How to Scrape E-Commerce Data With Node.js and Puppeteer
Normalized data is the foundation for all price intelligence projects. This tutorial will cover the basics of how to scrape product information.
Join the DZone community and get the full member experience.
Join For FreeWeb scraping is nothing new. However, the technologies that are used to build websites are constantly developing. Hence, the techniques that have to be used to scrape a website have to adapt.
Why Node.js?
A lot of websites use front-end frameworks like React, Vue.js, Angular, etc., which load the content (or parts of the content) after the initial DOM is loaded. This especially applies to performance-optimized e-commerce websites, where price and production information are loaded asynchronously.
Now, if we access a page like this with PHP, or any other classic server-side language, this content will not be part of the retrieved markup, as we require a browser window for sufficient JavaScript rendering.
This is where Puppeteer comes in. It opens a headless Chrome instance to render a page.
Getting Started – Prerequisites
Let us get started by installing Node.js on our system by initializing a new npm (Node Package Manager) instance. npm allows us to install further packages easily. To begin, run the following command:
npm init
// we can now install our puppeteer instance via npm
npm install puppeteer
With this, we have initialized a new npm instance and installed our headless Chrome browser. At this point, you could also install a DOM parser library to make data extraction a little easier. However, we are going to use the JavaScript built-in querySelector() to parse retrieved HTML.
That's it. We are finished with all the prerequisites. Let's start working on our actual web scraper.
Building the Scraper
Let us create a new file, called index.js and start by importing the previously installed Puppeteer library.
x
const puppeteer = require ('puppeteer');
puppeteer.launch().then (async browser => {
const page = await browser.newPage ();
await page.goto ('https://www.rentomojo.com/noida/furniture/rent-hutch-wardrobe-2-door');
await page.waitForSelector ('.price-box__price');
Next, we launch a new headless Chrome window. The await command tells Puppeteer to wait to proceed to the next line until the related statement is completed. Following this pattern, we open up our e-commerce site and tell the browser to wait until the element that contains all information that we want to scrape is visible.
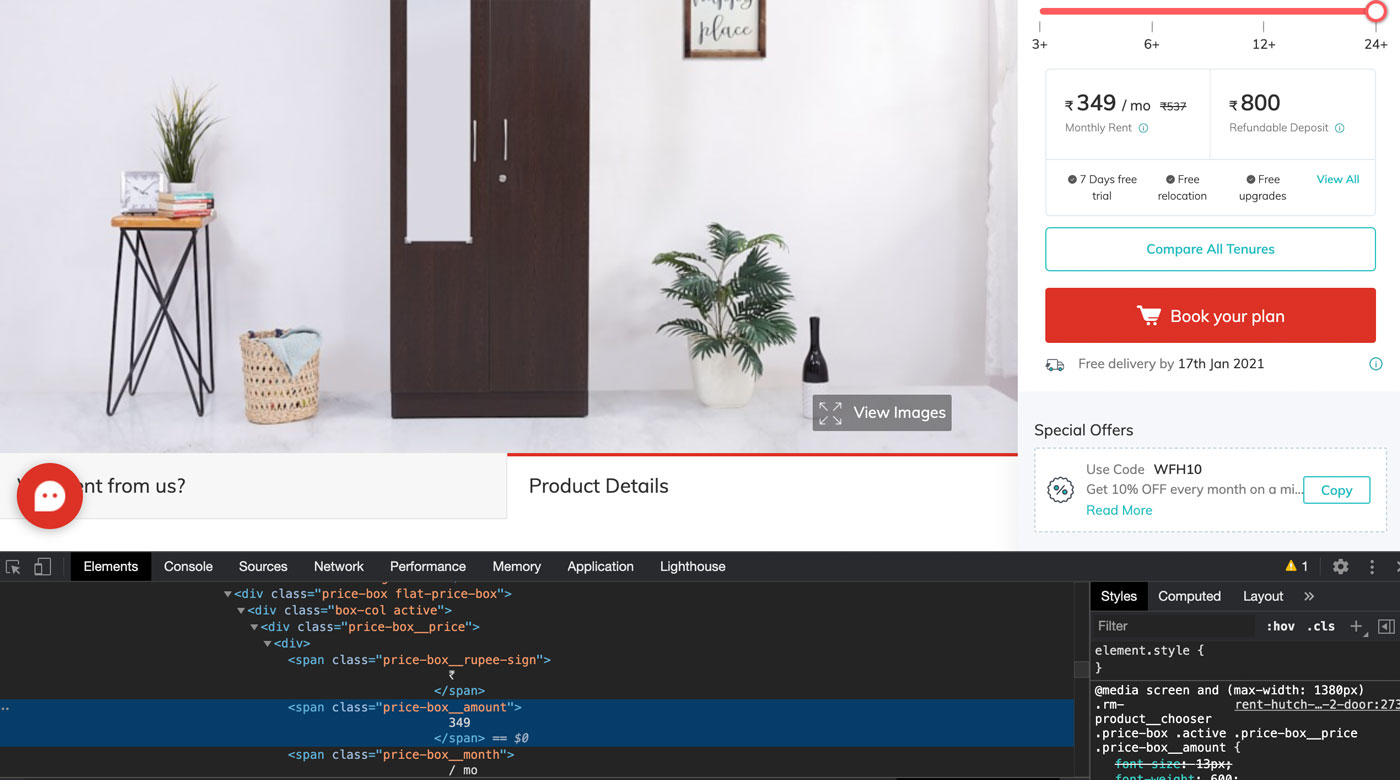
In our case, this element is a div-container, labeled with the price-box__price class. Now the website is in the state where all information that is relevant to us is visible.
As a next step, we are going to use a function called evaluate(). It allows us to interfere with the rendered website, which is what we need to do if we want to scrape it.
x
let priceInformation = await page.evaluate (() => {
let amount = document.body.querySelector('.price-box__amount');
let currency = document.body.querySelector('.price-box__rupee-sign');
let productInfo = {
amount: amount ? amount : null,
currency: currency ? currency : null
};
return productInfo;
});
console.log(priceInformation);
In the code snippet above, we first select the desired product information and save them into the variables amount and currency. Next, we save them to an object and declare null as a fallback value in case the property does not exist.
The console.log() statement will return the gathered information, as shown in the screenshot below:

We now want to get rid of the linebreaks and all spacing. Additionally, we want to convert the property amount to an integer value.
This is the complete and finalized code snippet:
xxxxxxxxxx
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.rentomojo.com/noida/furniture/rent-hutch-wardrobe-2-door');
await page.waitForSelector('.price-box__price');
let priceInformation = await page.evaluate(() => {
let amount = document.body.querySelector('.price-box__amount');
let currency = document.body.querySelector('.price-box__rupee-sign');
function stripString(rawString) {
return rawString.trim();
}
let productInfo = {
amount: amount ? parseInt(stripString(amount.textContent)) : null,
currency: currency ? stripString(currency.textContent) : null
};
return productInfo;
});
// Logging the results
console.log(priceInformation);
// Closing the browser instance
await browser.close ();
});
This will output the data in an expected and well-structured way:

Of course, you would want to scrape a lot more data properties when applying and running this in a serious web project. But this tutorial is about the concept behind it.
This article was used as a basis for the creation of this article.
Opinions expressed by DZone contributors are their own.
Comments