Improving Redis Performance Through Multi-Thread Processing
Learn how to optimize the performance of a Redis database with multi-thread processing.
Join the DZone community and get the full member experience.
Join For FreeRedis is generally known as a single-process, single-thread model. This is not true. Redis also runs multiple backend threads to perform backend cleaning works, such as cleansing the dirty data and closing file descriptors. In Redis, the main thread is responsible for the major tasks, including but not limited to: receiving the connections from clients, processing the connection read/write events, parsing requests, processing commands, processing timer events, and synchronizing data. Only one CPU core runs a single process and single thread.
For small packets, a Redis server can process 80,000 to 100,000 QPS. A larger QPS is beyond the processing capacity of a Redis server. A common solution is to partition the data and adopt multiple servers in distributed architecture.
However, this solution also has many drawbacks. For example, too many Redis servers to manage; some commands that are applicable to a single Redis server do not work on the data partitions; data partitions cannot solve the hot spot read/write problem; and data skew, redistribution, and scale-up/down become more complex. Due to restrictions of the single process and single thread, we hope that the multi-thread can be reconstructed to fully utilize the advantages of the SMP multi-core architecture, thus increasing the throughput of a single Redis server.
To make Redis multi-threaded, the simplest way to think of is that every thread performs both I/O and command processing. However, as the data structure processed by Redis is complex, the multi-thread needs to use the locks to ensure the thread security. Improper handling of the lock granularity may deteriorate the performance.
We suggest that the number of I/O threads should be increased to enable an independent I/O thread to read/write data in the connections, parse commands, and reply data packets, and still let a single thread process the commands and execute the timer events. In this way, the throughput of a single Redis server can be increased.
Single Process and Single Thread Model
Advantages
- Due to restrictions of the single-process and single-thread model, time-consuming operations (such as dict rehash and expired key deletion) are broken into multiple steps and executed one by one in Redis implementation. This prevents execution of an operation for a long time and therefore avoids long time blocking of the system by an operation. The single-process and single-thread code is easy to compile, which reduces the context switching and lock seizure caused by multi-process and multi-thread.
Disadvantages
- Only one CPU core can be used, and the multi-core advantages cannot be utilized.
- For heavy I/O applications, a large amount of CPU capacity is consumed by the network I/O operations. Applications that use Redis as cache are often heavy I/O applications. These applications basically have a high QPS, use relatively simple commands (such as get, set, and incr), but are RT sensitive. They often have a high bandwidth usage, which may even reach hundreds of megabits. Thanks to the popularization of the 10-GB and 25-GB network adapters, the network bandwidth is no longer a bottleneck. Therefore, what we need to think about is how to utilize the advantages of multi-core and performance of the network adapter.
Multi-Thread Model and Implementation
Thread Model
There are three thread types, namely:
- Main thread
- I/O thread
- Worker thread
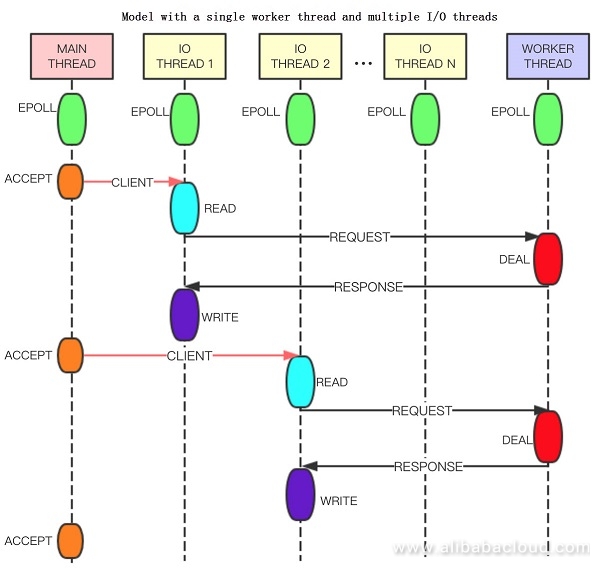
- Main thread: Receives connections, creates clients, and forwards connections to the I/O thread.
- I/O thread: Processes the connection read/write events, parses commands, forwards the complete parsed commands to the worker thread for processing, sends the response packets, and deletes connections.
- Worker thread: Processes commands, generates the client response packets, and executes the timer events.
- The main thread, I/O thread, and worker thread are driven by events separately.
- Threads exchange data through the lock-free queue and send notifications through tunnels.
Benefits of the Multi-Thread Model
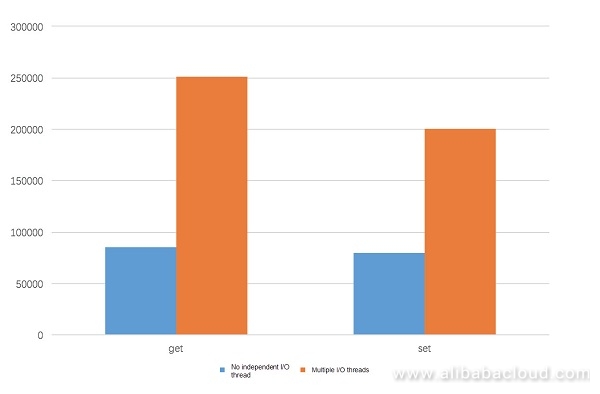
Increased Read/Write Performance
The stress test result indicates that the read/write performance can be improved by about three folds in the small packet scenario.
Increased Master/Slave Synchronization Speed
When the master sends the synchronization data to the slave, data is sent in the I/O thread. When reading data from the master, the slave reads the full data from the worker thread, and the incremental data from the I/O thread. This can efficiently increase the synchronization speed.
Subsequent Tasks
The first task is to increase the number of I/O threads and optimize the I/O read/write capability. Next, we can break down the worker thread so that each thread completes I/O reading, as well as the work of the worker thread.
Setting the Number of I/O Threads
- Test results indicate that the number of I/O threads should not exceed 6. Otherwise, the worker thread will become a bottleneck for simple operations.
- Upon startup of a process, the number of I/O threads must be set. When the process is running, the number of I/O threads cannot be modified. Based on the current connection allocation policy, modification of the number of I/O threads involves re-allocation of connections, which is quite complex.
Considerations
- With the popularization of the 10-GB and 25-GB network adapters, how to fully utilize the hardware performance must be carefully considered. We can use technologies, such as multiple threads for networkI/O and the kernel bypass user-mode protocol stack.
- The I/O thread can be used to implement blocking-free data migration. The I/O thread encodes the data process or forwards commands, whereas the target node decodes data or executes commands.
Published at DZone with permission of Leona Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments