Implementation of DataOps With Databrew
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data.
Join the DZone community and get the full member experience.
Join For FreeOrganizations nowadays are looking beyond mere economics and leveraging cloud-native capabilities to instill stability, scalability, accuracy, and speed in their applications.
Organizations are contemplating the best strategy for modernizing their legacy application and creating an advanced and automated DataOps platform.
One of the biggest challenges the client is facing is the time consumed in data preparation, validation, and accuracy, which in turn adds to the unexpected increase in cost, lowers the quality of data, and decreases the precision percentage.
Taking a step forward to address these challenges and deliver cloud transformation solutions, we are leveraging DataOps with Databrew.
What Is DataBrew?
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning.
DataBrew helps reduce the time it takes to prepare data for analytics and machine learning (ML) by up to 80 percent compared to custom-developed data preparation. We can choose from over 250 ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, correcting invalid values, etc.
After your data is ready, you can immediately use it for analytics and machine learning projects. You only pay for what you use — no upfront commitment.
The following are its capabilities:
Data Profiling
Evaluate the quality of your data by profiling it to understand data patterns and detect anomalies.
Data Lineage
Visually map the lineage of your data to understand the various data sources and transformation steps that the data has been through.
Data Cleaning Automation
Automate data cleaning and normalization tasks by applying saved transformations.
Solution Overview
The solution proposed is using the Data Brew service with the DataOps implementation model. The heart of the solution is using the Data Brew in the orchestration framework guided by AWS Step Function.
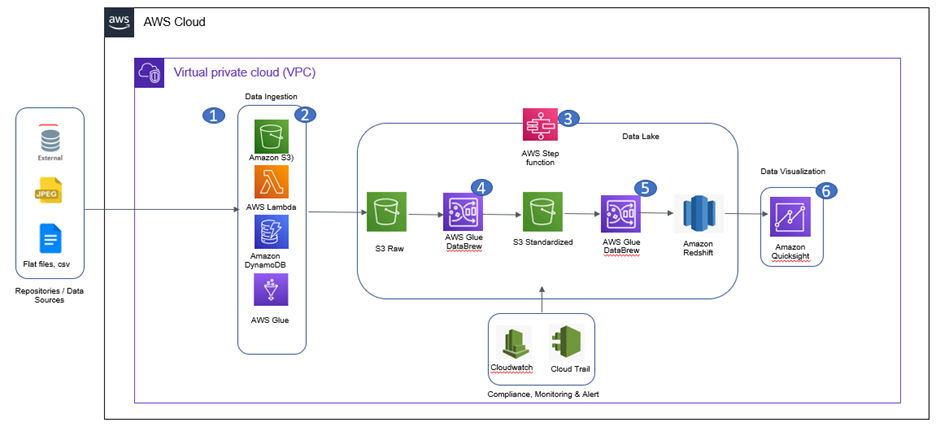
Data Flow
- The document upload engine uploads the respective files/documents from the source system repositories to the designated S3 bucket.
- The event-based architecture triggers the event as an S3 pushes to call the respective Lambda function to start the orchestration process.
- The Step function will orchestrate in a series or parallel fashion to initiate the step-by-step process. Cloudwatch will be used for monitoring and alerting mechanisms. CloudTrail will be used for audit logging.
- DataBrew will run the recipe or defined set of transformations on the data files received from the source. Refined and processed data will then be stored in another S3 bucket.
- Processed data will again be transformed using DataBrew for storage into Redshift for reporting use after all data checks have been performed.
- Quicksight will connect to the Redshift database to provide self-service reports/dashboards to the end customers.
The Various Capabilities of the Solution
- Ability to effectively perform data preparation activities.
- Reusability of the effective recipes created in DataBrew.
- A large number of available ready-made transformations will save us time in data preparation.
- Cost-effective solution based on serverless architecture.
- DataOps-driven automated framework will provide the fully integrated skeleton for reuse.
- Efficiency and effectiveness in data preparation.
- Ability to handle and redirect PII data.
- Event-based trigger for pipeline processing.
- Integrated with a monitoring mechanism for timely alerts.
- Less manual intervention in the fully integrated solution.
- End-to-end data delivery using cloud-agnostic solutions provides scalability and cost-effectiveness.
Benefits
- Process efficiency: Increases overall efficiency in data preparation by up to 80%
- Effort optimization: Up to 30-40% reduction in involvement of in-house teams required for data preparation activities.
- 250+ ready-made transformations to choose from for data preparation tasks.
Industrial Usage
The DataBrew with DataOps as a solution has benefits across industries as efficient data preparation is required by most of the industry processes for operational functions. For example, for the manufacturing industry, monthly sales analysis; for healthcare, it could be medical records used for future prediction of upcoming health challenges; for the media industry, finding out the TRP-driven content in real time, etc. So, the overall solution will deliver cloud transformation at scale with data preparation in a speedy manner needed for most organizations and implementing the solution leveraging Amazon Cloud services, which offers the benefit of quick wins, optimal cost, and unlimited scalability.
Opinions expressed by DZone contributors are their own.
Comments