Infusing Generative AI Into Shopify’s Product Recommendation App
Dive into how generative AI was implemented into Shopify’s entire product recommendation application, Search and Discovery.
Join the DZone community and get the full member experience.
Join For FreeE-commerce merchants are no strangers to the concept of a product recommendation system. However, traditional implementations have their limitations. Here, we’ll delve into how I infused generative AI into Shopify’s product recommendation application, Search and Discovery.

The approach was straightforward; I only used two GenAI prompts to implement the entire system. I will cover these two prompts in detail and discuss the challenges I faced dealing with LLM hallucinations. I will show how I leveraged both DataStax’s Vector Search capabilities and the LangStream framework to simplify the entire design.
What Is a Product Recommendation System?
A product recommendation system provides product suggestions to consumers at different points in their shopping journey — be it in the shopping cart or on the product detail pages. There are two general categories of product recommendations exemplified in the Shopify Search and Discovery application. These two categories are manifested as products appearing under the “You may also like” and “Pairs well with” sections of a shopping page. These categories represent similar products vs complementary products, respectively.
Traditional recommendation systems use heuristics and rules-based logic to filter products down to a set of recommendations based on a given context, such as when a customer has placed a product in their shopping cart. Product details such as product category, vendor, price, or other product metadata are utilized as filter criteria.
Researching the Project
In reading the documentation for the Shopify Search and Discovery app, I discovered that complementary products have to be manually specified by the customer. This is in contrast to product recommendations in the ‘Similar products’ category, for which recommendations are automatically generated based on a set of filtering rules.
I needed to find a way to programmatically specify complementary products to the Shopify app. After some experimentation, I came upon a workable solution. Product recommendation data are stored in Shopify as metadata fields for each product in the product catalog. I used Shopify’s GraphQL interface to find the correct metadata. If you haven’t done so already, install Shopify’s GraphiQL application, which allows one to experiment with GraphQL queries.
I used the following query to get a list of all metadata fields on a product for which I had specified complementary products via the Shopify Search and Discovery application user interface.
Example: Shopify GraphQL Query to retrieve product metadata fields
query {
product(id: "gid://shopify/Product/<ID>") {
metafields (first: 50) {
edges { node {
id
namespace
key
type
value
}
}
}
}
}The above GraphQL query yielded two metadata fields that store product recommendations. One for related (similar) products and the other for complementary products.
Example: Shopify GraphQL Query response showing product recommendation metadata fields
{
"data": {
"product": {
"metafields": {
"edges": [
{
"node": {
"id": "gid://shopify/Metafield/1234567XXX",
"namespace": "shopify--discovery--product_recommendation",
"key": "related_products",
"type": "list.product_reference",
"value": "[\"gid://shopify/Product/89123NNN\",\"gid://shopify/Product/89123ZZZ\"]"
}
},
{
"node": {
"id": "gid://shopify/Metafield/1234567YYY",
"namespace": "shopify--discovery--product_recommendation",
"key": "complementary_products",
"type": "list.product_reference",
"value": "[]"
}
}In order to modify the value of the complementary metadata field, we can execute the following GraphQL mutation query. By setting this metadata, the ‘Pairs well with’ widget is activated on the product detail page, which then shows the set of configured complementary products.
Note Shopify doesn’t allow modifying pre-existing metadata fields that belong to a private namespace. The trick is to check for the existence of the field for a given product, perform a delete, and then re-create the operation on the field or add the field if it does not already exist.
Example: Shopify GraphQL Mutation Query update product metadata field values
mutation {
productUpdate(
input: {id: "${product_id}", metafields: {id: "${metadata_field_id}", namespace: "shopify--discovery--product_recommendation", type: "list.product_reference", value: "${metafield_value}"}}
) {
product {
title
handle
metafield(
namespace: "shopify--discovery--product_recommendation"
key: "complementary_products"
) {
id
namespace
type
value
}
}
}
}A Summary of the Shopify App
The bulk of the effort to create the GenAI product recommendation system involved integrating with the Shopify ecosystem. Part of this work was creating a Shopify Admin UI to allow a merchant to trigger recommendation previews and then apply product recommendations to their product catalog.
I used DataStax’s LangStream project to implement the back-end solution for processing each product recommendation. LangStream provided me with a batch-processing system to queue and process product recommendations. Through a series of YAML configurations, I was able to specify data processing pipelines to execute the various stages of the recommendation workflow.
Reference Terms
Source product - The product for which we are generating recommendations.
Product type - The type of product, for example ‘Apparel’ is the product type for ‘Pants’ or ‘Polo shirt’.
Complementary product - This is a complementary product, for example, if the source product is ‘Golf clubs’, then a complementary product might be ‘Golf balls’.
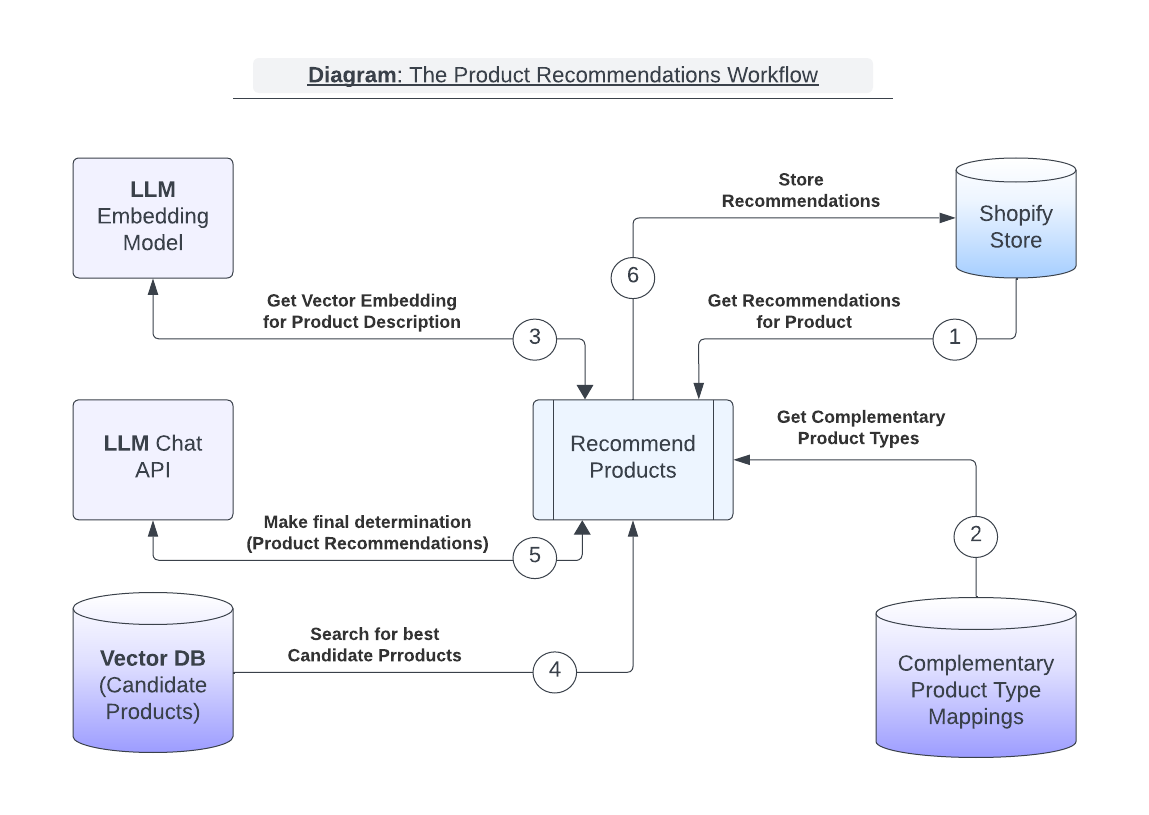
Complementary product type - A complementary product category, for example 'Rangefinders’ is complementary to ‘Golf clubs’.The diagram below depicts the main workflow for generating AI-based recommendations. A merchant would trigger this workflow via the Shopify GenAI recommendations app UI. The workflow is executed once for each product in the set of products for which we are generating recommendations.
Note: I mentioned earlier that I only used two LLM prompts in the solution. The ‘Complementary Product Type Mappings’ lookup table in the diagram is generated with one of these prompts, which I will discuss later.
The six steps in the product recommendations workflow:
- Product recommendations are requested for a given source product.
![Diagram]()
- A set of complementary product types are retrieved from a lookup table based on the source product type. A set of candidate products will be generated that are of the given complementary product type(s).
- The source product’s description is passed to an LLM embedding API to generate an embedding Vector. The embedding vector is used to search for similar products in the Vector DB. By similar, I mean any product that matches closely in meaning. For example, Golf Balls would be more closely related in meaning to Golf Clubs than Dog Collars.
- A Vector DB search is executed whose query inputs include the embedding Vector from (3) and the list of complementary product types. The search results include the set of complementary product candidates and, for each product — various pieces of metadata like product title, price, vendor, and product description.
- An LLM prompt is formulated containing all the details of the candidate products from (4), a set of instructions for generating recommendations, and instructions for formatting the results. The prompt is sent to the LLM Chat API to produce the product recommendations.
- The LLM response from (5) is post-processed into a set of valid Shopify product IDs that are used to update the source product’s complementary-products metadata.
Setting up the Vector Database
The Vector database contains metadata for the products in the Shopify merchant’s store. The purpose of the data stored in the Vector DB is to enable the use of Vector search for candidate products. Performing this type of search is not possible using the Shopify API. In addition, storing product metadata in the Vector DB avoids the need to execute a subsequent query to the Shopify API for this data. Keeping the Vector DB in sync with the Shopify products database is a topic for another blog post.
In the steps below, we will create a Table that contains five pieces of metadata per product. The metadata comes from Shopify, whereas the Vector value is calculated by making a call to an LLM embedding API with the product description as input.
- Product ID (from Shopify)
- Product Description (from Shopify)
- Product title (from Shopify)
- Product price (from Shopify)
- Product type (A Shopify product type value)
- Product vector (from LLM embeddings API)
In this example, we use a 1536 dimension vector produced by OpenAI’s embedding model (text-embedding-ada-002)
- Example: Astra DB CQL commands to set up a Vector search-capable products table and associated indexes
CREATE KEYSPACE golf_store_embeddings WITH replication = {'class': 'NetworkTopologyStrategy', 'us-east1': '3'} AND durable_writes = true;
CREATE TABLE golf_store_embeddings.products (
shop text,
product_id text,
product_description text,
product_title text,
product_price float,
product_vector vector<float, 1536>,
product_type text,
PRIMARY KEY (shop, product_id)
);
CREATE CUSTOM INDEX indexed_productid_idx ON golf_store_embeddings.products (product_id) USING 'org.apache.cassandra.index.sai.StorageAttachedIndex';
CREATE CUSTOM INDEX indexed_producttype ON golf_store_embeddings.products (product_type) USING 'org.apache.cassandra.index.sai.StorageAttachedIndex';
CREATE CUSTOM INDEX indexed_embedding_idx ON golf_store_embeddings.products (product_vector) USING 'org.apache.cassandra.index.sai.StorageAttachedIndex';
Importing the Shopify Product Catalog
Populating the Vector DB with product metadata will require a one-time import operation and subsequent updates to keep the database in sync with the merchant’s product catalog. A merchant can export their product catalog from Shopify to a CSV file, which can then be fed into an import program of their choice.

There are several adequate choices here, including implementing a homegrown solution or using a combination of LangChain and CassIO. Whatever solution you choose will involve calculating an embedding Vector value for each imported product description.
GenAI Prompt for Calculating Complementary Product Types
We can leverage an LLM to help us create a complementary product types lookup table. A key mechanism of finding complementary products is to find which categories of products pair well with each other. This pairing process is normally handled by humans who apply their real-world experience to create a list of sensible complements based on available choices.
This problem domain is an excellent target for applying an LLM’s understanding of the world to generate sensible recommendations. The table below is a good example of complementary product mappings.
Example: Complementary Product Types Lookup Table
Product Type |
Complementary Product Types |
Belt |
Apparel, Coats & Jackets, Dress, Shorts |
Cart Bag |
Cart Mitts, Electric Cart, Golf Cart Accessories, Push Cart |
Coolers |
Cooler Bag, Soft Coolers, Sport Bottles, Water Bottles |
Driver |
Fairway, Hybrid, Irons, Wedge |
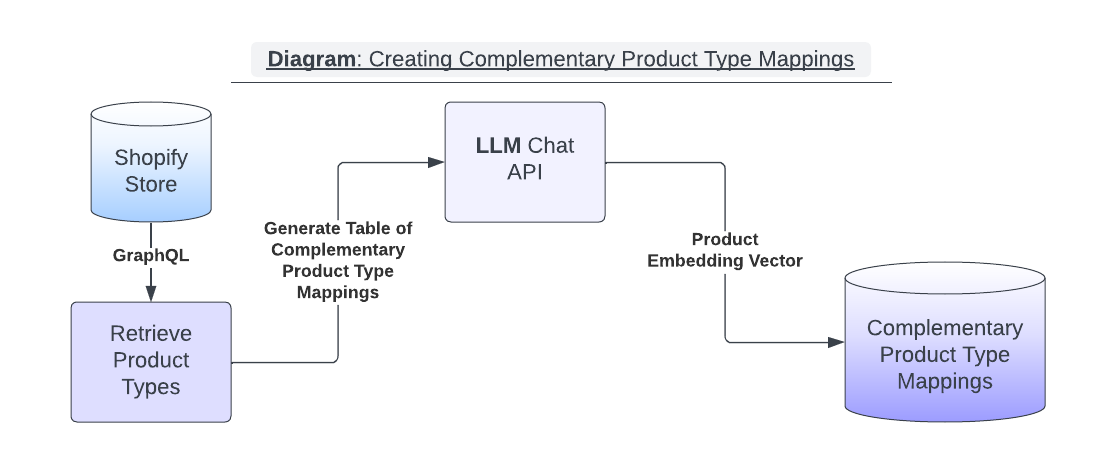
Every product in a Shopify store includes a product ‘Type’ attribute. The product type value is arbitrary and set by the store operator. We can retrieve a list of all product types in a merchant’s product catalog by executing a GraphQL query to the Shopify Storefront API.
Example: Shopify GraphQL Query for Product Types
query {
productTypes(first: 100) {
edges {
node
}
pageInfo {
hasNextPage
hasPreviousPage
}
}
}Example: Product Type results
{
"data": {
"productTypes": {
"edges": [
{ "node": "Apparel" },
{ "node": "Cart Bag" },
{ "node": "Golf Balls" },
{ "node": "Golf Gloves" },Using the above product type information, we can formulate an LLM Prompt to generate all of the complementary product type pairings automatically.
Note: We want the output of the LLM response to be a well-formatted JSON document that can be parsed to extract the results. The prompt includes the following parameters:
{{ MAX_COMPLEMENTARY_CATEGORIES }}— a value that limits the number of complementary types generated per product type{{ COMMA_SEP_LIST_OF_PRODUCT_CATEGORIES }}— a comma-separated list of all available product type categories in the merchant’s Shopify store{{ CUSTOM_NATURAL_LANGUAGE_RULES }}— One or more merchant-provided natural language rules that modify recommendation behavior
Example LLM Prompt: Generate complementary product categories
Given the following product type categories, for each individual category,
specify:
{{ MAX_COMPLEMENTARY_CATEGORIES }}
complementary categories from the same list.
{{ CUSTOM_NATURAL_LANGUAGE_RULES }}
Output the recommendations as a valid JSON document in the format
{\"category\", [\"complementary category 1\", \"complementary category 2\"]} .
Do not include any other commentary -
{{ COMMA_SEP_LIST_OF_PRODUCT_CATEGORIES }}GenAI Prompt for Product Recommendations
The LLM prompt for generating recommendations needs to include product metadata for all of the candidate products. We want the LLM to use these products as context for the final recommendation. This approach is referred to as Retrieval Augmented Generation (RAG).
Before we get to the LLM prompt itself, we’ll look at the Vector search query that retrieves metadata for the product candidates. The following Vector query can be used to curate a list of candidate products. The inputs to the query assume you’ve calculated the following values:
- An embedding vector for the source product description
- A list of complementary product types for the source product
Example Vector Search CQL Query: Generate a list of candidate product recommendations
SELECT
product_id,
product_description,
product_title,
product_price,
FROM golf_store.products
WHERE product_type IN {{LIST_OF_COMPLEMENTARY_PRODUCT_TYPES}}
ORDER BY product_vector ANN OF
{{ VECTOR_OF_SOURCE_PRODUCT_DESCRIPTION }}
LIMIT {{ MAX_CANDIDATES }};We can now generate the LLM prompt for product recommendations using the candidate product search results. The prompt template includes parameters for all necessary data. In addition, the prompt contains instructions to generate the desired recommendations output format.
{{ MAX_RECOMMENDATIONS }}— The maximum number of candidate products to choose from the list of provided products. The parameter is used twice in the prompt template below. The second instance is used to reduce LLM hallucinations by being explicit about the number of recommendations to be made{{ PRODUCT_DESCRIPTION }}— The description of the source product for which we are making recommendations{{ PRODUCT_TITLE }}— The title of the source product for which we are making recommendations{{ PRODUCT_PRICE }}— The price of the source product for which we are making recommendations- Fields
{{ PRODUCT_METADATA_N_.. }}— Replace these fields with data from each candidate product. Use the data from the Vector search results. Note: the custom recommendation instructions can reference this metadata by referring to things like product type, price, or something that might be in the product description. {{ CUSTOM_INSTRUCTIONS_FOR_PRODUCT_FILTERING }}— This section could include a series of custom recommendation rules that reference product metadata. Example rules:- “ Between January and February, recommend brand X products.”
- "Try to always recommend products from the same brand ”
{{ CURRENT_DATE }}— The current date can be inserted as additional contextual information. The custom rules above could include language that activates recommendations during a given timeframe.
Example LLM Prompt: Generate product recommendations
You are a helpful assistant.
Create a recommendation of up to {{ MAX_RECOMMENDATIONS }} products to buy.
I am looking at buying a product that is complementary to {{ PRODUCT_DESCRIPTION }} that retails for {{ PRODUCT_PRICE }} dollars.
Suggest a minimum of 1 and a maximum of {{ MAX_RECOMMENDATIONS }} of the products in following list:
Product Id: {{ PRODUCT_METADATA_1_ID }}
Product Title: {{ PRODUCT_METADATA_1_TITLE }}
Product Description: {{ PRODUCT_METADATA_1_DESCRIPTION }}
Product Price: {{ PRODUCT_METADATA_1_PRICE }}
Product Type: {{ PRODUCT_METADATA_1_TYPE }}
{{ CUSTOM_INSTRUCTIONS_FOR_PRODUCT_FILTERING }}
Do not suggest products not listed in this prompt.
Also do not suggest the product I am looking for.
Take into consideration that the current date is {{ CURRENT_DATE }}.
Your product recommendation should be a valid JSON document.
Do not include program code.
The top level object is a list with the field name recommended_products.
Each item has a product field containing the product title, a product-id field containing the Product-ID.
Only respond with a JSON document and no other commentaryPost Processing the LLM Recommendation Response
Depending on the LLM chat model used, this prompt may generate varying results. We used ChatGPT 3.5 Turbo and ChatGPT 4.0 from OpenAI, both of which yielded stable JSON document structures most of the time. You can employ various prompt engineering approaches to improve the results. Your code can then parse the JSON results to update product recommendation metadata using the Shopify GraphQL strategies outlined earlier.
The Challenge of Working Around LLM Hallucinations
Responses from LLM chat systems occasionally produce unexpected output and made-up data. I encountered several patterns of hallucination while working with the product recommendation prompts. The following sections describe the failure scenarios and how each was dealt with.
Invalid Recommendations Based on Made-Up Data
Some or all of the recommended product IDs referenced in the recommendation results were made up by the LLM and did not come from the RAG context.
- I frequently observed that the LLM fabricated results if the list of candidate products was fewer than the requested recommendation count.
- Recommendation results were most stable when the number of candidate products outnumbered the maximum number of recommendations by 2:1
Impure JSON Output
The LLM included free-form text around a JSON document response
- In most cases, the contained JSON document contained valid recommendation results, and thus, we could parse out the JSON document structure from the containing text and ignore the rest
Unexpected JSON Document Structure
The JSON document structure was very stable, but occasionally, the LLM would hallucinate field names or contain array structure.
- The field names might have different capitalization or include different separator characters in the name, like a dash versus an underscore.
- To work around these issues, I added handling for two or more variations of field names that were commonly found.
- The structure of an array containing the product recommendations would sometimes have a different parent hierarchy. Testing the parsed JSON document for its structure and then handling the appropriate response yielded a higher success rate overall.
Chaining LLM Agent Responses With External Reference Data
An added challenge comes from chaining the results of an LLM query to the input of another LLM prompt. The problem is exacerbated when the RAG inputs to prompt 1 generate invalid reference data to prompt 2.
In the case of product recommendations, when executing a CQL search in the Vector database for candidate products (prompt 2), we utilize the set of complementary product categories generated by the LLM (prompt 1) as CQL query constraints in the form of values to the ‘product_type IN (?)’ clause.
It’s possible that the LLM hallucinated the complementary product_type values with slight modifications or possibly values not entirely in the original set of valid values (RAG input). Thus, there might be a discrepancy between a real product type and a product type value generated by the LLM.
One strategy to make the recommendation system more robust to this type of hallucination is to relax the rigidness of the search criteria by implementing Index Analyzers.
Techniques like Stemming can be used to improve the odds of matching real product metadata values with slight variations as a result of LLM hallucinations:
An example of stemming is to allow matching the word ‘Runner’ with ‘Running.’
Example SAI Index Analyzer Configuration: Enable Stemming
CREATE CUSTOM INDEX ON golf_store_embeddings.products(product_type) USING 'org.apache.cassandra.index.sai.StorageAttachedIndex' WITH OPTIONS = {
'index_analyzer': '{
"tokenizer" : {"name" : "standard"},
"filters" : [{"name" : "porterstem"}]
}'};Conclusion
The future of product recommendation systems is brimming with opportunities for personalization and enhanced customer engagement. By integrating AI and natural language processing, we can not only improve the accuracy of these systems but also offer an unprecedented level of customization that can greatly enhance the customer shopping experience.
Stay tuned for my next blog post, where I will discuss in more detail how I leveraged LangStream to implement the recommendation workflows and how the framework provides a secure and scalable solution.
Opinions expressed by DZone contributors are their own.
Comments