ID vs. Multimodal Recommender System: Perspective on Transfer Learning
This article reviews the development status of transferable recommendation systems and representative work — ID-based, modality-based, and large language model-based.
Join the DZone community and get the full member experience.
Join For Free1. The Development of Transferable Recommender Systems
The core goal of recommender systems is to predict the most likely next interaction by modeling the user's historical behavior. This goal is particularly challenging when there is limited user interaction history, which has long plagued the development of recommender systems, known as the cold-start problem. In cold-start scenarios, such as in newly established recommendation platforms with limited interaction sequences for new users, the early stages of model training often suffer from a lack of sufficient sample data. Modeling with limited training data inevitably results in unsatisfactory user recommendations, hindering the growth of the platform. Transfer learning is a solution that both the academic and industrial communities have focused on to address this issue. Introducing pre-trained knowledge into downstream scenarios will greatly alleviate the cold-start problem and help to model user interactions.
Therefore, research on transferable recommender systems has been almost continuous throughout every stage of the development of the recommender systems field. From the era of matrix factorization based on item IDs and user IDs, transferable recommender systems had to achieve transfer learning for ID-based recommender systems based on data overlapping from both source and downstream scenarios. In recent years, there has been rapid development in multimodal understanding technology. Researchers are gradually shifting their focus to modeling user sequences using pure modal information, achieving transferable recommendations even in scenarios where there is no data overlapping between source and downstream scenarios. Currently, ‘one-for-all’ recommender systems that use large language models (LLM) have received a lot of attention. Exploring transferable recommender systems and even foundation models for recommender systems has emerged as the next frontier in the field of recommender systems.
2. ID-Based Transferable Recommender Systems
The first stage was the era of matrix factorization, where the use of ID embeddings to model items in collaborative filtering algorithms was the dominant paradigm in the recommender systems field and dominated the entire recommendation community for almost 15 years. Classic architectures include dual-tower architecture, CTR models, session and sequence recommendations, and Graph networks. They all use ID embeddings to model items, and the existing state-of-the-art (SOTA) recommender systems largely rely on modeling based on ID features.
During this stage, transferable recommender systems naturally depended on IDs, and there was a requirement for data overlap between source and downstream scenarios. This implies that there needed to be shared users or items between different datasets. For example, in large companies with multiple business scenarios, it is necessary to drive new businesses through the inflow generated by existing businesses. Early works in this stage include PeterRec [1] (SIGIR 2020), Conure [2] (SIGIR 2021), and CLUE [3] (ICDM 2021).
PeterRec is the first paper in the field of recommender systems to explicitly claim the universality of user representations based on self-supervised pre-training (auto-regressive and mask language models). It clearly demonstrates that these pre-trained universal representations can be used for cross-domain recommendations and user profile prediction, significantly improving performance. The evaluation of the universality of user representations through user profile prediction has been widely adopted in subsequent related papers. Furthermore, PeterRec has also released a large-scale cross-domain recommender systems dataset.
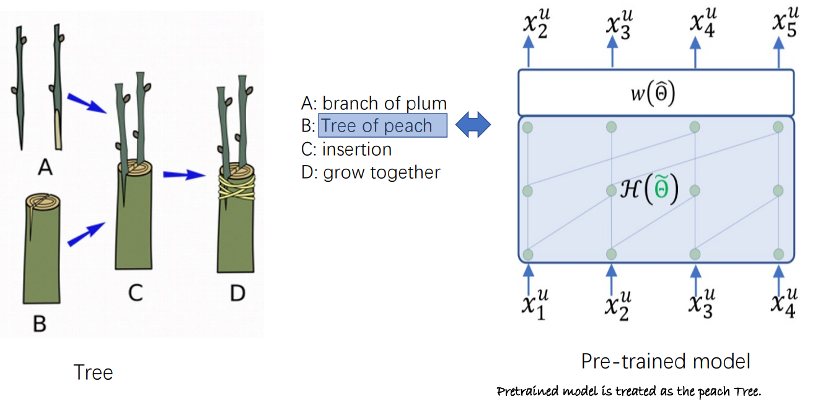
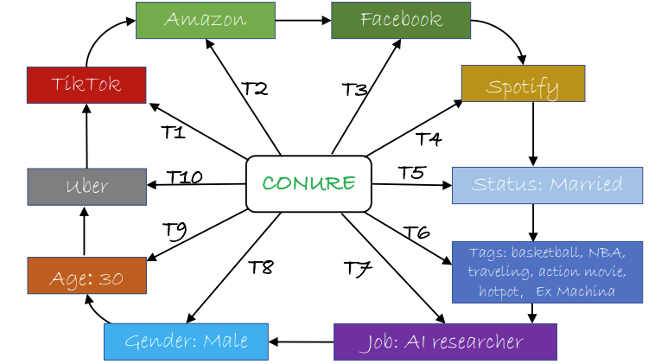
Conure is the first lifelong learning model for user universal representation in the field of recommender systems. It introduces a model that continuously learns and serves multiple different downstream tasks simultaneously. The concept of "one person, one world" proposed by the authors has inspired current research in recommender systems, especially the study of one4all models.
CLUE believes that both the PeterRec and Conure algorithms use autoregressive or masking mechanisms when learning user representations, which are item-based predictions. However, the optimal user representation should clearly model and train on the complete user sequence. Therefore, by combining contrastive learning, better results can be obtained.
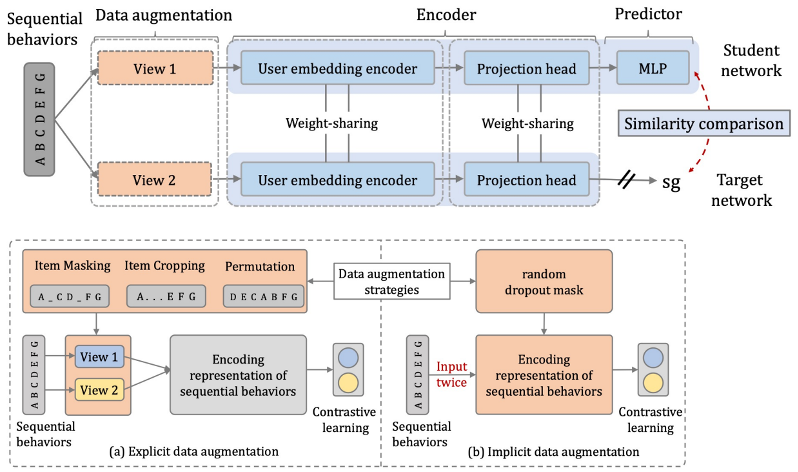
During this period, there are some concurrent or future work, including Alibaba's Star model (One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction) and ShopperBERT model (One4all User Representation for Recommender Systems in E-commerce).
3. Transferable Recommender Systems Based on Modal Information
The aforementioned research relies on the sharing of (user or item) IDs to achieve transferable recommender systems between different domains. This approach is well-suited for intra-business transfers within a single company. However, in reality, it is challenging for different recommender systems to share user and item ID information, leading to significant limitations in studies related to cross-platform recommendations.
In contrast, other deep learning communities, such as Natural Language Processing (NLP) and Computer Vision (CV), have witnessed the emergence of influential universal large models, also known as foundation models, in recent years. Examples include BERT, GPT, Vision Transformer, and more. Unlike ID features used mainly in the recommender systems field, NLP and CV tasks are based on multimodal text and image pixel features, which enable better reuse and transfer of models across different tasks. The mainstream direction in this phase involves replacing ID features with modal content to facilitate transfer between different systems and platforms. Representative works in this phase include TransRec [4], MoRec [5] (SIGIR 2023), AdapterRec [6] (WSDM 2024) and NineRec [7].
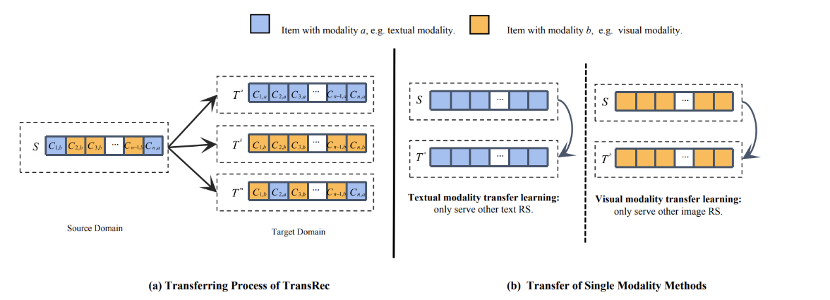
TransRec is the first recommender system model that explores mixed-modal-based transfer learning. It is also the first model to consider the transfer of image pixel information. TransRec employs an end-to-end training approach rather than directly extracting offline multimodal item representations. Compared to ID-based sequential recommendation models, fine-tuned TransRec can effectively improve recommendation results. TransRec demonstrates that pretraining on large-scale data using mixed-modal information can effectively learn the relationships between users and items and transfer this knowledge to downstream tasks, achieving general recommendation capabilities. The paper also investigates the scaling effect and plans to release multiple multimodal datasets.
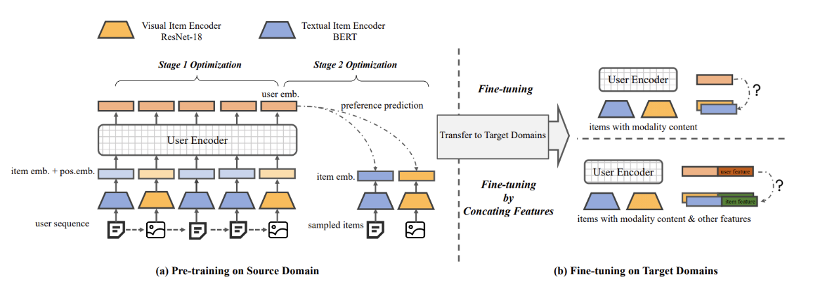
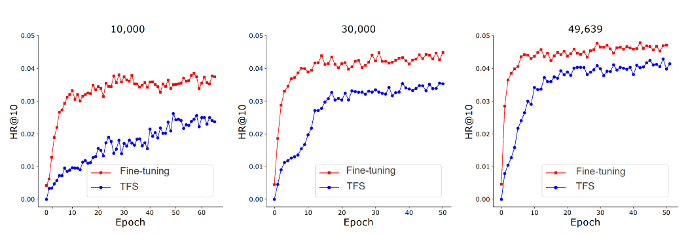
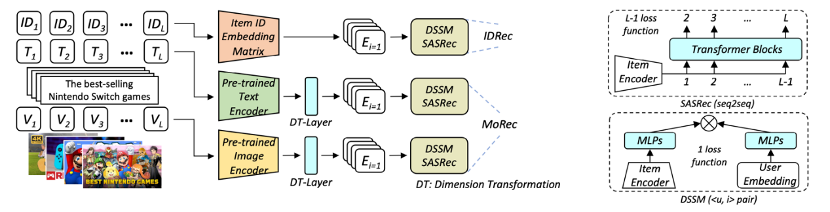
MoRec provides a systematic answer to the question of whether using state-of-the-art modal encoders to represent items (MoRec) can replace the classical item ID embedding paradigm (DRec). The paper conducts fair comparisons between MoRec and IDRec, suggesting that if MoRec can outperform IDRec in both cold and hot scenarios, it will revolutionize the classical paradigm in the field of recommender systems. This perspective comes from MoRec modeling users entirely based on item modal information. Such content information inherently possesses transferability, and the paper systematically demonstrates through solid experiments that MoRec has the potential to achieve a universal large model.
Conclusion 1
For the sequential recommendation architecture SASRec, in typical scenarios (where there are both popular and less-known items), MoRec significantly outperforms IDRec in text-based recommendations but performs comparably to IDRec in image-based recommendations. In cold start scenarios, MoRec substantially outperforms IDRec, while in recommendations for popular items, MoRec and IDRec perform comparably.
Conclusion 2
MoRec establishes a connection between the recommender systems and the NLP, CV, and multimodal communities, generally benefiting from the latest developments in NLP and CV fields.
Conclusion 3
The popular two-stage offline feature extraction recommendation approach in the industry leads to a significant drop in MoRec's performance, especially in visual recommendations, which should not be overlooked in practice. Despite the revolutionary success of pretraining models in the multimodal domain in recent years, their representations are not yet universal and generalizable, at least for recommender systems. This work has sparked inspiration and has led to various related research efforts in recent times.
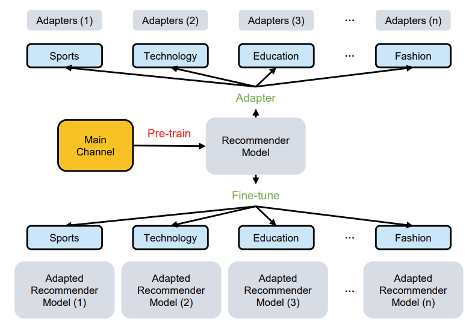
AdapterRec provides the first systematic discussion of efficient transfer methods based on modal information. The paper evaluates model patches based on adapters. Unlike previous approaches that fine-tune all parameters for downstream transfer, AdapterRec inserts and fine-tunes adapter networks within the model network during transfer. The paper conducts extensive validation experiments on large-scale text and image modal data.
The results show that adapterRec based on text and image modalities both achieve good transfer effects. In the textual scenario, adapterRec can achieve transfer results similar to fine-tuning all parameters at a much lower computational cost. AdapterRec confirms that efficient transfer methods based on adapter technology are a crucial component for building universal large models for recommender systems.
NineRec introduces the largest and most diverse multimodal transfer learning dataset to date in the field of recommender systems. Following the principles of fair comparison between MoRec and IDRec, the paper systematically evaluates the transfer capabilities of MoRec and provides detailed guidance and assessment platforms. NineRec offers a large-scale pretraining dataset (with 2 million users, 144 thousand items, and 24 million user-item interactions) and nine downstream scenario datasets (including five from the same platform with different scenarios and four from different platforms).
The paper conducts large-scale experiments to evaluate the transfer performance of various classic recommendation architectures (SASRec, BERT4Rec, NextItNet, GRU4Rec) and item encoders (BERT, Roberta, OPT, ResNet, Swin Transformer). It also verifies the impact of end-to-end and two-stage approaches on cross-domain recommendations. The experimental results show that end-to-end training techniques can greatly unleash the potential of modal information, and even using classical frameworks like SASRec can surpass recent similar transferable recommendation models. The paper also confirms the zero-shot transfer capability based on pure modal information.
NineRec provides a new platform and benchmark for model-based recommender system transfer learning and the development of large recommendation models. Following NineRec (text and image modalities only), the team jointly released the MicroLens dataset [10], which is the largest short video recommendation dataset to date. It includes original short videos and is thousands of times larger in scale than other related datasets, with 30 million users and 1 billion click behaviors, making it suitable for training large recommendation models. The computational and dataset collection costs for NineRec and MicroLens both exceeded one million RMB.

4. Transferable Recommender Systems Based on Large Language Models (LLMs)
The field of artificial intelligence is currently experiencing the era of large models, with numerous universal large models being proposed in various domains, significantly advancing the AI community. However, the application of large model technology in the field of recommender systems is still in its early stages. Many questions have yet to be satisfactorily answered, such as whether the use of large language models for understanding recommendation tasks can significantly surpass the existing ID paradigm and whether larger-scale parameter models can bring about universal recommendation representations. Answering these questions is the key to driving the recommender system community into the era of large models, and it has garnered increasing attention from many research groups.
GPT4Rec [8] is one of the representative works at this stage. GPT4Rec extensively evaluates the capabilities of a 175 billion-item encoder. There are also various follow-up works, such as those based on prompts, chain of thought, ChatGPT, and more. Additionally, concurrent works include Google's LLM for rating prediction [9]. Similar to GPT4Rec, they both assess performance limits using transfer models, with one focusing on top-n-item recommendations and the other concentrating on rating prediction.
GPT4Rec is the first to explore the use of a hundred-billion-scale language model as an item encoder. The paper introduces and addresses several key questions:
- How does the performance of text-based collaborative filtering (TCF) recommendation algorithms evolve as the number of parameters in the item encoder increases, and is there a limit to performance, even at the hundred-billion parameter scale?
- Can super-large parameter LLMs, like the 175 billion-parameter GPT-3, generate universal item representations?
- Can recommender system algorithms equipped with a 175 billion-parameter LLM outperform classical algorithms based on item IDs through fair comparisons?
- How far is text-based collaborative filtering (TCF) with LLMs from achieving universal large models for recommender systems?
The experimental results reveal the following:
- It is possible that 175 billion parameter LLMs have not reached their performance limits yet. Observations show that the performance of the TCF model does not converge when transitioning from a 13 billion to a 175 billion parameter LLM. This suggests that using LLMs with more parameters as text encoders has the potential to bring higher recommendation accuracy in the future.
- Even item representations learned by extremely large LMs (such as GPT-3) may not necessarily form a universal representation. Fine-tuning relevant recommender system datasets is still necessary to achieve state-of-the-art performance, at least for text-based recommendation tasks.
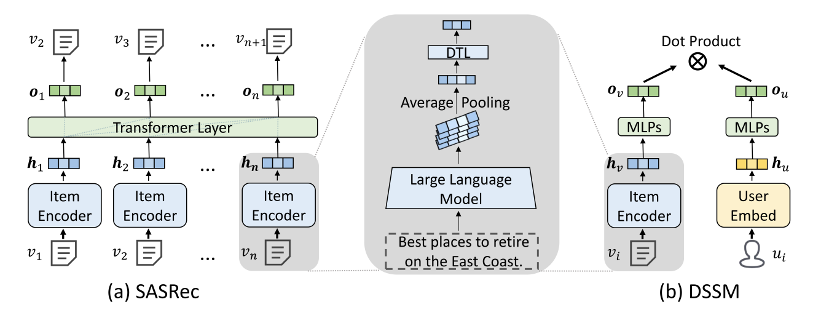
- Even with a 175 billion and fine-tuned 66 billion language model, when using DSSM as the recommendation backbone, TCF still lags significantly behind IDRec. However, for sequential recommendation models, LLMs, even when using frozen representations, can roughly compete with IDRec.
- While the performance of TCF models with 175 billion parameters LLMs outperforms random item sampling in recommendations, achieving improvements ranging from 6 to 40 times, there is still a significant gap compared to TCF models re-trained on the recommendation dataset.
- The paper also discovers that ChatGPT performs significantly worse than TCF in typical recommender system scenarios, suggesting that more refined prompts may be required for ChatGPT to be usable in certain real-world recommendation scenarios.
![]() 5. Conclusion
5. Conclusion
 5. Conclusion
5. ConclusionIn the current recommender systems community, research on modality-based large models is still in its early stages. Many key challenges and limitations can be summarized as follows:
- Traditional ID-based recommendation algorithms face challenges in handling modal scenarios where user and item information are available in different forms beyond traditional identifiers.
- Existing literature on cross-domain recommender systems based on modal content often lacks generalizability, making it difficult to apply findings across various recommendation tasks and domains.
- Unlike end-to-end joint training, pre-extracted features may have problems such as granular scale mismatch and can usually only generate sub-optimal recommendations.
- The community lacks large-scale, publicly available datasets that include modal content for research in transfer learning, as well as benchmark datasets and leaderboards to assess model performance.
- Existing research in recommender system large models often has relatively small model parameters and training data (compared to the fields of NLP and CV), and open-source large model pre-training parameters are also extremely scarce.
Reference
[1] Parameter-efficient transfer from sequential behaviors for user modeling and recommendation (SIGIR2020)
[2] One Person, One Model, One World: Learning Continual User Representation without Forgetting (SIGIR2021)
[3] Learning transferable user representations with sequential behaviors via contrastive pre-training (ICDM2021)
[4] TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback. Arxiv2022/06
[5] Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited (SIGIR2023)
[6] Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights (WSDM2024)
[7] NineRec: A Suite of Transfer Learning Datasets for Modality Based Recommender Systems. Arxiv2023/09
[8] Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. Arxiv2023/05
[9] Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. Arxiv2023/05
[10] A Content-Driven Micro-Video Recommendation Dataset at Scale. Arxiv2023/09
Published at DZone with permission of Fengyi Li. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments