How to Share Data Between Threads in Vert.x
Want to learn more about how to share data between threads in Vert.x? Click here to learn more about multi-threading in Java.
Join the DZone community and get the full member experience.
Join For FreePassing and sharing information or data between threads is an important part of multi-threaded programming. It's even more important in an asynchronous programming architecture when you have to manage the application state.
Vert.x provides synchronous and asynchronous shared data functionality for this need. Shared data allows you to safely share data between different verticles in the same Vert.x instance or across a cluster of Vert.x instances.
Vert.x offers this functionality with Cluster Managers for the clustered environment. As mentioned in How to Run a Vert.x Cluster With Broadcasting Messaging article, the cluster manager is Hazelcast by default in Vert.x, but the cluster managers are pluggable. That means you can use another implementation as the cluster manager if you want. At this point, it is important to remember that the behavior of the distributed data structure depends on the cluster manager that you use.
Now, let's look at the options provided by shared data functionality:
Synchronous shared maps
Asynchronous maps
Asynchronous locks
Asynchronous counters
Other than the first option, you can access the data locally or cluster-wide with these options. The first option only provides local access. We will now focus on the first two of these options.
Local Shared Maps
As mentioned the above, local shared maps are locally accessible. That means that the data can be shared safely between different event loops in the same Vert.x instance.
private void putData(RoutingContext routingContext){
final SharedData sd = vertx.sharedData();
final LocalMap<String, String> sharedData = sd.getLocalMap(DEFAULT_LOCAL_MAP_NAME);
final SimpleData data = Json.decodeValue(routingContext.getBodyAsString(), SimpleData.class);
sharedData.put(data.getKey(), data.getValue());
routingContext.response()
.setStatusCode(201)
.putHeader("content-type", "application/json; charset=utf-8")
.end(Json.encodePrettily(data));
}
In this example, we obtained a SharedData object through the vertx field and then put an object(SimpleData) that received an HTTP Post request into the LocalMap. The LocalMap is obtained by passing the map name to thegetLocalMap method. The SimpleData object is accessible by other event loops in the same Vert.x instance. An example of the use of local shared data can be found in this repository.
Vert.x restricts you to the types of data used with local shared maps for thread safety. You can use either immutable or certain other types that can be copied, like Buffer. In this way, you can ensure that there is no shared access to a mutable state between different threads in your application.
Asynchronous Shared Maps
Asynchronous shared maps allow you to put and retrieve the data locally and cluster-wide. When Vert.x is clustered, you can be put the data from any node and retrieved from the same node or any other node.
This feature is the perfect solution for managing the application state we mentioned at the beginning.
@Override
public void start() throws NoSuchAlgorithmException {
final Random random = SecureRandom.getInstanceStrong();
final SharedData sharedData = vertx.sharedData();
vertx.setPeriodic(3000, h ->
sharedData.<String, StockExchange>getAsyncMap(DEFAULT_ASYNC_MAP_NAME, res -> {
if (res.succeeded()) {
AsyncMap<String, StockExchange> myAsyncMap = res.result();
myAsyncMap.get(DEFAULT_ASYNC_MAP_KEY, asyncDataResult -> {
LocalDateTime dateTime = LocalDateTime.now();
StockExchange stockExchange = new StockExchange(String.join(":", String.valueOf(dateTime.getHour()),
String.valueOf(dateTime.getMinute()), String.valueOf(dateTime.getSecond())),
Arrays.asList(new StockExchangeData(KODCU_STOCK_NAME, random.nextInt(100)),
new StockExchangeData(JUG_IST_STOCK_NAME, random.nextInt(100))));
myAsyncMap.put(DEFAULT_ASYNC_MAP_KEY, stockExchange, resPut -> {
if (resPut.succeeded()) {
log.info("Added data into the map {} ", Json.encodePrettily(stockExchange));
} else {
log.debug("Failed to add data {} ", Json.encodePrettily(stockExchange));
}
});
});
} else {
log.debug("Failed to get map!");
}
}));
}In this example, we request a map with the getAsyncMap method that returned an instance of the AsyncMap. If the request succeeded, we put an object(StockExchange) that has values generated randomly every three seconds into the map with the same key. Another application in a clustered environment can be accessed by the map with the same value and handle it.
You can find an example of the use of asynchronous shared maps in this repository under the SharedDataProvider and SharedDataReader directories. The SharedDataReader reads the data that's generated by the SharedMapsProvider in a clustered environment every second and displays it in a chart component on the front-end.
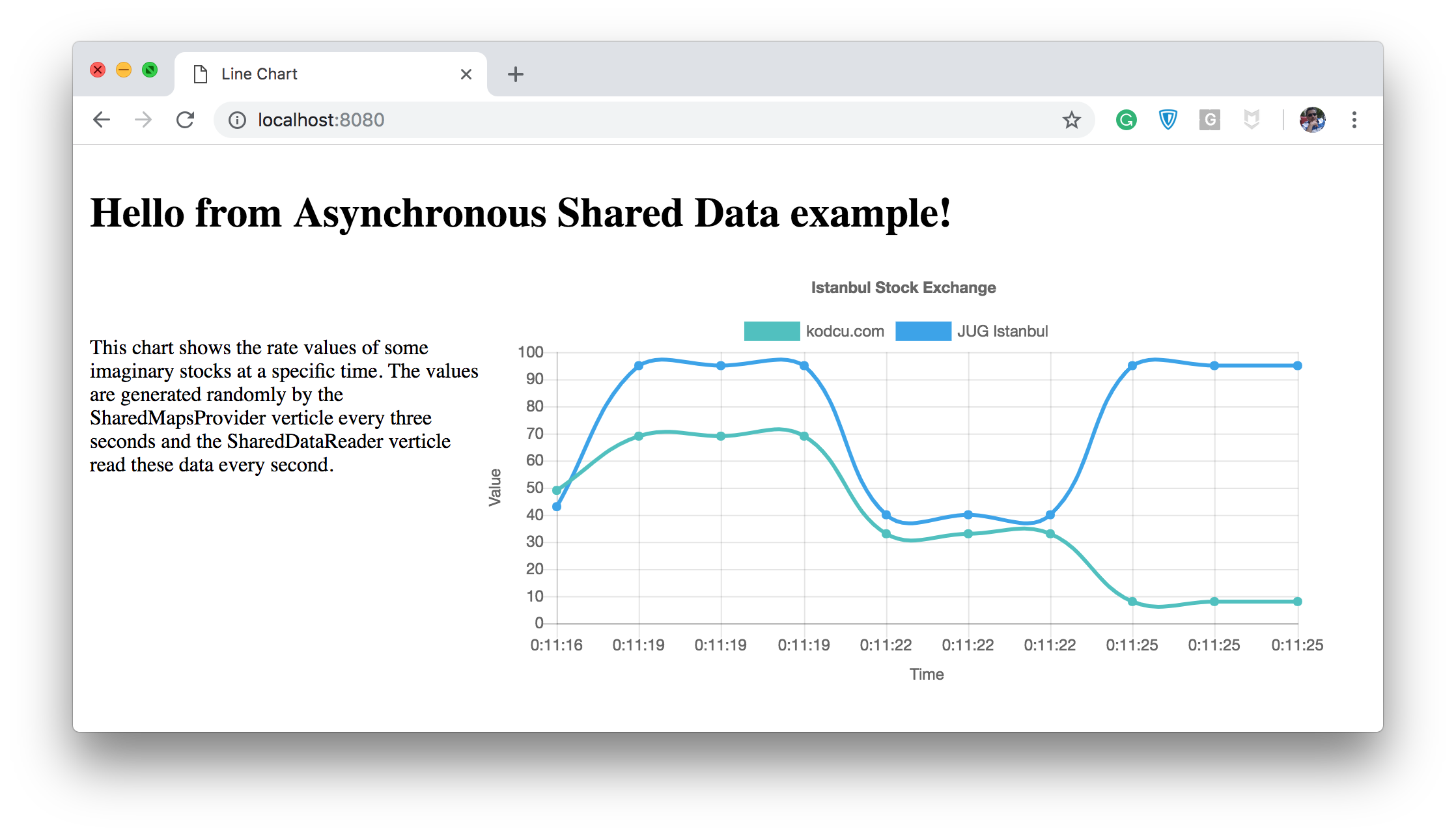
Conclusion
Sharing data between threads is an important issue in multi-threaded programming. Vert.x solves this problem with synchronous and asynchronous shared data functionality. The asynchronous shared data feature is especially important for the clustered environment. With that feature, for example, you can store and distribute session state of your servers in a Vert.x web application. This is a perfect solution for the need that's managing the application state that we mentioned at the beginning of this article. Happy coding!
References:
Opinions expressed by DZone contributors are their own.
Comments