in practice via the @ManyToOne association. This association is a common JPA association, and it maps exactly to the one-to-many table relationship.
Therefore, consider that the Author and Book entities are involved in a unidirectional lazy @ManyToOne association. In the following example, the Author entity represents the parent-side, while the Book is the child-side. The author and book tables involved in this relationship are shown in the figure below:
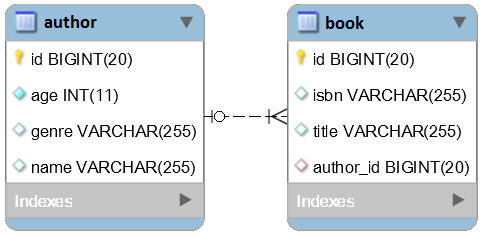
Consider that, in the author table, there is one author with an ID of 1. Now, let’s create a Book for this entry.
Using findById( )
Relying on findById() may result in the following code (of course, don’t use orElseThrow() in production; here, orElseThrow() is just a quick shortcut to extract the value from the returned Optional):
xxxxxxxxxx
public void addBookToAuthor() {
Author author = authorRepository.findById(1L).orElseThrow();
Book book = new Book();
book.setIsbn("001-MJ");
book.setTitle("The Canterbury Anthology");
book.setAuthor(author);
bookRepository.save(book);
}
Calling addBookToAuthor() triggers the following SQL statements:
xxxxxxxxxx
SELECT
author0_.id AS id1_0_0_,
author0_.age AS age2_0_0_,
author0_.genre AS genre3_0_0_,
author0_.name AS name4_0_0_
FROM author author0_
WHERE author0_.id = ?
INSERT INTO book (author_id, isbn, title)
VALUES (?, ?, ?)
First, a SELECT query is triggered via findById(). This SELECT fetches the author from the database. Next, the INSERT statement saves the new book by setting the foreign key, author_id.
Using getOne( )
Relying on getOne() may result in the following code:
xxxxxxxxxx
public void addBookToAuthor() {
Author proxy = authorRepository.getOne(1L);
Book book = new Book();
book.setIsbn("001-MJ");
book.setTitle("The Canterbury Anthology");
book.setAuthor(proxy);
bookRepository.save(book);
}
Since Hibernate can set the underlying foreign key value of an uninitialized proxy, this code triggers a single INSERT statement:
INSERT INTO book (author_id, isbn, title)
VALUES (?, ?, ?)
Obviously, this is better than using findById().
The complete code is available on GitHub
If you liked this article, then you'll my book containing 150+ performance items - Spring Boot Persistence Best Practices.

This book helps every Spring Boot developer to squeeze the performances of the persistence layer.
Opinions expressed by DZone contributors are their own.
Comments