How to Trace Linux System Calls in Production (Without Breaking Performance)
Good, lightweight tracing.
Join the DZone community and get the full member experience.
Join For Free
If you need to dynamically trace Linux process system calls, you might first consider strace. strace is simple to use and works well for issues such as "Why can't the software run on this machine?" However, if you're running a trace in a production environment, strace is NOT a good choice. It introduces a substantial amount of overhead. According to a performance test conducted by Arnaldo Carvalho de Melo, a senior software engineer at Red Hat, the process traced using strace ran 173 times slower, which is disastrous for a production environment.
So are there any tools that excel at tracing system calls in a production environment? The answer is YES. This blog post introduces perf and traceloop, two commonly used command-line tools, to help you trace system calls in a production environment.
perf, a performance profiler for Linux
perf is a powerful Linux profiling tool, refined and upgraded by Linux kernel developers. In addition to common features such as analyzing Performance Monitoring Unit (PMU) hardware events and kernel events, perf has the following subcomponents:
- sched: Analyzes scheduler actions and latencies.
- timechart: Visualizes system behaviors based on the workload.
- c2c: Detects the potential for false sharing. Red Hat once tested the c2c prototype on a number of Linux applications and found many cases of false sharing and cache lines on hotspots.
- trace: Traces system calls with acceptable overheads. It performs only 1.36 times slower with workloads specified in the
ddcommand.
Let's look at some common uses of perf.
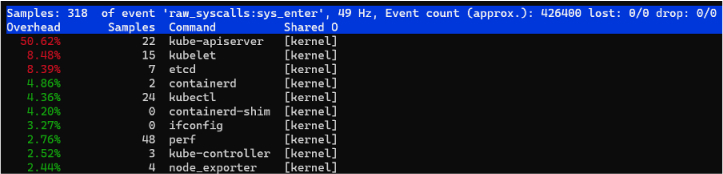
To see which commands made the most system calls:
Shell
xxxxxxxxxx1
1perf top -F 49 -e raw_syscalls:sys_enter --sort comm,dso --show-nr-samples
![]() System call counts
System call countsFrom the output, you can see that the
kube-apiservercommand had the most system calls during sampling.To see system calls that have latencies longer than a specific duration. In the following example, this duration is 200 milliseconds:
Shell
xxxxxxxxxx1
1perf trace --duration 200
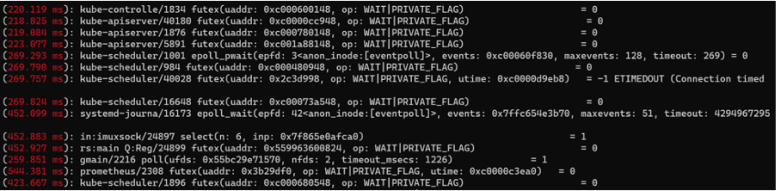
![]() System calls longer than 200 ms
System calls longer than 200 msFrom the output, you can see the process names, process IDs (PIDs), the specific system calls that exceed 200 ms, and the returned values.
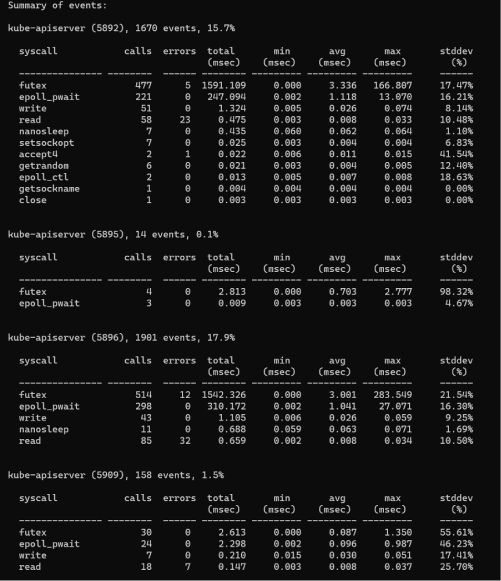
To see the processes that had system calls within a period of time and a summary of their overhead:
Shell
xxxxxxxxxx1
1perf trace -p $PID -s
![]() System call overheads by process
System call overheads by processFrom the output, you can see the times of each system call, the times of the errors, the total latency, the average latency, and so on.
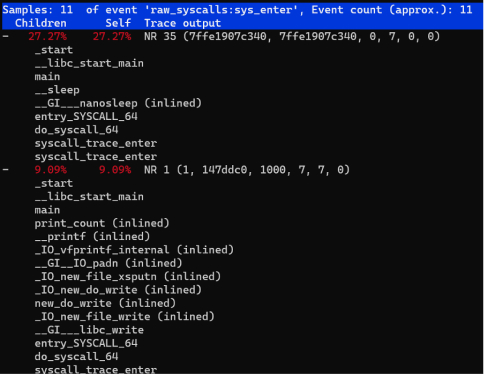
To analyze the stack information of calls that have a high latency:
Shell
xxxxxxxxxx1
1perf trace record --call-graph dwarf -p $PID -- sleep 10
![]()
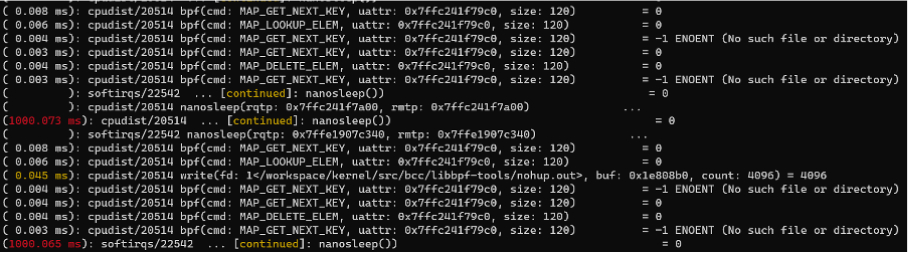
Stack information of system calls with high latency To trace a group of tasks. For example, two BPF tools are running in the background. To see their system call information, you can add them to a
perf_eventcgroup and then executeper trace:Shell
xxxxxxxxxx1
1mkdir /sys/fs/cgroup/perf_event/bpftools/2echo 22542 >> /sys/fs/cgroup/perf_event/bpftools/tasks3echo 20514 >> /sys/fs/cgroup/perf_event/bpftools/tasks4perf trace -G bpftools -a -- sleep 10
![]()
Trace a group of tasks
Those are some of the most common uses of perf. If you'd like to know more (especially about perf-trace), see the Linux manual page. From the manual pages, you will learn that perf-trace can filter tasks based on PIDs or thread IDs (TIDs), but that it has no convenient support for containers and the Kubernetes (K8s) environments. Don't worry. Next, we'll discuss a tool that can easily trace system calls in containers and in K8s environments that uses cgroup v2.
Traceloop, a performance profiler for cgroup v2 and K8s
Traceloop provides better support for tracing Linux system calls in the containers or K8s environments that use cgroup v2. You might be unfamiliar with traceloop but know BPF Compiler Collection (BCC) pretty well. (Its front-end is implemented using Python or C++.) In the IO Visor Project, BCC's parent project, there is another project named gobpf that provides Golang bindings for the BCC framework. Based on gobpf, traceloop is developed for environments of containers and K8s. The following illustration shows the traceloop architecture:

We can further simplify this illustration into the following key procedures. Note that these procedures are implementation details, not operations to perform:
bpf helpergets the cgroup ID. Tasks are filtered based on the cgroup ID rather than on the PID and TID.- Each cgroup ID corresponds to a bpf tail call that can call and execute another eBPF program and replace the execution context. Syscall events are written through a bpf tail call to a perf ring buffer with the same cgroup ID.
- The user space reads the perf ring buffer based on this cgroup ID.
Note:Currently, you can get the cgroup ID only by executing
bpf helper: bpf_get_current_cgroup_id, and this ID is available only in cgroup v2. Therefore, before you use traceloop, make sure that cgroup v2 is enabled in your environment.
In the following demo (on the CentOS 8 4.18 kernel), when traceloop exits, the system call information is traced:
xxxxxxxxxx
sudo -E ./traceloop cgroups --dump-on-exit /sys/fs/cgroup/system.slice/sshd.service
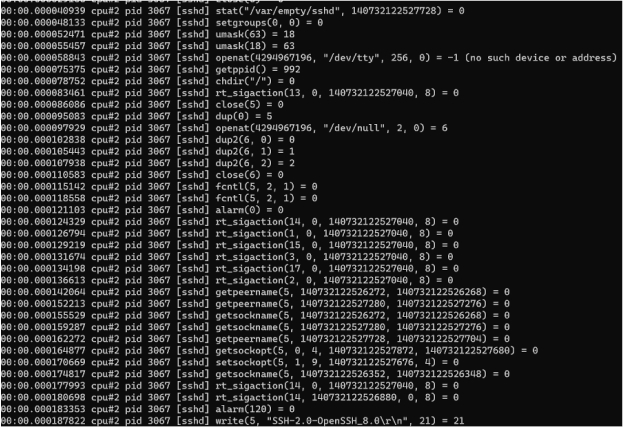
As the results show, the traceloop output is similar to that of strace or perf-trace except for the cgroup-based task filtering. Note that CentOS 8 mounts cgroup v2 directly on the /sys/fs/cgroup path instead of on /sys/fs/cgroup/unified as Ubuntu does. Therefore, before you use traceloop, you should run mount -t cgroup2 to determine the mount information.
The team behind traceloop has integrated it with the Inspektor Gadget project, so you can run traceloop on the K8s platform using kubectl. See the demos in Inspektor Gadget - How to use and, if you like, try it on your own.
Benchmark with system calls traced
We conducted a sysbench test in which system calls were either traced using multiple tracers (traceloop, strace, and perf-trace) or not traced. The benchmark results are as follows:
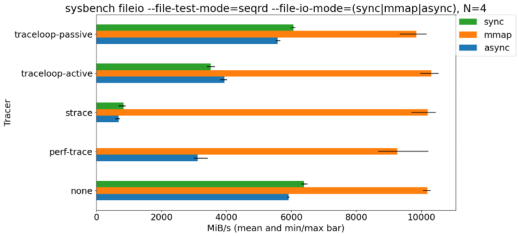
As the benchmark shows, strace caused the biggest decrease in application performance. perf-trace caused a smaller decrease, and traceloop caused the smallest.
Summary of Linux profilers
For issues such as "Why can't the software run on this machine," strace is still a powerful system call tracer in Linux. But to trace the latency of system calls, the BPF-based perf-trace is a better option. In containers or K8s environments that use cgroup v2, traceloop is the easiest to use.
Published at DZone with permission of Wenbo Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments