Look, Ma! No Pods!
Microservices CI/CD with GitLab and HashiCorp Nomad.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Release Automation is the cornerstone of modern Software Delivery. Well-established CI/CD pipelines are fundamental to every organization that wants to embrace DevOps/GitOps methodologies in order to achieve:
- Frequent, rapid release cycles.
- Fully automated deployment and rollback based on deployment strategies (Rolling Updates, Canary Releases, Blue/Green deployment).
- Continuous-integration with automated testing.
- More resources devoted to automated testing than manual testing.
The benefits of CI/CD for businesses undoubtedly should be the first priority no matter what kind of 'Agile' or other methodology is used for project management. Articles like Benefits of Continuous Integration for Businesses and IT Teams or Why the World Needs CI/CD, explain the importance for all stakeholders.
As very well stated in Deloitte Engineering Semantic Versioning with Conventional Commits article, the deficiencies usually encountered when trying to apply CI/CD, are:
- Lack of unambiguous developer and release processes.
- Poor tooling support.
If the developers sit wondering how to do certain tasks, then the process is broken. They should know how to release a new version or how to hotfix production while the trunk (or "master" branch) has moved on. And your CI/CD processes should support these scenarios.
Nowadays, since many companies have embraced microservices architectures and there are no Application Servers managing deployments, there is a need for the proper tooling to manage the lifecycle of multiple microservices instances regardless of their technology stack. Creating and maintaining manually things like deploy scripts, static network configurations (IPs, ports, etc.) are (or rather should be) a thing of the past.
An obvious solution to meet the above requirements is to adopt Docker, Containers, and Kubernetes. However, like most things in IT, there is no 'one size fits all' approach and while Kubernetes is of course a mature and well-established solution, it is not a panacea.
In this article we will demonstrate an opinionated CI/CD approach which can be further extended and adapted to suit different needs and is based on:
- GitLab for source code management and CI server (utilizing GitLab runners).
- GitLab flow as our branching strategy and Git workflow.
- semantic-release for automating versioning, release notes, and tagging.
- Maven CI Friendly Versions for dynamic versioning or our Maven-based microservices.
- HashiCorp Nomad and Consul instead of Kubernetes for deployments and service discovery.
- HashiCorp Levant is an open-source templating and deployment tool for Nomad jobs.
Let's dive into it. We will begin by answering the question 'why Nomad?'
Why Nomad?
There are many articles out-there tackling this question coming from heterogeneous sources. Here is a short-list:
- Nomad: The workload orchestrator you may have missed by Verifa.
- Nomad — our experiences and best practices by Trivago.
- How we use HashiCorp Nomad by Cloudflare.
- Microservices with Nomad and Consul by Codecentric.
- How the Internet Archive Migrated from Kubernetes to Nomad & Consul by the 'Internet Archive.'
You are encouraged to check them out both for an introduction to Nomad and a comparison with Kubernetes.
For the impatient, the bottom line is that while Kubernetes has become the de-facto orchestrator in the market and might be able to meet all of your requirements, it is not the most straightforward tool to adopt. It comes with a quite large ecosystem and tooling that require experience and significant effort to select, setup, and maintain, often providing way more features than what teams might typically need. Using a managed Kubernetes service (such as those provided by Google, Amazon, and Azure) greatly simplifies the operations side of a Kubernetes cluster, but it still requires some fundamental in-house knowledge that needs to be developed.
Nomad by HashiCorp (first released in 2015) is a workload orchestrator that provides a wide variety of capabilities with one very noteworthy trait: it is straightforward to deploy. It is less intrusive by design, as Nomad only delivers the function that you might be looking for in an orchestrator — namely deploying and managing applications. Let's highlight some of its important features:
- Supports both containerized and non-containerized applications: Docker containers and 'Pods' are not a 'must'. Nomad has the concept of Task Drivers and through them provides other means of achieving resource isolation and grouping of deployable units of work.
- Has the concept of active state VS desired state: for each deployment unit (e.g. a microservice), we need to provide a Nomad job specification file, written in HCL. When we submit a job to the Nomad server (usually via a CI pipeline), we initiate the desired state. The job specification defines that we want to run a task. A task creates an individual unit of work, such as a Docker container, a standalone JAR, a Golang or Python executable, etc. This unit of work is deployed a certain number of times and under specific constraints. The actual state can be changed either by a planned event (deploy of a new job) or an emergent event (node failure). This means that Nomad must evaluate the current state, compare it with the desired state defined in the jobs specification, and plan all the necessary actions in order to achieve it. For more details see Scheduling in Nomad.
- Performs intelligent Bin Packing: Nomad analyzes the capabilities of all the nodes forming a cluster and are deployment targets. Then, based on each job's requirements it deploys and distributes running instances (named allocations) in an efficient manner. Its workload placement strategy does not allow backup/redundant jobs to be on the same piece of infrastructure, where an outage could cause that job to become unavailable (Anti-Affinity)
- Supports hybrid clusters: you can have a part of your cluster hosted on-premise and a part hosted in one or more Cloud providers (hybrid cloud).
Here is a rough comparison table between Kubernetes and Nomad:
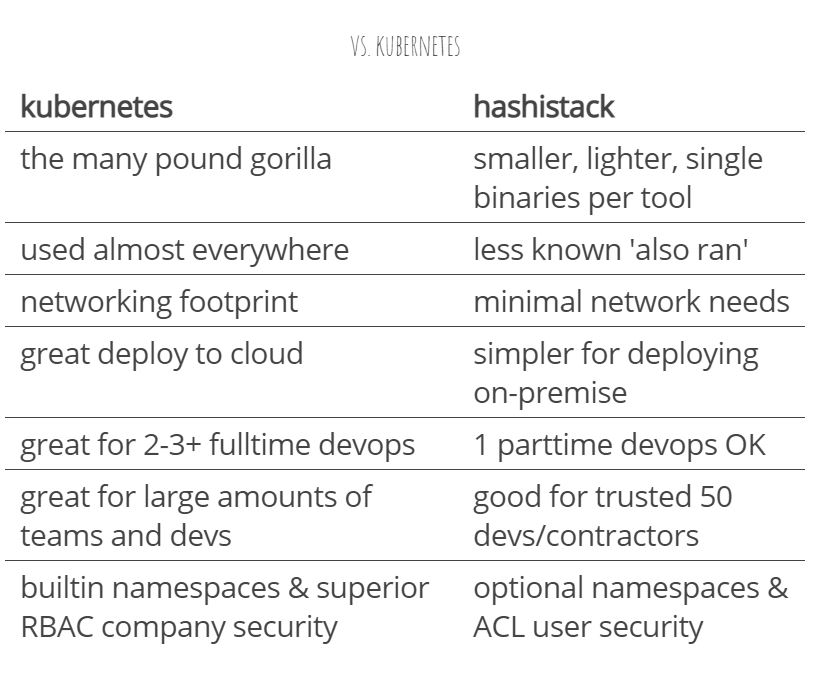 Image source: https://archive.org/~tracey/slides/gitlab-commit/#/39
Image source: https://archive.org/~tracey/slides/gitlab-commit/#/39
One reported Nomad 'missing' feature (compared to Kubernetes) was until recently the lack of auto-scaling capabilities. However, with the introduction of the Nomad Autoscaler, there is now support for:
- Horizontal Application Autoscaling.
- Horizontal Cluster Autoscaling.
- Dynamic Application Sizing (this is currently given only in the Enterprise edition).
Moreover, Nomad can be easily combined with other solutions of the so-called HashiStack (aka The HashiCorp Stack) like Consul for Service Discovery, Centralized Configuration Management, and Service Mesh capabilities, Vault for Secrets Management, and tools like Levant which is is an open-source templating and deployment tool for Nomad that provides real-time feedback and detailed failure messages upon deployment issues. Last but not least, Nomad comes with a rich Web-based admin console, a CLI, and a REST API thus making it easily manageable both in a manual (human operator) and in an automated fashion (CI server during the execution of CI/CD pipelines).
The key takeaway from this section is that although there are cases of companies totally switching from Kubernetes to HashiStack for their own reasons, it doesn't mean that there is such a necessity if you have everything setup and running smoothly operation-wise and cost-wise. However, for those teams which have not yet begun their Kubernetes adventures, or those who only need 10% of Kubernetes and want something with a more thriving community than what Docker Swarm provides, then Nomad is a great option.
In the following sections we will show how we can use Nomad, Levant and Consul combined with CI/CD pipelines for automated releases to 'staging' and 'production' environments.
Example Project
We want to automate the deployment of 3 Java-based microservices:
- A gateway service that is based on Spring Cloud Gateway and is going to be deployed as a Docker container.
- A 'legacy' customer service that is a typical Spring Boot app offering a REST API and is going to be deployed as a standalone Jar.
- A one-time password (OTP) service that has similar requirements as the customer-service above but it requires more instances when running on Production.
Requirements
We want to achieve the following automation:
- each time something is pushed to a 'feature' branch, the project needs to be built, tested (i.e. to run its Unit and/or Integration Tests), and checked for code coverage, code quality, security standards, etc.
- each time a feature branch is merged to a 'pre-release' branch, we need to obtain a new 'beta' version number automatically, publish the artifact onto either a Docker or Maven registry and deploy it for manual testing on a Staging environment
- each time a 'pre-release' branch is merged to the master branch, we need to obtain a new 'official' release version number automatically, publish the artifact onto either a Docker or Maven registry, create a tag and release notes automatically and deploy it to the Production environment using a deployment strategy (e.g. Rolling updates)
Projects Structure
Each microservice is a separate GitLab Project and has its own repository. In the root folder of each project, the following files exist:
.gitlab-ci.yml: which contains the CI/CD configuration (see here)..releaserc.json: which contains the configuration of the semantic-release (see here).- an HCL (HashiCorp Configuration Language) file (gateway.hcl, customer.hcl, otp.hcl) where we define our Nomad Job Specification.
- 2 YAML files:
staging.ymlandproduction.ymlwhich contain environment-specific values and will be interpreted by Levant when submitting jobs to Nomad.
Environments Overview
For the shake of a demo, we have used Google Cloud Platform (GCP) and provisioned a number of VM instances:
- A GitLab server (1 VM).
- A pool of GitLab runners (2 VMs) with Levant and semantic-release installed on them. For semantic-release, we have enabled the following additional plugins:
- A Nomad server for 'Production' usage (1 VM). For real production usage, a cluster of 3, 5, or 7 nodes is recommended (see reference diagram below).
- A Consul server for 'Production' usage (1 VM). For real production usage, a cluster of 3, 5, or 7 nodes is recommended (see reference diagram below).
- A pool of instances that will host the microservices for 'Production' usage (4 VMs). These instances have the following things pre-installed:
- Nomad client.
- Consul client.
- Java OR Docker.
- A staging server (1 VM) which hosts the following components:
- Nomad and Consul server.
- A test instance VM which will host all the microservices and will be used for QA and testing purposes. This comes with the following things pre-installed:
- Nomad client.
- Consul client.
- Java AND Docker.
- A single VM with JFrog Artifactory installed that will serve as our Maven Registry.
Note: as Docker Registry we will use Docker Hub. Keep in mind that the latest versions of GitLab do support both Maven and Docker registries so it's recommended to check these out before bringing in more dependencies to your infrastructure.
In general and for real-production usage one should follow the Nomad Reference Architecture and Consul Reference Architecture. Moreover, if you have adopted Terraform and IaC (Infrastructure as Code), there are Terraform modules for provisioning Nomad and Consul clusters which you can lookup in Terraform Registry.
For quick reference, here is a typical single region Nomad/Consul cluster topology diagram:

{kind=link}
In our case, the topology is depicted in the following diagram:

CI/CD Pipeline
Let's see now how everything blends in, starting with a diagram of our CI/CD pipeline applicable per microservice:
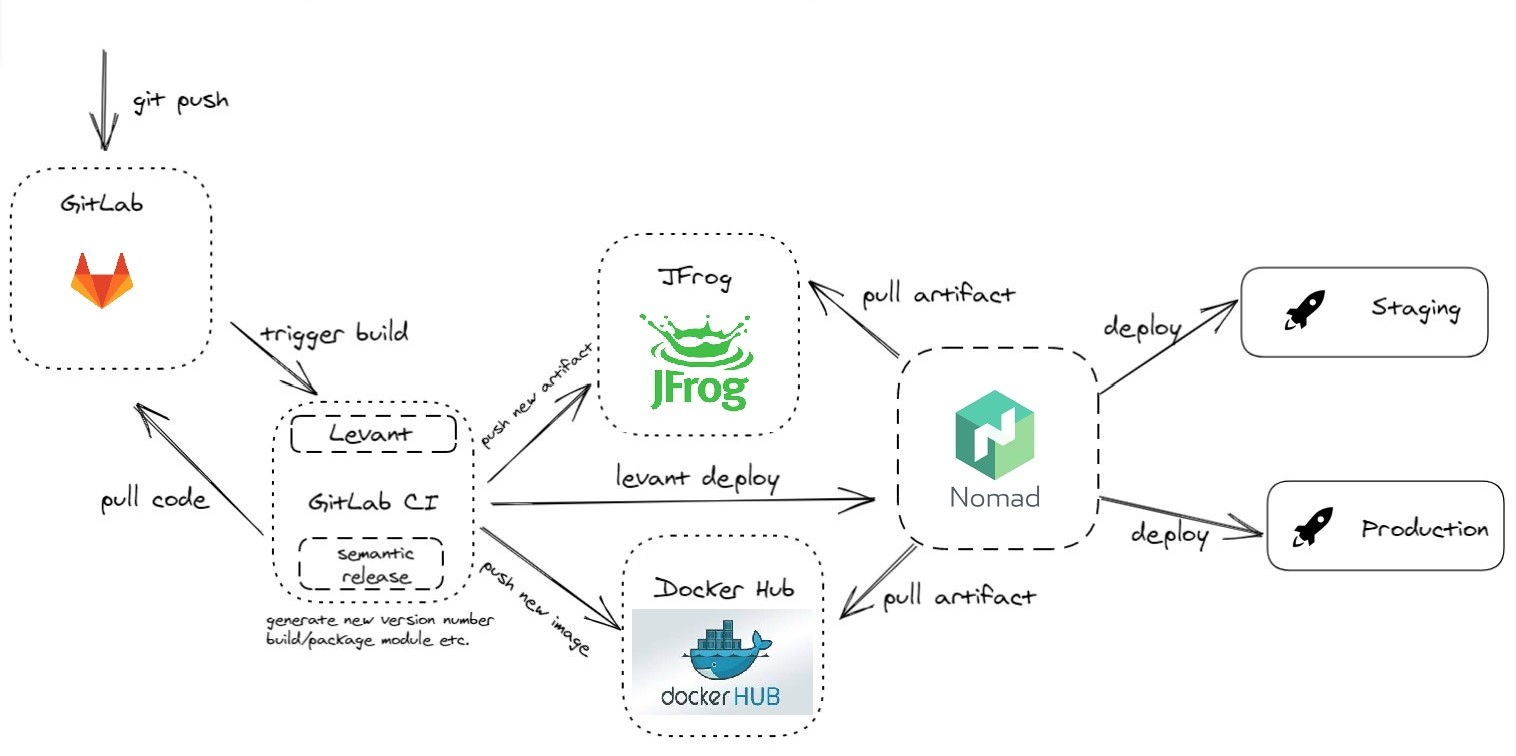
First of all, we need to clarify that we go with GitLab Flow and the semantic-release recipe as described here. You are encouraged to have a look at them if not already familiar. As mentioned above we have installed the @semantic-release/gitlab plugin. We have also authorized semantic-release (via a GITLAB_CI token) to perform actions on the repository, like creating releases and tags.
Now, let's say we have a master branch and we want to plan a new release. We create a branch named beta from the master branch. We can create other sub-branches from beta and work normally. Now, when there is a merge-request to beta and the merge is done, the following actions take place:
- GitLab runner executes a 'version' stage. The semantic-release plugin determines a new 'beta' version number (e.g. 1.0.0-beta.1) and exports it to a file-based GitLab environment variable in order to be visible and used by subsequent pipeline stages.
- Then we move on to the 'publish' stage where the artifact is built using the Maven CI Friendly plugin and on-success it gets published to either JFrog Maven Registry or to Docker Hub container registry.
- Finally, we proceed to deploy to the Staging environment using Levant.
If everything is tested OK on the Staging server and we want to proceed to a production release, we make a merge-request from beta to master branch. Once the merge is done, a similar pipeline is executed but this time semantic-release plugin generates a proper 'release' version number (e.g., 1.0.0) and the deployment takes place on the Production environment. Moreover, semantic-release has created Release notes for us in GitLab and has created a proper Git Tag!
Let's wrap it up and watch all these in action, at the following YouTube screencast.
Demo Screencast
YouTube link: https://www.youtube.com/watch?v=cgEa0ANN230
Scenarios demonstrated:
- Deploy a containerized app (gateway-service) to staging and production.
- Deploy a legacy standalone jar app (otp-service) to staging and production with multiple instances and a Rolling Updates strategy.
- Code navigation, having a look at most important files:
- the
.gitlab-ci.ymlwhich defines the CI/CD pipeline of each microservice. - the nomad job files (
gateway.hclandotp.hcl). - environment variables files (
staging.ymlandproduction.yml).
- the
Opinions expressed by DZone contributors are their own.
Comments