Improving Performance of Serverless Java Applications on AWS
Learn the basics behind how Lambda execution environments operate and different ways to improve the startup time and performance of Java applications on Lambda.
Join the DZone community and get the full member experience.
Join For FreeThis article was authored by AWS Sr. Developer Advocate, Mohammed Fazalullah Qudrath and AWS Sr. Developer Advocate, Viktor Vedmich, published with permission.
In this article, you will understand the basics behind how Lambda execution environments operate and the different ways to improve the startup time and performance of Java applications on Lambda.
Why Optimize Java Applications on AWS Lambda?
AWS Lambda’s pricing is designed to charge you based on the execution duration, rounded to the nearest millisecond. The cost of executing a Lambda function will be proportional to the amount of memory allocated to the function. Therefore, performance optimization may also result in long-term cost optimizations.
For Java-managed runtimes, a new JVM is started and the Java application code is loaded. This results in additional overhead compared to interpreted languages and contributes to initial start-up performance.
To understand this better, the next section gives a high-level overview of how AWS Lambda execution environments work.
A Peek Under the Hood of AWS Lambda
AWS Lambda execution environments are the infrastructure upon which your code is executed. When creating a Lambda function, you can provide a runtime (e.g., Java 11). The runtime includes all dependencies necessary to execute your code (for example, the JVM).
A function’s execution environment is isolated from other functions and the underlying infrastructure by using the Firecracker micro VM technology. This ensures the security and integrity of the system.
When your function is invoked for the first time, a new execution environment is created. It will download your code, launch the JVM, and then initializes and executes your application. This is called a cold start. The initialized execution environment can then process a single request at a time and remains warm for subsequent requests for a given time. If a warm execution environment is not available for a subsequent request (e.g., when receiving concurrent invocations), a new execution environment has to be created which results in another cold start.
Therefore, to optimize Java applications on Lambda one has to look at the execution environment, the time it takes to load dependencies, and how fast can it be spun up to handle requests.
Improvements Without Changing Code
Choosing the Right Memory Settings With Power Tuning
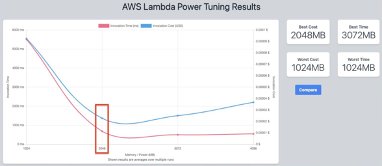
Choosing the memory allocated to Lambda functions is a balancing act between speed (duration) and cost. While you can manually run tests on functions by configuring alternative memory allocations and evaluating the completion time, the AWS Lambda Power Tuning application automates the process.
This tool uses AWS Step Functions to execute numerous concurrent versions of a Lambda function with varying memory allocations and measure performance. The input function is executed in your AWS account, with live HTTP requests and SDK interaction, in order to evaluate performance in a live production scenario.
You can graph the results to visualize the performance and cost trade-offs. In this example, you can see that a function has the lowest cost at 2048 MB memory, but the fastest execution at 3072 MB:
Enabling Tiered Compilation
The tiered compilation is a feature of the Java HotSpot Virtual Machine (JVM) that allows the JVM to apply several optimization levels when translating Java bytecode to native code. It is designed to improve the startup time and performance of Java applications.
The Java optimization workshop shows the steps to enable tiered compilation on a Lambda function.
Activating SnapStart on a Lambda Function
SnapStart is a new feature announced for AWS Lambda functions running on Java Coretto 11. When you publish a function version with SnapStart enabled, Lambda initializes your function and takes a snapshot of the memory and disk state of the initialized execution environment. It encrypts the snapshot and caches it for low-latency access. When the function is invoked for the first time, and as the invocations scale up, Lambda resumes new execution environments from the cached snapshot instead of initializing them from scratch, improving startup latency. This feature can improve the startup performance of latency-sensitive applications by up to 10x at no extra cost, typically with no changes to your function code. Follow these steps to activate SnapStart on a Lambda function.
Configuring Provisioned Concurrency
Provisioned Concurrency on AWS Lambda keeps functions initialized and hyper-ready to reply in double-digit milliseconds. When this feature is enabled for a Lambda function, the Lambda service will prepare the specified number of execution environments to respond to invocations. You pay for the memory reserved, whether it is used or not. This also results in costs being less than the on-demand price in cases where there is a constant load on your function.
Improvements With Code Refactoring
Using Light-Weight Dependencies
Choose between alternative dependencies based on feature richness versus performance needs. For example, when choosing a logging library, use SLF4J SimpleLogger if the need is to just log entries, instead of using Log4J2 which brings much more features to the table that may not be used. This will improve the startup time by nearly 25%.
The Spring Data JPA and Spring Data JDBC data access API frameworks can be compared in the same manner. Using the Spring Data JDBC framework will reduce the startup time of a Lambda function by approx. 25% by compromising on the feature set of an advanced ORM.
Optimizing for the AWS SDK
Ensure that any costly actions, such as making an S3 client connection or a database connection, are performed outside the handler code. The same instance of your function can reuse these resources for future invocations. This saves cost by reducing the function duration.
In the following example, the S3Client instance is initialized in the constructor using a static factory method. If the container that is managed by the Lambda environment is reused, the initialized S3Client instance is reused.
public class App implements RequestHandler<Object, Object\> {
private final S3Client s3Client;
public App() {
s3Client = DependencyFactory.s3Client();
}
@Override
public Object handleRequest(final Object input, final Context context) {
ListBucketResponse response = s3Client.listBuckets();
// Process the response.
}
}When utilizing the AWS SDK to connect to other AWS services you can accelerate the loading of libraries during initialization by making dummy API calls outside the function handler. These dummy calls will initialize any lazy-loaded parts of the library and additional processes such as TLS-handshakes.
public class App implements RequestHandler < Object, Object \> {
private final DynamoDbClient ddb = DynamoDbClient.builder()
.credentialsProvider(EnvironmentVariableCredentialsProvider.create())
.region(System.getenv("AWS\_REGION"))
.httpClientBuilder(UrlConnectionHttpClient.builder())
.build();
private static final String tableName = System.getenv("DYNAMODB\_TABLE\_NAME");
public App() {
DescribeTableRequest request = DescribeTableRequest.builder()
.tableName(tableName)
.build();
try {
TableDescription tableInfo = ddb.describeTable(request).table();
if (tableInfo != null) {
System.out.println("Table found:" + tableInfo.tableArn());
}
} catch (DynamoDbException e) {
System.out.println(e.getMessage());
}
}
@Override
public Object handleRequest(final Object input, final Context context) {
//Handler code
}
}Leveraging Cloud Native Frameworks With GraalVM
GraalVM is a universal virtual machine that supports JVM-based languages, like Java, Scala, and Kotlin, along with dynamic languages, like Python, JavaScript, and LLVM-based languages, like C, and C++. GraalVM enables the Ahead-of-Time (AoT) compilation of Java programs into a self-contained native executable, called a native image. The executable is optimized and contains everything needed to run the application, and it has a faster startup time and smaller heap memory footprint compared with a JVM.
Modern cloud frameworks such as Micronaut and Quarkus (and the recent Spring Boot 3 release) support building GraalVM native images as part of the build process.
In conclusion, you have seen the various approaches to optimizing Java applications on AWS Lambda. Further resources linked below go in-depth with the above suggestions, along with a workshop linked below that you can follow along to do the above and more optimizations on a sample Spring Boot application.
References
Opinions expressed by DZone contributors are their own.
Comments