Implementing Decentralized Data Architecture on Google BigQuery: From Data Mesh to AI Excellence
Traditional centralized data lakes don’t scale for AI. A Data Mesh not only decentralizes data ownership by domain but also enforces federated governance.
Join the DZone community and get the full member experience.
Join For FreeIn the era of generative AI and large language models (LLMs), the quality and accessibility of data have become the primary differentiators for enterprise success. However, many organizations remain trapped in the architectural paradigms of the past — centralized data lakes and warehouses that create massive bottlenecks, high latency, and "data swamps."
Enter the Data Mesh. Originally proposed by Zhamak Dehghani, Data Mesh is a sociotechnical approach to sharing, accessing, and managing analytical data in complex environments. When paired with the scaling capabilities of Google BigQuery, it creates a foundation for "AI Excellence," where data is treated as a first-class product, ready for consumption by machine learning models and business units alike.
In this technical deep-dive, we will explore how to architect a Data Mesh on Google Cloud, leveraging BigQuery's unique features to drive decentralized data ownership and AI-ready infrastructure.
1. The Architectural Shift: Why Data Mesh?
Traditional data architectures are typically centralized. A single data engineering team manages the ingestion, transformation, and distribution of data for the entire company. As the number of data sources and consumers grows, this team becomes a bottleneck.
The Four Pillars of Data Mesh
- Domain-Oriented Decentralized Data Ownership: The people who know the data best (e.g., the Marketing team) should own and manage it.
- Data as a Product: Data is not a byproduct; it is a product delivered to internal consumers with SLAs, documentation, and quality guarantees.
- Self-Serve Data Platform: A centralized infrastructure team provides the tools (like BigQuery) so domains can manage their data autonomously.
- Federated Computational Governance: Global standards for security and interoperability are enforced through automation.
Comparative Overview: Monolith vs. Mesh
| Feature | Centralized Data Lake/Warehouse | Decentralized Data Mesh |
|---|---|---|
| Ownership | Central Data Team | Business Domains (Sales, HR, etc.) |
| Data Quality | Reactive (Fixed by Data Engineers) | Proactive (Managed by Domain Owners) |
| Scalability | Linear (Bottlenecks occur) | Exponential (Parallel execution) |
| Access Control | Uniform (Often too loose or tight) | Granular (Domain-specific policies) |
| AI Readiness | Low (Silod context) | High (Context-rich data products) |
2. Technical Mapping: Building the Mesh on BigQuery
Google BigQuery is uniquely suited for Data Mesh because it separates storage and compute, allowing different projects to interact with the same data without physical duplication.
Core Components
- BigQuery Datasets: Act as the boundaries for data products.
- Google Cloud Projects: Serve as the containers for domain environments.
- Analytics Hub: Facilitates secure, cross-organizational data sharing.
- Dataplex: Provides the fabric for federated governance and data discovery.
System Architecture Diagram
This diagram illustrates the relationship between domain-specific producers, the central catalog, and the AI consumers.
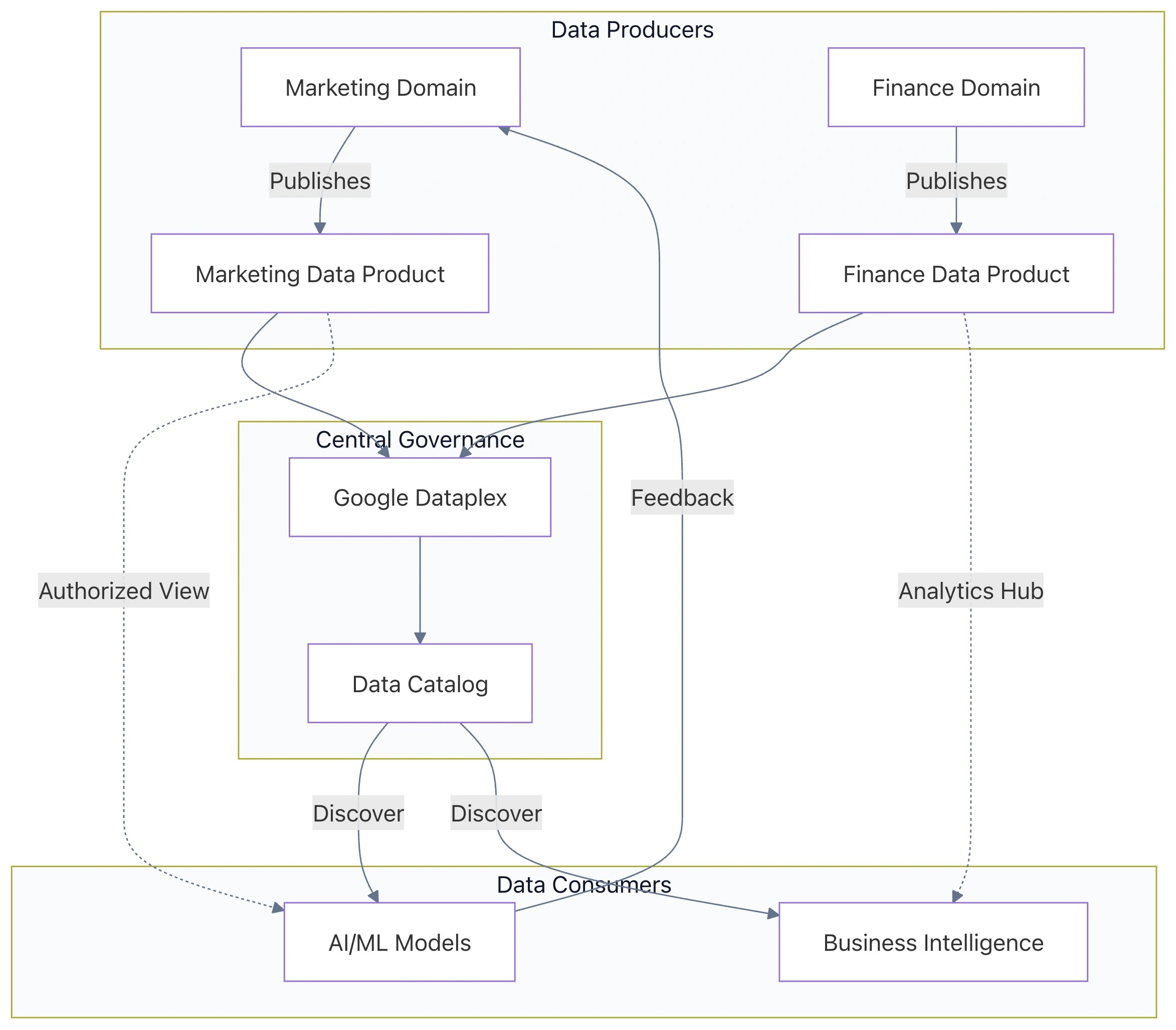
3. Implementing Domain Ownership and Data Products
In a Data Mesh, each domain manages its own BigQuery projects. They are responsible for the full lifecycle of their data products: ingestion, cleaning, and exposure.
Defining the Data Product
A data product on BigQuery is not just a table. It includes:
- The Raw Data (Internal Dataset)
- The Cleaned/Aggregated Data (Public Dataset)
- Metadata (Labels and Descriptions)
- Access Controls (IAM roles)
Code Example: Creating a Domain-Specific Data Product
Using SQL and gcloud, we can define a data product with specific access controls. In this example, we create a "Customer LTV" product for the Sales domain.
-- Step 1: Create the dataset in the domain project
-- This acts as the container for our data product
CREATE SCHEMA `sales-domain-prod.customer_analytics`
OPTIONS(
location="us",
description="High-quality customer lifetime value data for AI consumption",
labels=[("env", "prod"), ("domain", "sales"), ("data_product", "cltv")]
);
-- Step 2: Create a secure view to expose only necessary columns
-- This follows the principle of least privilege
CREATE OR REPLACE VIEW `sales-domain-prod.customer_analytics.cltv_gold` AS
SELECT
customer_id,
total_spend,
last_purchase_date,
predicted_churn_score
FROM
`sales-domain-prod.customer_analytics.raw_customer_data`
WHERE
is_verified = TRUE;Automating Governance with IAM
To ensure the domain maintains ownership while allowing the central team to monitor, we use granular IAM roles.
# Assign the Data Owner role to the Sales Domain Team
gcloud projects add-iam-policy-binding sales-domain-prod \
--member="group:[email protected]" \
--role="roles/bigquery.dataOwner"
# Assign the Data Viewer role to the AI/ML Consumer Service Account
gcloud projects add-iam-policy-binding sales-domain-prod \
--member="serviceAccount:[email protected]" \
--role="roles/bigquery.dataViewer"4. Federated Governance with Google Dataplex
Governance in a Data Mesh cannot be manual. We use Google Dataplex to automate metadata harvesting, data quality checks, and lineage tracking across all domain projects.
The Data Flow for Governance

Data Quality Checks (The "Quality Score" Metric)
To ensure AI models aren't trained on garbage, domains must define quality rules. Dataplex allows us to run YAML-based data quality checks.
# Dataplex Data Quality Rule Example
rules:
- column: customer_id
dimension: completeness
threshold: 0.99
expectation_type: expect_column_values_to_not_be_null
- column: total_spend
dimension: validity
expectation_type: expect_column_values_to_be_between
params:
min_value: 0
max_value: 10000005. From Mesh to AI: Fueling Vertex AI
Once the Data Mesh is established, AI teams no longer spend 80% of their time finding and cleaning data. They can "shop" for data in the Analytics Hub and connect it directly to Vertex AI.
Seamless Integration with Vertex AI Feature Store
BigQuery acts as the offline store for Vertex AI. Because the data is already organized into domain-driven products, creating a feature set is a simple metadata mapping.
Code Example: Training a Model on Mesh Data
Using BigQuery ML (BQML), we can train a model directly on our decentralized data product without moving it to a central location.
-- Training a Churn Prediction Model using the Sales Domain Data Product
CREATE OR REPLACE MODEL `ai-consumer-project.models.churn_predictor`
OPTIONS(model_type='logistic_reg', input_label_cols=['churned']) AS
SELECT
* EXCEPT(customer_id)
FROM
`sales-domain-prod.customer_analytics.cltv_gold` AS data_product
JOIN
`marketing-domain-prod.engagement.user_activity` AS activity_product
ON
data_product.customer_id = activity_product.user_id;This SQL highlights the power of Data Mesh: the AI consumer joins two different data products from two different domains (Sales and Marketing) seamlessly because they adhere to global naming and identity standards.
6. Implementation Strategy: A Phased Approach
Moving to a Data Mesh is as much about culture as it is about technology. Follow this roadmap:
- Phase 1: Identification (Months 1-2): Identify 2-3 pilot domains (e.g., Sales, Logistics). Define their data product boundaries.
- Phase 2: Platform Setup (Months 3-4): Set up the BigQuery environment with Dataplex and Analytics Hub. Establish a "Self-Serve" template using Terraform.
- Phase 3: Governance Automation (Months 5-6): Implement automated data quality and cataloging. Define global tagging standards.
- Phase 4: AI Scaling (Month 6+): Enable ML teams to consume data products via Vertex AI and BigQuery ML.
7. Challenges and Mitigations
| Challenge | Description | Mitigation |
|---|---|---|
| Interoperability | Domains using different IDs for the same customer. | Enforce a "Master Data Management" (MDM) set of global dimensions. |
| Cost Management | Decentralized teams might overspend on BigQuery slots. | Use BigQuery Reservations and Quotas per project/domain. |
| Skills Gap | Domain teams might lack data engineering skills. | Provide a robust "Self-Serve" platform with easy-to-use templates. |
Conclusion: The Mesh as an AI Accelerator
The ultimate goal of the Data Mesh on BigQuery is to democratize intelligence. By decentralizing data ownership, we ensure that those closest to the business logic are responsible for the data's integrity. By centralizing governance and tools, we ensure that this data remains discoverable, secure, and ready for the next generation of AI.
Building a Data Mesh is not an overnight process, but for organizations looking to scale AI beyond simple prototypes, it is the only viable path forward. Start small, treat your data as a product, and let BigQuery's infrastructure handle the scale while your domains handle the value.
For more technical guides on Google, AI architecture and implementation, follow:
Published at DZone with permission of Jubin Abhishek Soni. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments